第一个python程序:爬虫下载课件
任务:爬取学校网站中自己课程列表里老师上传的课件
思路:我们使用模拟用户操作的方式,使用火狐浏览器来帮助程序运行selenium webdriver
火狐浏览器驱动
我们要使用selenium webdriver来启动火狐浏览器,则需要下载驱动geckodriver.exe
下载地址:https://github.com/mozilla/geckodriver/releases/注意版本问题
下载、解压,将geckodriver.exe放到和python.exe同一个文件中(很多这部分异常问题都是版本问题、环境变量问题等)

登录
分析源代码,找到登录框中“用户名”、“密码”、“登录按钮”的位置


获得网页源代码
利用BeautifulSoup、正则表达式等来定位元素
模拟键盘点击
因为点击下载链接后会弹出弹窗,但是这个弹窗是没办法解析的,只能通过模拟键盘来点击按钮


这一部分因为不同的文件下载出现的情况不同,
例如pdf会直接在页面显示出来,而右上角会有下载的按钮,网页显示的pdf是可以解析的,所以定位到按钮,click点击后才弹出弹窗
例如压缩包会直接弹出弹窗
而某些文件打开会是网页乱码,这样的情况回退就可以了
安装相关包
- selenium等包直接pip install 安装就好了
- pykeyboard安装
但是pykeyboard包不能直接安装
需要先安装pywin32和pyHook
而pyHook直接安装也不行
首先查看自己的python版本
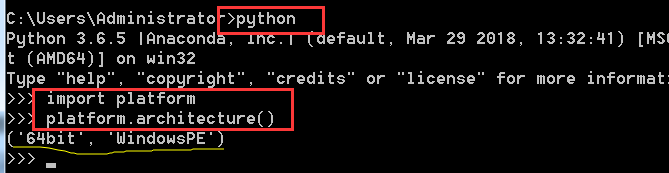
去https://www.lfd.uci.edu/~gohlke/pythonlibs/下载对应的包

再pip install安装

而pykeyboard和pymouse一起集成到了PyUserInput库中,所以我们安装pykeyboard需要安装***PyUserInput***使用pip install PyUserInput 安装
所用到的包
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.common.exceptions import NoSuchElementException
import re
import time
from pykeyboard import PyKeyboard
分析网页循环下载部分
soup1 = BeautifulSoup(driver.page_source, "html.parser") # 多模式首页
course = soup1.find('div', attrs={"class": "userCourseList"}) #定位到课程列表
course_url = course.find_all('a', href=True)
# 得到课程ID
course_id = re.findall('<a href="/iclass/netclass/course/index.php\?cid=(.*?)">', str(course_url))
for C_id in course_id:
print(C_id)
driver.find_element_by_xpath('//a[@href = "/iclass/netclass/course/index.php?cid='+ C_id +'"]').click() # 打开课程链接
driver.find_element_by_id('CLDOC').click() # 打开资料下载区
soup2 = BeautifulSoup(driver.page_source,"html.parser") #某课程资料下载区界面
pdf = soup2.find_all('a', attrs={"class": " item"}) # 定位到课件的位置
# 得到课件的id
pdf_id = re.findall('<a class=" item" href="/iclass/netclass/backends/download.php\?url=(.*?)&',str(pdf))
if pdf_id:
for P_id in pdf_id:
pdf_name = driver.find_element_by_xpath('//a[@href = "/iclass/netclass/backends/download.php?url=' + P_id + '&cidReset=true&cidReq=' + C_id + '"]').text # 找到课件名称
driver.find_element_by_link_text(pdf_name).click() # 点击PDF
try:
driver.find_element_by_id('download').click() # 下载(只有pdf的课件才会打开有download按钮)
# 键盘操作
except NoSuchElementException:
k = PyKeyboard()
k.press_key(k.alt_key) # 按住ALT键
k.tap_key('s') # 点击S键
k.release_key(k.alt_key)
k.tap_key(k.enter_key) # enter键完成保存工作
print(pdf_name)
else:
k = PyKeyboard()
time.sleep(1)
k.tap_key(k.alt_key) #按住ALT键
k.tap_key(k.enter_key) # enter键完成保存工作
print(pdf_name)
driver.back() #回退到课件列表界面
driver.back()
driver.back()
driver.back() # 一直回退到课程列表界面,就算back多也只会停留在登录后的界面
else:
driver.back()
driver.back()#回到课程列表
continue
driver.close()
可优化
多增加异常处理
不要下载已经下载过的课件
总结
分析网页定位元素是一件特别累的事
soup.find
soup.findall
soup.find_all
re.find_all
re.findall
re.find
之间的区别、条件格式还不是很清楚
以及和text之间的关系,如何获得标签之间的文字,在这一部分经常要试错很多次
这是我的第一篇博客,写得自己都不够满意却又不知道如何修改了
这个程序已经完成很久了,但是又做一遍的时候还是会有一些问题
计算机这条路不知道能走多久,可能毕业了就离开了
有些时候觉得自己很爱它,特别是完成一些小功能时,但是这种时候真的太少了,十分没有信心
还是勉励一下自己,还有一些时间,还不算晚
纯粹一些,坚定一点!加油!