文章目录
Large Margin Classification
Optimization objective
在逻辑回归中,z对应的
的值
在支持向量机中,把log函数换为图中蓝色线所代表的cost函数

支持向量机中的代价函数

Large Margin Intuition
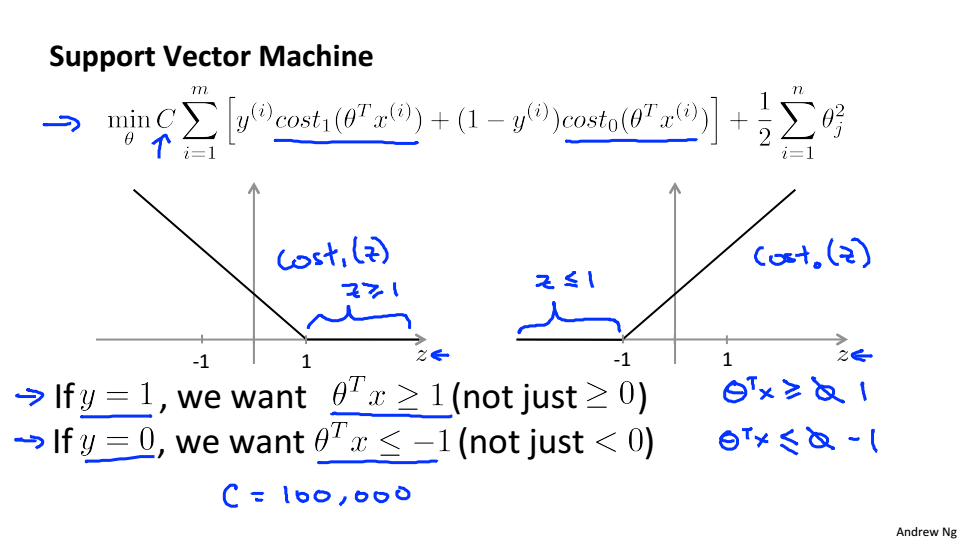
假设C=100000,我们就希望蓝色款中的式子等于0
当y=1时为了使得
,
当y=0时为了使得
,

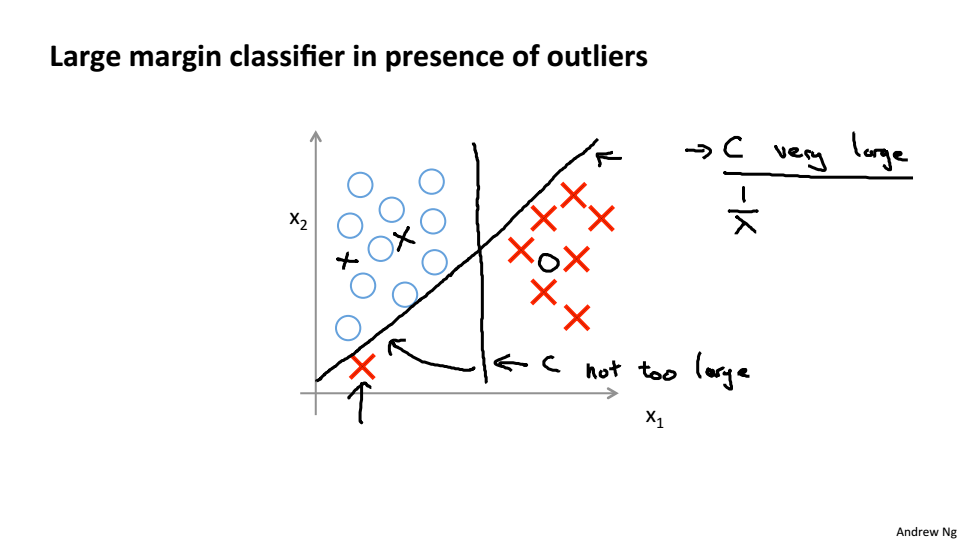
SVM会寻找最大的间距分离样本,这也是SVM具有鲁棒性的原因

当C非常大的时候,容易受到噪点的影响,当C不是很大的时候就会忽略掉噪点
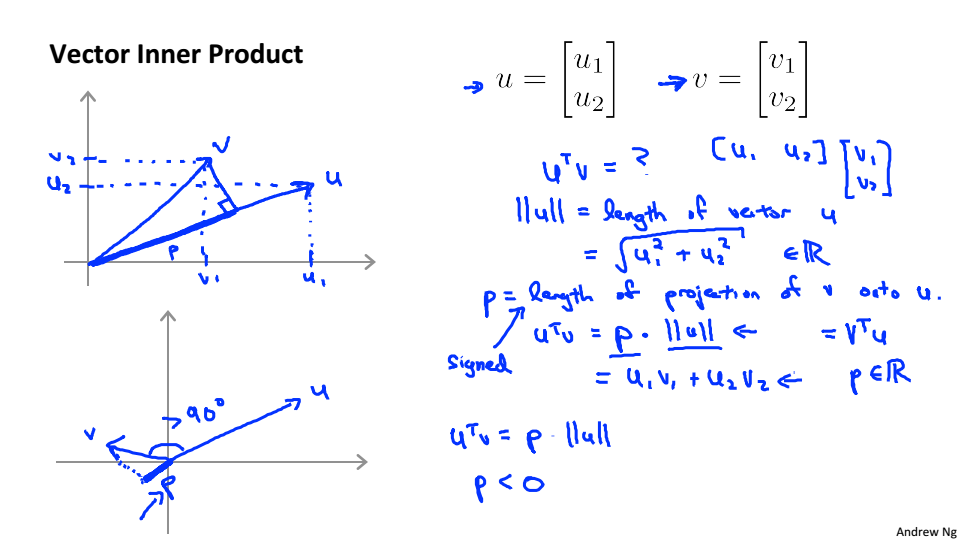
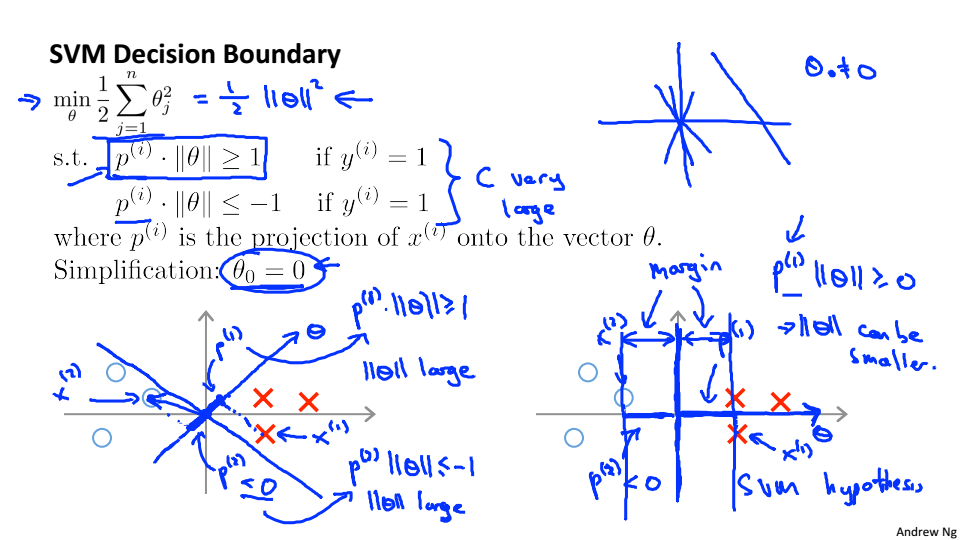
Mathematics Behind Large Margin Classification
SVM中的数学理论
假设只有两个特征
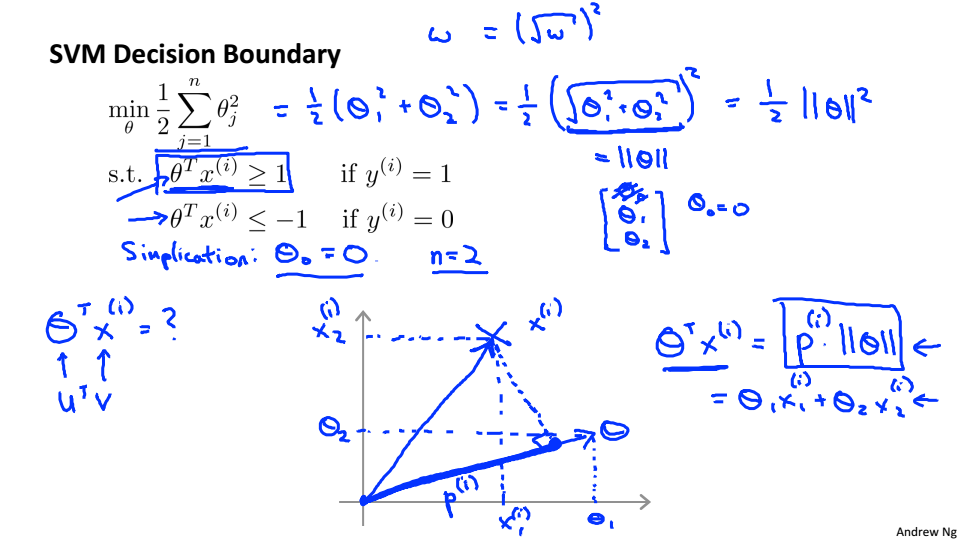
假设
简化情况,使得分界线经过(0,0)
假设选择左图中的分界线,当
很小是,只有当
很大时
才能大于等于1,所以这不是一个很好的参数
右边的图中
就会大很多,所以
就可以变小
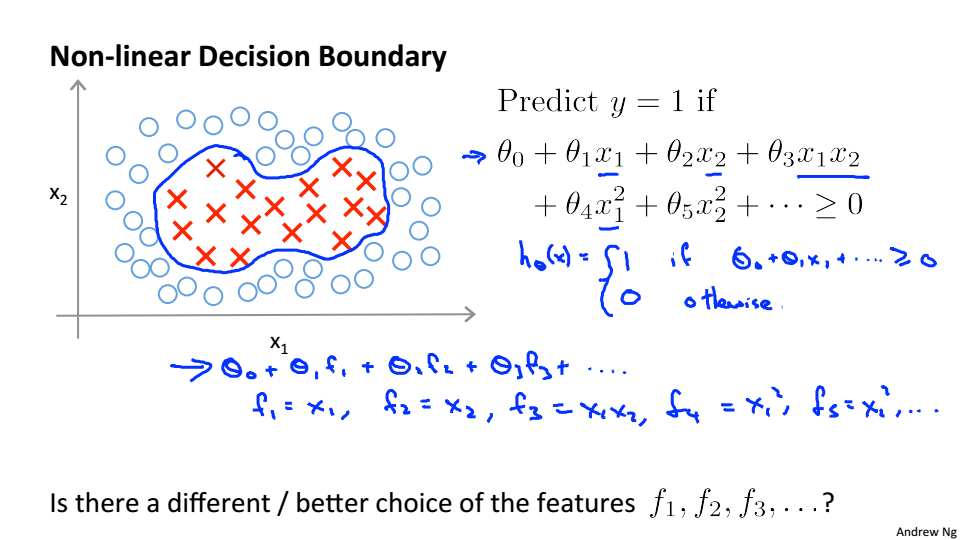
Kernels
为了构造复杂的非线性分类器,使用kernels(核函数)来达到目的
进行多项式回归时,需要构建多项式,引入核函数就是为了构建多项式
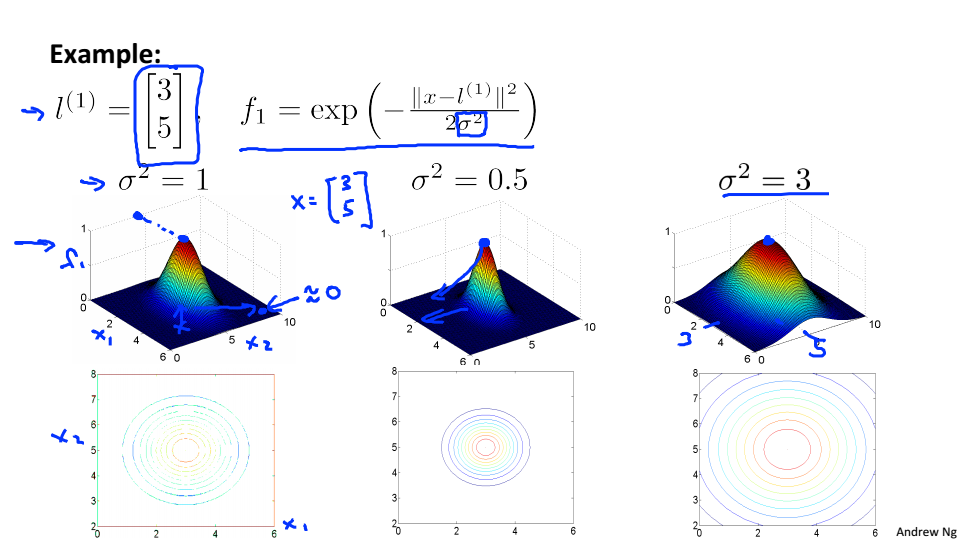
选取三个landmark点,给定x计算f

当x接近
时
当x离
较远时
,f度量的是x到l的相似度,越相似f越接近于1

不同
下f的图
越大f下降的速度越慢,越小f下降的速度越快

如何选取landmark
将数据集中所有的x作为landmark,这样特征数量就会变为m+1


SVM中的参数选择

SVMs in Practice
如何使用SVM
在使用核函数之前需要对特征进行归一化处理

SVM中的多分类,与逻辑回归中的多分类一样,有几类就训练几个SVM

逻辑回归和SVM对比
