本文章主要介绍爬取美团结婚栏目所有商家信息(电话)
第一步:爬取区域
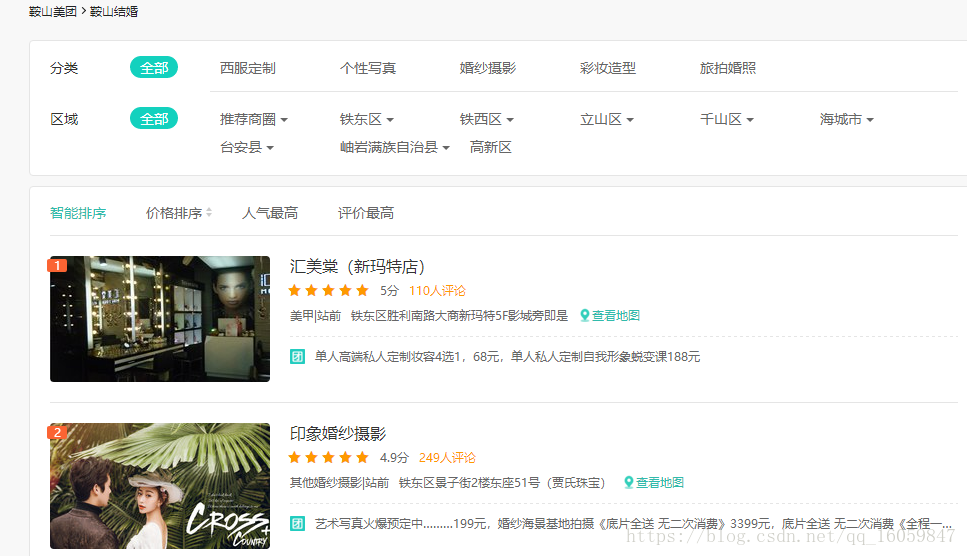
分析鞍山结婚页面
https://as.meituan.com/jiehun/
分析重庆结婚页面
https://cq.meituan.com/jiehun/
分析可得:url基本相同,我们只需爬取美团的选择城市,然后构建我们的url,即可爬取所有区域的结婚信息
主要实现代码:
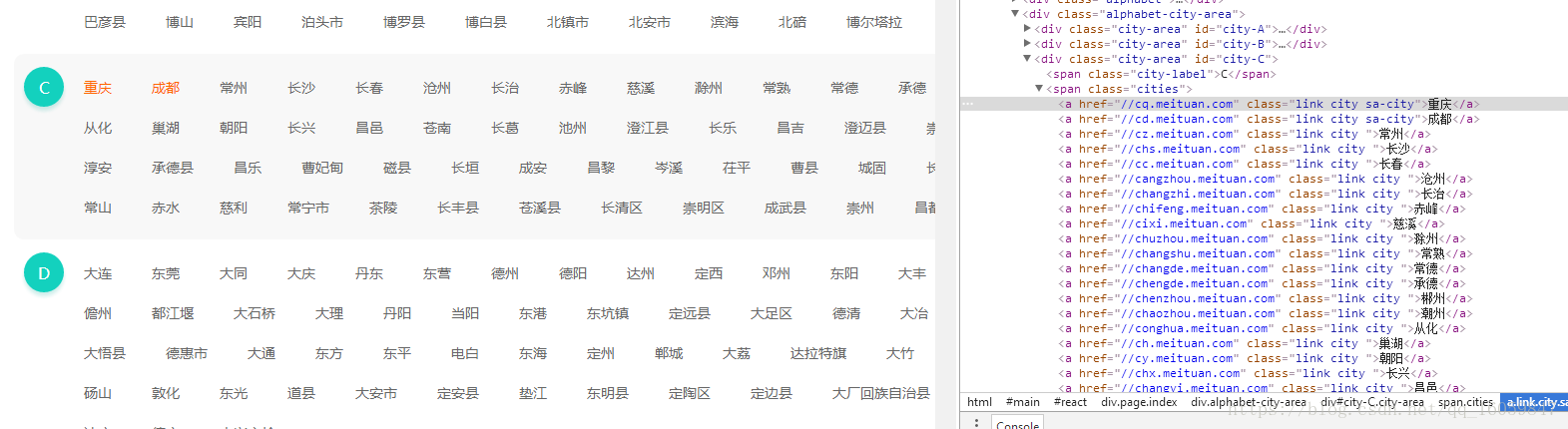
def find_all_citys():
response = requests.get('http://www.meituan.com/changecity/')
if response.status_code == 200:
results = []
soup = BeautifulSoup(response.text,'html.parser')
links = soup.select('.alphabet-city-area a')
for link in links:
temp = {
'href' : link.get('href'),
'name' : link.get_text().strip(),
}
results.append(temp)
return results
else:
return None第二步:构建完所有的url后,爬取每个url的列表信息
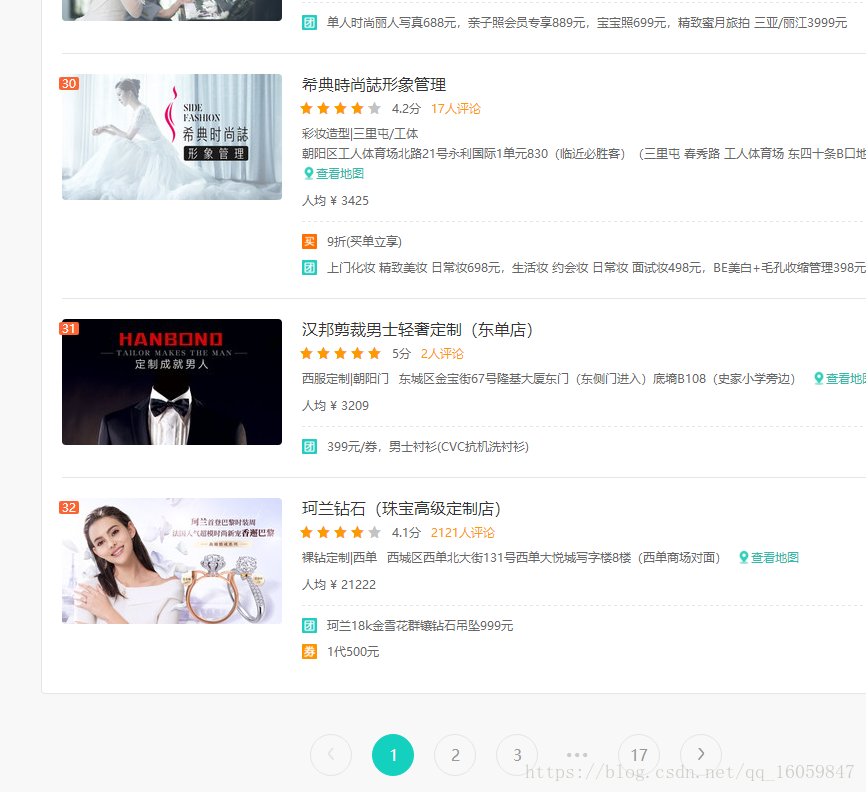
每个区域url最多32页,爬取每个商家,直到列表数据为空
主要代码如下:
for page in range(1,32):
print("*" *30)
url = need['url'] + 'pn' + str(page) +'/'
# url = 'https://jingzhou.meituan.com/jiehun/b16269/pn1/'
headers = requests_headers()
print(url+"开始抓取")
response = requests.get(url, headers=headers, timeout = 10)
# , allow_redirects=False
# if response.status_code == 302 or response.status_code == 301:
# raise Exception("30*跳转")
pattern = re.compile('"errorMsg":"(\d*?)"',re.S)
h_code = re.findall(pattern, response.text)
if len(h_code) != 0 and h_code[0] == '403':
raise Exception("403:错误信息:<!-- -->服务器拒绝请求")
pattern = re.compile('"searchResult"\:(.*?),\"recommendResult\"\:',re.S)
items = re.findall(pattern, response.text)
json_text = items[0] + "}"
# print(json_text)
json_data = json.loads(json_text)
# print(len(json_data['searchResult']))
if len(json_data['searchResult']) == 0:
print(url+"未匹配到,列表页抓取完毕")
print("*" *30)
update_url_to_complete(need['id'])
break
for store in json_data['searchResult']:
# 创建sql 语句,并执行
sql = 'INSERT INTO `jiehun_detail` (`url`,`poi_id`, `front_img`, `title`, `address`) \
VALUES ("%s","%s","%s","%s","%s")' % (url, store['id'],store['imageUrl'],store['title'],store['address'])
# print(sql)
cursor.execute(sql)
# 提交SQL
connection.commit()
update_url_to_complete(need['id'])
print(url+ "抓取完毕")
print("*" *30)第三步:爬取商家详情
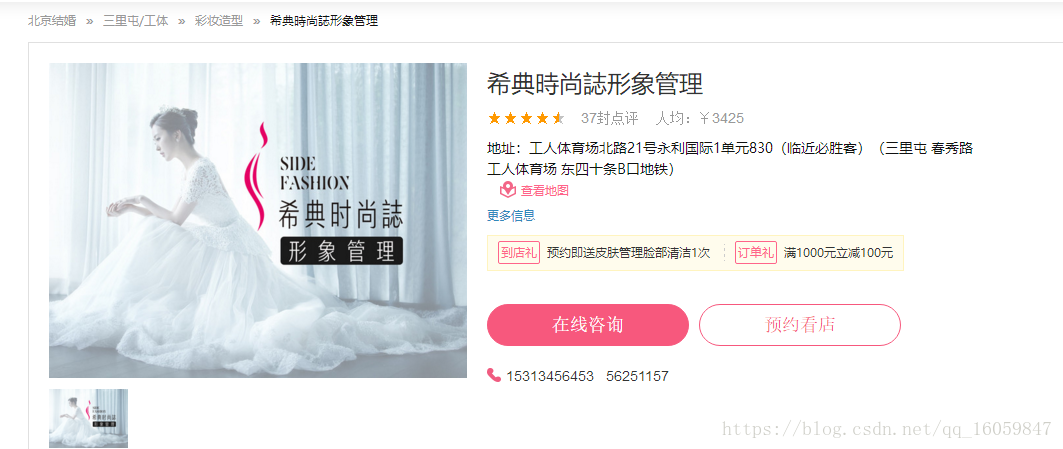
url为https://www.meituan.com/jiehun/68109543/
其中68109543为商家id,已经在第二步爬取到,拼接完后即可爬取商家详情
try:
headers = {}
print(need)
print("*" *30)
url = 'https://www.meituan.com/jiehun/' + str(need['poi_id']) + '/'
headers = requests_headers()
print(url+"开始抓取")
response = requests.get(url, headers=headers, timeout = 10)
pattern = re.compile('"errorMsg":"(\d*?)"',re.S)
h_code = re.findall(pattern, response.text)
if len(h_code) != 0 and h_code[0] == '403':
raise Exception("403:错误信息:<!-- -->服务器拒绝请求")
# print(response.text)
# exit()
soup = BeautifulSoup(response.text,'html.parser')
errorMessage = soup.select('.errorMessage')
if len(errorMessage) != 0:
update_url_to_complete(need['id'], '', '')
raise Exception(errorMessage[0].select('h2')[0].get_text())
open_time = soup.select('.more-item')[1].get_text().strip()
phone = soup.select('.icon-phone')[0].get_text().strip()
update_url_to_complete(need['id'], open_time, phone)
print(url+ "抓取完毕")
print("*" *30)
except Exception as e:
print(e)
print(headers)
cookies = create_cookies()其中美团会验证你爬虫的user-agent,cookie和ip,IP可通过代理ip,其实页可以通过手机分享热点,ip会自动更换,当ip被封时,重新分享热点即可,但需要人为操作。
cookie美团封的很快,必须程序自动切换,我这里简单的用Phantomjs模拟来获取headers头
def create_cookies():
driver = webdriver.PhantomJS()
cookiestr = []
# for x in range(1,10):
driver.get("https://bj.meituan.com/jiehun/")
driver.implicitly_wait(5)
cookie = [item["name"] + "=" + item["value"] for item in driver.get_cookies()]
print("生成cookie")
print(cookie)
cookiestr.append(';'.join(item for item in cookie))
return cookiestr到此,数据已全部爬取完毕,大概花了2天时间,一共9526条商家,不多时因为美团上只有这些商家,此方法也可爬取美食栏目,可有90万+的商家。结婚商家信息如下
