版权声明:===========版权所有,可随意转载,欢迎互相交流=========== https://blog.csdn.net/weixin_42446330/article/details/84669527
以下是我的学习笔记,以及总结,如有错误之处请不吝赐教。
基础知识:
- 主题模型:简单来说就是由文档生成相应的主题,它可以将⽂文档集中每篇⽂文档的主题按照概率分布的形式,类似下图这样:

- 贝叶斯模型:贝叶斯公式大家都知道,不知道的可以出门左转:ml课程:概率图模型—贝叶斯网络、隐马尔可夫模型相关(含代码实现),贝叶斯模型就是运用贝叶斯公式得到的一种主题模型。
- 共轭分布与共轭先验:后验概率(posterior probability)∝ 似然函数(likelyhood function)*先验概率(prior probability),类似这种形式相似的分布就叫做共轭分布。
- Gamma函数:阶乘在实数上的推广,对于整数⽽而⾔:
对于实数: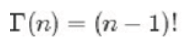
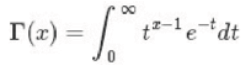
- 二项分布(Binomial distribution):是从伯努利分布推进的,伯努利分布:又称两点分布或0-1分布,是一个离散型的随机分布,其中的随机变量只有两类取值,非正即负{+,-}。而二项分布即n次的伯努利试验,简言之,只做⼀次实验,是伯努利分布,重复做n次,是二项分布。二项分布的概率函数为:
多项式分布,是二项分布扩展到多维的情况,多项分布是指单次试验中的随机变量的取值不在是0-1的,而是有多种离散值可能(1,2,3...,k)。⽐如投6个面的骰子实N次实验结果服从K=6的多项分布。当然他们加起来的P应该是等于1的。多项分布的概率密度函数为:
Beta分布,二项分布的共轭先验分布,给定参数a>0和b>0,取值范围为[0,1]的随机变量 x 的概率密度函数:
其中: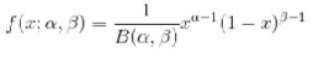
Dirichlet狄利克雷分布,是beta分布在高维度上的推广:
其中:

- Gibbs Sampling:是每次选取概率向量的一个维度,给定其他维度的变量值采样当前维度的值,不断迭代,直到输出待估计的参数:
- 初始时随机给文本中的每个单词分配主题z(0),然后统计每个主题z下出现term t的数量以及每个文档m下出现主题z中的词的数量,每一轮计算p(zi|z-i,d,w),即排除当前词的主题分配:根据其他所有词的主题分配估计当前词分配各个主题的概率。当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词采样一个新的主题。然后用同样的方法不断更新下一个词的主题,直到发现每个文档下Topic分布θ和每个Topic下词的分布φ收敛,算法停止,输出待估计的参数θ和φ,最终每个单词的主题zmn也同时得出。
- 实际应用中会设置最大迭代次数。每一次计算p(zi|z-i,d,w)的公式称为Gibbs updating rule:

LDA算法:
- 定义:LDA(Latent Dirichlet Allocation)隐含狄利克雷分布,是一种无监督的贝叶斯模型,在训练时不不需要手⼯工标注的训练集,需要的仅仅是文档集以及指定主题的数量K即可;此外LDA的另一个优点是:对于每一个主题均可找到一些词语来描述它;是一种典型的词袋模型,即认为一篇文档是由一组词构成的一个集合,词语词之间没有顺讯以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成;
- 生成过程(generative process)简版:
- 对每一篇⽂文档,从主题分布中抽取一个主题;
- 从上述被抽到的主题所对应的单词分布中抽取一个单词;
- 重复上述过程直⾄至遍历⽂文档中的每一个。
- 生成过程(generative process)标准版:
- 假定w代表单词;d代表文档;t代表主题;大写代表总集合,小写代表个体;
- D中每个文档d看作一个单词序<w1,w2,...,wn>,wi表示第i个单词。
- D中涉及的所有不同单词组成一个词汇表⼤V (vocabulary),LDA以文档集D作为输⼊入,希望训练出的两个结果向量(假设k个topic,V中一共m个词);
- 对每个D中的文档d,对应到不同Topic的概率θd<pt1,...,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
- 对每个T中的topic,生成不同单词的φt<pw1,...,pwm>,其中,pwi表示t⽣成V中第i个单词的概率。计算方法同样很直观pwi=Nwi/N,其中Nwi表示对应到topic的V中第i个单词的数目,N表示所有对应到topic的单词总数。
- 所以,LDA的核心公式如下:

- 直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了了档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利利φt计算得到。利用当前θd和φt,我们可以为一个文档中的一个单词计算它意一Topic时的p(w|d),然后根据这些结果来更新这个词应该对应topic。然后,如果这个更新改变了这个单词所对Topic,就会反过来影响θd和φt。
- 学习过程标准版:
- 先随机地给θd和φt赋值(对所有的d和t);
- 针对一个特定的⽂档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:Pj(wi | ds)=P(wi | tj)*P(tj | ds);
- 现在我们可以枚举T中的topic,得到所有的pj(wi | ds)。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi | ds)最⼤的tj(注意,这个式子里只有j是变量);
- 然后,如果ds中的第i个单词wi在这里选择了一个与原topic(也就是说,这个时候i在遍历ds中所有的单词,⽽tj理当不变),就θd和φt有影响了。它们的影响又会反过来影响对上面p(w | d)的计算。对D中所有的d中的所有w进行一次p(w | d)的计算并重新选择topic看作一次迭代。这样进n次循环迭代之后,就会收敛到LDA所需要的结果了。
- 公式版:下面几个概念在基础部分已经给大家简单介绍了,两个模型具体往下看:
- 一个函数:gamma函数;
- 四个分布:二项分布、多项分布beta分布、Dirichlet分布;
- 一个概念和一个理念:共轭先验和贝叶斯框架;
- 两个模型:pLSA、LDA;
- 一个采样:Gibbs采样
几种主题模型:
- Unigram model:对于文档W=(w1,w2......,wn),用p(wn)表示词wn的先验概率,生成文档w的概率为:
用图可以表示为:

- Mixture of unigrams model:该模型的生成过程是:给某个文档先选择一个主题z,再根据该主题生成文档,该文档中的所有词都来自一个主题。假设z1,z2,z3,...zk,生成文档的概率为:
用图表示为:

- PLSA模型:刚刚的mix unigram模型里面,一篇文章只给了一个主题。但现实中一篇文章可能有多个主题,只不过是出现的几率不一样,我们定义:
- P(di)表示海量文档中某篇文档被选中的概率;
- P(wj|di)表示词wj在给定文档di中出现的概率,(即对所有文档进行分词后,得到一个词汇列表,每篇文档就是一个词语的集合。对于每个词语,用他在文档中出现的次数除以文档中词语总的数目就是P(wj|di));
- P(zk|di)表示具体某个主题zk在给定文档di下出现的概率。
- P(wj|zk)表示具体某个词wj在给定主题zk下出现的概率,与主题越密切的词,其条件概率P(wj|zk)越大。
我们通过观测,得到了知道主题是什么,我就用什什么单词的文本生成模式,根据贝叶斯定律律,就可以反过来推出看⻅见用了什什么单词,我就知道主题是什么。
- 从而可以根据大量已知的文档-词项信息P(wj|di),训练出文档-主题P(zk,di)和主题-词项P(wj|zk),如下公式所示:

- 得到文档中每个词的生成概率为:

- 由于P(di)可事先计算求出,而P(wj|zk)和P(zk|di)未知,所以
=(P(wj|zk),P(zk|di))就是我们要估计的参数,就是最大化
- PLSA与LDA对比:两者本质区别就在于它们去估计未知参数所采用的思想不同,前者用的是频率派思想,后者用的是贝叶斯派思想,具体如下图:

具体手撸LDA代码及相关案例代码,欢迎关注:我的github
To be continue......