python爬虫自己玩:用一个python小爬虫在网上抓取之间想要的小说
本文采取的集成开发软件pycharm,面向对象开发,属于菜鸟教程,只需仔细看文章与代码,便可做出来。话不多说,直接上教程
每一步后面都附上了源码,如果需要总的.py文件,将邮箱评论出来或者加qq:1284309379
总起:
本文是我在网上学习之后,通过自己的理解将所有代码敲出来,一步步完善的。肯定不是最完美的,很多地方可以再丰富,比如书名可以用一个GUI界面展示,这样就可以完善成一个小程序了,但是那样用的知识面又多了一个。既然是菜鸟教程,就不弄的花里胡哨的了。
首先既然是python面向对象编程,那我们就先将面向对象编程的框架弄好:
import re
import requests
from requests import RequestException
def get_page(url):
#以浏览器访问来修饰网址
pass
def get_list(page):
#获取所有小说网址以及书名
pass
def get_chapter(novel_url):
#获取已选择小说,章节链接以及目录
pass
def get_content(chapter):
#获取小说所有章节内容并传入txt文件
write_tofile(chapter_content, chapter[1])
pass
def write_tofile(chapter_content, chapter_name):
pass
if __name__ == '__main__':
url = 'http://www.xbiquge.la/xiaoshuodaquan/'
page = get_page(url)
novel_list = get_list(page)
name = '斗罗大陆4终极斗罗'
for item in novel_list:
if item[1] == name:
novel_chapter = get_chapter(item[0])
for chapter in novel_chapter:
get_content(chapter)
首先,我们要把准备工作做好
第一步,先把本次所需要的库requests安装上,python环境变量配置好的情况下,可以直接用windows+r键调出控制面板,输入cmd,再输入以下代码
pip install requests
等待下载完成即可,或者可以在pycharm中直接下载requests包:链接:pycharm中下载包
第二步,打开pycharm并导入我们需要的包
import re
import requests
from requests import RequestException
然后,我们开始分析需求
第一步:现在很多网站都有反爬机制,导致直接的python爬虫无法爬取,那我们该怎么办呢?那我们就将我们的爬虫伪装一下,伪装成我们是在用浏览器访问这个网页就可以从中爬取到我们想要的东西了。很多人会说这样的话网站的反爬机制不就没用了,其实不然,这招是可以阻挡很多新手的。
接下来我们就直接用代码给我们的爬虫“换头”,win10自带的浏览器可以在网页直接按F2,QQ浏览器右键点击检查。在新出的页面上目录上找到并点击NetWork,再随便找一个以.css结尾的文件点击,找到User-Agent将内容复制出来,具体界面如下所示
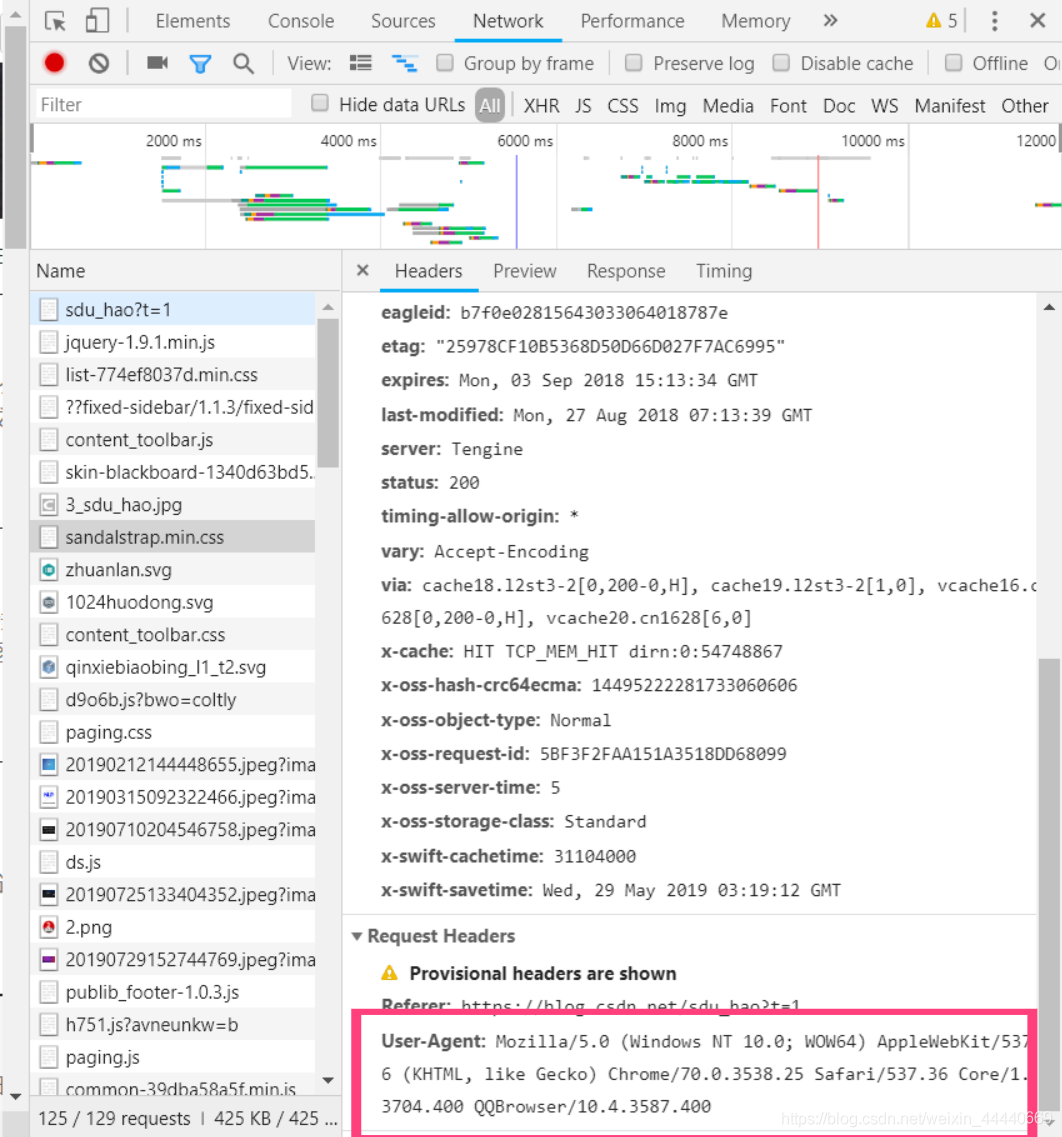
找到了User-Agent,接下来就是将爬虫的headers换成浏览器浏览模式,再将网页的源码全部提取下来。具体代码如下所示:
def get_page(url):
#以浏览器访问来修饰网址
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text else:
return None
except RequestException:
return None
第二步:我们已经伪装成浏览器,并将网址源码全部抓取下来了,接下来就是爬虫最重要的事,去网页看源码,找出正确的正则表达式:
先给出原网址:http://www.xbiquge.la/xiaoshuodaquan/
在网址右键点击空白,然后查看源代码

'''
可以看出每本书的链接和书名是由
<li><a href="(链接)">(书名)</a></li>
这样一个固定形式来写入的,那么我们需要做的事就是将每本书
的链接网址以及书名给摘出来
'''
具体代码如下所示:需要传入参数:笔趣阁的首页的网址page
再根据我说的需要将正则表达式书写出来,用re.compile()方法先将正则表达式转换成模式对象,再调用findall()方法将网页源码中所有符合正则表达式的对象抓取出来返回一个列表,列表每个元素是一个元组:(链接,书名)。仔细分析抓取出来的list列表可以发现前10个元组是与需求无关的,所以不需要返回。
def get_list(page):
#获取所有小说网址以及书名
pat = '<li><a href="(.*?)">(.*?)</a></li>'
list = re.compile(pat).findall(page)
return list[10:]
第三步:每个小说链接以及名字都已经爬到手了,接下来就是匹配我们自己需要的那部小说
需要传入参数:以及比对好的小说的网址
先将小说网址进行修饰,先点开你需要爬取的小说的目录,继续分析网站源码

发现所有目录名称与链接也是有规律的:
<dd><a href ='(网址)' >(目录名称)</a></dd>
一样的,开始写正则表达式将链接网址和目录名称爬取出来,然后返回一个对象:(这个地方抓取的时候网速不好的话特别容易崩盘,所以将它放在了try语句里面)
def get_chapter(novel_url):
#获取已选择小说,章节链接以及目录
try:
html = get_page(novel_url)
pat = "<dd><a href='(.*?)' >(.*?)</a></dd>"
chapters = re.compile(pat).findall(html)
return chapters
except:
print("该章节抓取失败")
第四步:通过第三步,我们已经将目录的链接爬到手了,而这一步就是整篇最重要的一步,就是将小说的正文爬到手。
先将目录的链接修饰完整,再一样用get_page()方法将爬虫修饰一下。
再就是分析网页源码,可以很清楚的看到所有正文都夹在这么一个html语言下面
<div id="content">正文<p>
找到了规则,接下来就是写正则表达式,将正文爬出来。

具体实现源代码如下:
def get_content(chapter):
#获取小说所有章节内容并传入txt文件
chapter_url = 'http://www.xbiquge.la' + chapter[0]
html = get_page(chapter_url)
pat = '<div id="content">(.*?)<p>'
chapter_content = re.compile(pat).findall(html)
write_tofile(chapter_content, chapter[1])
第五步:最后一步了,正文已经提取出来,接下将爬到的正文去除不要的东西,一个文件操作就ok啦。
输入参数:章节名称以及正文
先将正文多余的东西用string的默认方法str.replace()移除,再进行保存
保存到txt文件的时候一定要以追加的方式保存
代码如下:
def write_tofile(chapter_content, chapter_name):
for content in chapter_content:
#去掉空格和换行符号
print(chapter_name)
content = content.replace(" ", "").replace("<br />", "")
with open('斗罗大陆4终极斗罗.txt', 'a', encoding='utf-8') as f:
f.write(chapter_name+'\n\n\n\n'+content+'\n\n\n\n\n\n\n')
附加:上面是将所有章节保存到一个txt文件,还有一个形式是创建一个文件夹将所有爬取得到的每个章节分别用一个个txt文件保存下来。
这样保存的话就得导入os库
import os
def write_tofile(chapter_content, chapter_name):
if not os.path.exists(name):
os.mkdir(name)
for content in chapter_content:
# 去掉空格和换行符
content = content.replace(" ", "").replace("<br />", "")
with open('斗罗大陆4终极斗罗‘ + '\{}.txt'.format(chapter_name), 'w', encoding='utf-8') as f:
f.write(content)
第六步:
用python的面向对象编程的形式将代码封装起来,并将主函数写出来
if __name__ == '__main__':
url = 'http://www.xbiquge.la/xiaoshuodaquan/'
page = get_page(url)
novel_list = get_list(page)
print(novel_list)
name = '斗罗大陆4终极斗罗'
for item in novel_list:
if item[1] == name:
novel_chapter = get_chapter(item[0])
for chapter in novel_chapter:
get_content(chapter)
总结
到此,这个python的小爬虫就做完了,效果如图所示,可以看到小说以及完全爬取出来了。400多章,这样以后是不是就可以直接爬小说,不用幸苦找资源了呢(手动滑稽)。
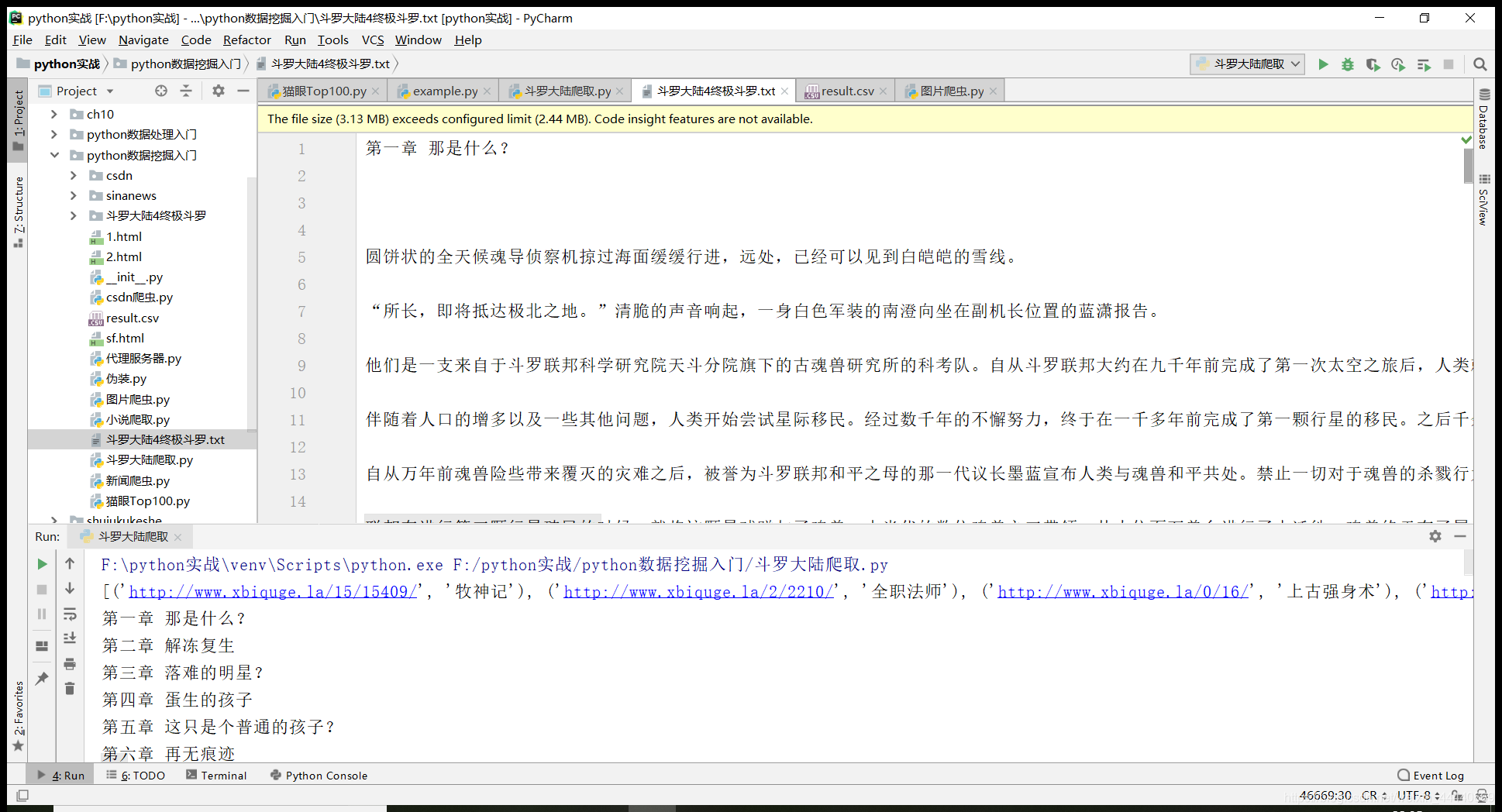
总的来说,这只是一个小爬虫,但是却是爬虫入门一次很重要的锻炼,可以用自己的方式爬到自己想要的东西,多美好。