版权声明:===========版权所有,可随意转载,欢迎互相交流=========== https://blog.csdn.net/weixin_42446330/article/details/85059243
以下是我的学习笔记,以及总结,如有错误之处请不吝赐教。
FM(factorization machines)表示因子分解机,是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法。目前,被广泛的应用于广告预估模型中,相比LR而言,效果更好。主要目标是:解决数据稀疏的情况下,特征怎样组合的问题,因此该算法主要用于组合特征等特征工程。
原理推倒:(参考1、参考2)
- 模型方程:基本线性回归模型的基础上引入交叉项:

其中:xi,xj表示各特征分量,(ij不相等),但是上式有个问题:对于观察样本中未出现过交互的特征分量,不能对相应的参数进行估计。为克服该缺点,引入辅助变量:
其中k为超参数,将wij改写为: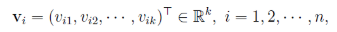
令vi=(vi1,vi2,...,vik)vi=(vi1,vi2,...,vik)。然后,利用vivTjvivjT对交叉项的系数ωijωij进行估计: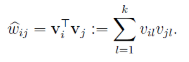
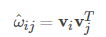
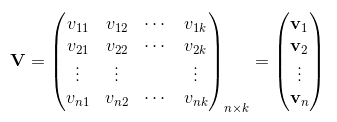
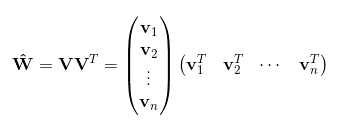
于是得到最终模型为:
- 计算复杂度:模型需要估计的参数包括:
共有1+n+nk个,那么计算复杂度为: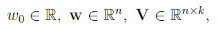
利用:((a+b+c)2−a2−b2−c2)/2((a+b+c)2−a2−b2−c2)/2求出交叉项,对上式第二项进行简化: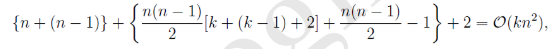
因此其时间复杂度降至O(kn):
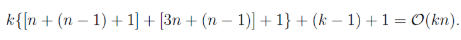
- 损失函数:
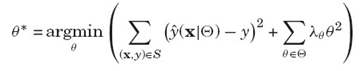
- 优化函数:主要有随机梯度下降(SGD)、交替最小二乘(ALS)、马尔科夫链蒙特卡罗法(MCMC),下面主要讲交替最小二乘法(也称坐标下降法),基本思路是每次只对一个参数进行优化,并逐轮迭代:
通过求其解析解得到:
引入残差进行计算: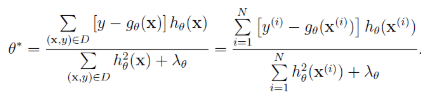
得到最终结果:
- 特点:与SGD相比,每次参数更新依赖上一轮所有的参数计算模型的残差:
 没有学习速率参数,每次更新时,内存需要load所有参数。
没有学习速率参数,每次更新时,内存需要load所有参数。 - 优化方法比较:

- 与多项式回归的对比:
区别在于:当观测数据非常稀疏的情况下,FM依然能够估计出pairwise interactions,因为pairwise的权重是k维因子向量的乘积,而多项式回归的pairwise的权重假设是相互独立的。
案例代码:
from pyfm import pylibfm
from sklearn.feature_extraction import DictVectorizer
import numpy as np
train = [
{"user": "1", "item": "5", "age": 19},
{"user": "2", "item": "43", "age": 33},
{"user": "3", "item": "20", "age": 55},
{"user": "4", "item": "10", "age": 20},
]
v = DictVectorizer()
X = v.fit_transform(train)
print(X.toarray())
y = np.repeat(1.0,X.shape[0])
fm = pylibfm.FM( num_iter=10)
fm.fit(X,y)输出:

fm.predict(v.transform({"user": "1", "item": "10", "age": 24}))输出:![]()
To be continue......