初识Spark
1.定义
Apache Spark™ is a fast and general engine for large-scale data processing.
Apache Spark is an open source cluster computing system that aims to make data analytics fast both fast to run and fast to wrtie
2.数据分析栈
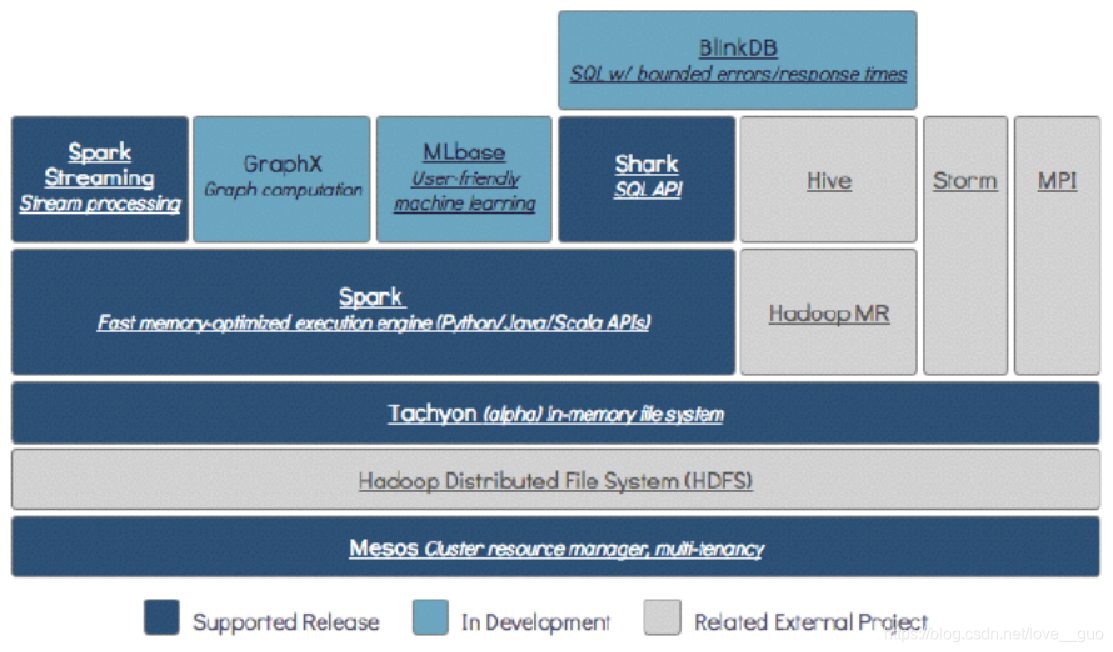
3.一栈式
One stack relu them all!所有大数据的处理场景在Spark中一栈式解决
1.Spark集群与传统集群的比较
| Spark集群 | 传统集群 | |
|---|---|---|
| 批处理 | SparkCore | MapReduce |
| 流处理 | SparkStreaming | Storm |
| 交互式处理 | SparkSQL | Hive |
| 机器学习 | SparkMLlib | mahout |
mahout(机器学习库)主要是为MapReduce服务
2.集群搭建过多带来的问题
1.资源抢夺问题
2.搭建成本高
3.维护成本高
传统集群需要搭建多个集群,而Spark集群只需要搭建一个集群
4.发展历史
1.Spark是美国加州大学伯克利分校的AMP实验室(主要创始人lester和Matei)开发的通用的大数据处理框架
2. 2012年2月发布了0.6.0版本,第一个版本正式发布
5.执行效率
1.MapReduce基于磁盘迭代,不支持内存迭代
2.Spark基于内存迭代,支持磁盘迭代
3.Spark比MapReduce块
6.Spark API
1.Scala和Java
2.Python
3.R
7.运行模式
1.Local模式:多用于测试
2.Standalone
3.yarn
4.Mesos
专业术语
1.任务
| 名称 | 介绍 |
|---|---|
| Application | 用户编写的应用程序 |
| Job | 一个action类算子触发执行的操作 |
| stage | 一组任务,一组任务(task)就是一个stage |
| task(thread) | 在集群中运行时最小的执行单元 |
2.资源、集群
| 名称 | 介绍 |
|---|---|
| Master | 资源管理的主节点 |
| Worker | 资源管理的从节点 |
| Executor | 执行任务的进程 |
| ThreadPool | 线程池,存在于Executor |