背景
作为一个计算机基础薄弱的电气工程师,廖大的教程看到常用的内建模块时,看的头大,特别是看到HTMLParser时,已宛如天书了。这时作为一个初学者的劣势就暴露出来了,我不知道哪部分知识是理解这些模块的前置条件,即使知道是哪部分知识,但不知道该理解到什么程度才能解决当前的问题。个人建议是,把这个难题就当成一个工具,会使用,能解决当前的问题就好。不必知道其更多的用法,甚至其背后的实现细节,以及其代表的另一个领域的知识。就像学习开车,先学会打火,转方向盘,能让车子动起来就好,不必知道道路规则,更不必知道制造车子的工艺,以及其背后的物理原理。
闲话少说,这时想到,之前看过小甲鱼出的一套0基础的Python视频教程,针对的是初学者。于是,暂时战略性放弃了廖大的教程,转投小甲鱼的怀抱。小甲鱼确实讲的通俗易懂,而且由于是视频,其传递的信息量要比文字教程大多了,细节方面更详细。看到《056 论一只爬虫的自我修养4:OOXX》时,抄写小甲鱼的代码,并不能成功运行。抓取的html源码里并没有图片的地址,我一直以为是我的源码有问题。后来咨询了一个写python的朋友,他给了我一个验证源码是不是有问题的办法,并推测有可能是动态网页的原因。
动态网页???第一次听到这个概念,于是开始查怎么用python抓取动态网页的元素。查到这篇文章爬取煎蛋网的妹子图,源码有些问题,但是其提供的思路是对的,用python+selenium+chromedriver的技术路线抓取网页的html源码,中间又踩了一些坑,但最终还是成功了。
源码与测试
事先要分析url的构成规律,以及图片元素的存储规律,详情参考小甲鱼的视频。
# -*- coding:utf-8 -*-
# 2018/12/10
# author:zxq
import urllib.request
import re,os
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
# 下载煎蛋网page_number页前的所有图片
s = r'img src=\"(.+(jpg|gif))' # 正则表达式,匹配html源文件中的jpg,gif等图片的链接,注意:这里将图片的地址列成了一个group
re_html = re.compile(s) # 预编译,提高效率
# 利用selenium+chromedriver+beautifulSoup4,解析动态网页的html
def getPage(url):
chrome_options = Options()
chrome_options.add_argument('--headless') # 浏览器不提供可视化界面
chrome_options.add_argument('--disable-gpu') # 需要加上这个属性来规避bug
driver = webdriver.Chrome(chrome_options = chrome_options,executable_path=r'D:\Chromedriver\chromedriver.exe') # D:\Chromedriver\chromedriver.exe是chromedriver的本地安装路径
driver.get(url) # 打开网址
html = driver.page_source
html_source = BeautifulSoup(html, 'html.parser') # 'html.parser'是python内置标准库,前置条件,了解HTML的语法
return html_source
# 利用findall函数返回图片链接地址的list
def getList(html_source):
pic_list = re_html.findall(str(html_source))
return pic_list # 返回list
# 根据图片的链接将图片下载到本地
def download_pic(url,format,name):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36')
response = urllib.request.urlopen(req)
mm_img = response.read()
with open(name + '.' + format,'wb') as f:
f.write(mm_img)
def save_imgs(folder, page_number):
if(os.path.exists(folder) == False):
os.mkdir(folder) # 创建一个名为mm_pic的文件夹
os.chdir(folder) # 切换到mm_pic文件夹下
urlbase = 'http://jandan.net/ooxx/' # 网站地址
for i in range(3,page_number):
url = urlbase + 'page-' + str(i) + '#comments'
html_source = getPage(url)
list = getList(html_source)
for j in range(list.__len__()):
download_pic(list[j][0],list[j][1],str(i)+'-'+str(j))
print('OK')
if __name__ == '__main__':
save_imgs('mm_pic',55)
最终抓取的图片列表(然鹅并没有什么美女图):

坑与疑点解析
- 用urllib.request.urlopen()取到的html地址中不包含.jpg的链接
利用Chrome的开发者工具查看网页的源码,选中图片,可以看到图片的的链接:

但是利用urllib.request.urlopen()抓取到的html源码中根本不包含.jpg的相关字符串:
源码如下:
# -*- coding:utf-8 -*-
# 2018/12/10
# author:zxq
import urllib.request
import re,os
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
# 下载煎蛋网page_number页前的所有图片
s = r'img src=\"(.+(jpg|gif))' # 正则表达式,匹配html源文件中的jpg,gif等图片的链接,注意:这里将图片的地址列成了一个group
re_html = re.compile(s) # 预编译,提高效率
# 利用selenium+chromedriver+beautifulSoup4,解析动态网页的html
def getPage(url):
chrome_options = Options()
chrome_options.add_argument('--headless') # 浏览器不提供可视化界面
chrome_options.add_argument('--disable-gpu') # 需要加上这个属性来规避bug
driver = webdriver.Chrome(chrome_options = chrome_options,executable_path=r'D:\Chromedriver\chromedriver.exe') # D:\Chromedriver\chromedriver.exe是chromedriver的本地安装路径
driver.get(url) # 打开网址
html = driver.page_source
html_source = BeautifulSoup(html, 'html.parser') # 'html.parser'是python内置标准库,前置条件,了解HTML的语法
return html_source
# 利用findall函数返回图片链接地址的list
def getList(html_source):
pic_list = re_html.findall(str(html_source))
return pic_list # 返回list
# 根据图片的链接将图片下载到本地
def download_pic(url,format,name):
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
cat_img = response.read()
with open(name + '.' + format,'wb') as f:
f.write(cat_img)
def save_imgs(folder, page_number):
if(os.path.exists(folder) == False):
os.mkdir(folder) # 创建一个名为mm_pic的文件夹
os.chdir(folder) # 切换到mm_pic文件夹下
urlbase = 'http://jandan.net/ooxx/' # 网站地址
url = urlbase + 'page-' + str(55) + '#comments'
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36')
source = urllib.request.urlopen(req)
url_source = source.read().decode('utf-8')
print('Status:', source.status, source.reason)
print(url_source)
print('OK')
if __name__ == '__main__':
save_imgs('mm_pic',55)
结果中并没有包含jpg的字符串。

一度以为源码有问题。于是咨询了写Python的朋友,他给了两个判断方法:
1. 查看网页返回的status与reason;
2. 查看调试工具下的response。
status与reason的状态如下:
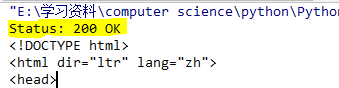
在response中查看网页的html源码,才发现也不包含jpg字段。

于是猜测有可能是动态网页的原因。
- chrome_options.add_argument(’–headless’) ,chrome_options.add_argument(’–disable-gpu’) 这两句的含义是什么?
参考地址:python+selenium+chrome的一些备忘

- 正则表达式
在线测试网址:正则表达式在线工具
廖大的正则表达式讲解 - bs4使用方法
bs4官方文档
几个解析器的对比:

还需要了解的知识
- HTML语法
- 正则表达式
- 其他爬取图片的方式