前些天接到需求,需要给客户爬取美团、大众点评、去哪儿、驴妈妈等网站的景区和酒店的评价相关信息。虽然我是做数据库的,之前也没写过Python爬虫,但只能硬着头发上。这里坐下简短的总结。
1 考虑爬取方式
最先考虑仅采取 webdriver + selenium 的方式爬取信息,但是考虑后续程序需要放在Linux服务器执行,所以转而采用 requests+beautifulsoup 的方式实现。
开发过程中,由于本人爬虫和前端知识的欠缺,最终采用两者的结合,而selenium可以通过headless的方式实现。
2 爬虫思路
目前有许多爬虫框架,我粗略的使用了以下思路实现增量爬取。
- requests(selenium)爬取数据;
- 判断爬取的数据是否数据库中已存在;
- 保存在dataframe对象中;
- 插入到数据库中。
3 爬虫之路
3.1 框架
编写爬虫框架。因为第一次写爬虫,把所有的方法都写在了同一个类中,但并不推荐这样写。
class NewsGain(object):
# 初始化
def __init__(self):
self.data = pd.DataFrame(columns = ["source","spot","time","userid","content","star"])
# 获取数据库连接对象
def con_mysql(self):
return db
# 查询数据库的最新日期
def get_last_time(self,source,spot):
return time
#插入数据库Oracle
def inOrcl(self,data):
pass
#插入数据库Mysql
def inMysql(self,data):
pass
# 保存数据到data
def saveData(self, source, spot, time, userid, content, star):
pass
# Test 导出csv文件
def toCSV(self,data,charset = 'utf-8'):
pass
#新闻爬取入口
def startGain(self,url):
pass
######################################具体爬取网站####################################
# 美团网
def meituan(self, url):
pass
# 大众点评
def dazhong(self, url):
pass
def loginDianPing(self):
pass
# 驴妈妈
def lvmama(self, url):
pass
# 去哪儿
def qunar(self, url):
pass
# 程序入口
if __name__ == "__main__":
# 目标爬取网站
sourcetUrl = []
# 获取爬取程序实例
newsGain = NewsGain()
# 爬取数据
for url in sourcetUrl:
newsGain.startGain(url)
newsGain.inMysql(newsGain.data)3.2 丰富除爬取网站之外的具体函数
3.2.1 连接数据库对象
# 连接数据库
def con_mysql(self):
db = pymysql.connect('localhost','root','111111','arvin', charset='utf8')
return db3.2.2 获取爬取开始时间
# 查询数据库的最新日期
def get_last_time(self,source,spot):
db = self.con_mysql()
# 创建cursor游标对象
cursor = db.cursor()
row_1 = '0'
# 插入语句
sql = 'select max(comment_time) time from t_jiangsu_tourism_sight where source_web =%s and sight_name =%s'
try:
row_count = cursor.execute(sql,(source,spot))
row_1 = cursor.fetchone()[0]
# print(row_count,row_1)
db.commit()
except Exception as e:
db.rollback()
print(e)
# 关闭数据库连接
cursor.close()
db.close()
if row_1 is None:
row_1 = '0'
return row_13.2.3 插入数据库
#插入数据库Oracle
def inOrcl(self,data):
# 将dataframe对象转化为list
L = np.array(data).tolist()
# 创建数据库连接
db = cx_Oracle.connect('arvin', '111111', '127.0.0.1:1521/orcl')
# 创建游标对象
cursor = db.cursor()
# 插入语句
cursor.prepare('insert into test(source,spot,time,userid,content,star) values(:1,:2,:3,:4,:5,:6)')
# 批量插入
cursor.executemany(None,L)
# 提交事务
db.commit() #插入数据库Mysql
def inMysql(self,data):
# 将dataframe对象转化为list
L = np.array(data).tolist()
# 获取数据库连接
db = self.con_mysql()
# 创建cursor游标对象
cursor = db.cursor()
# 插入语句
sql = 'insert into t_jiangsu_tourism_sight(source_web,sight_name,comment_time,comment_user,comment_text,comment_score) values(%s,%s,%s,%s,%s,%s)'
try:
cursor.executemany(sql,L)
db.commit()
except Exception as e:
db.rollback()
print(e)
# 关闭数据库连接
cursor.close()
db.close()3.2.4 保存数据
# 保存数据到data
def saveData(self, source, spot, time, userid, content, star):
index = self.data.shape[0]
self.data.at[index,'source'] = source
self.data.at[index,'spot'] = spot
self.data.at[index,'time'] = time
self.data.at[index,'userid'] = userid
self.data.at[index,'content'] = content
self.data.at[index,'star'] = star3.2.5 导出csv 用于测试
# Test 导出csv文件
def toCSV(self,data,charset = 'utf-8'):
try:
self.data.to_csv('test.csv', index = False, encoding = charset)
except Exception as e:
pass3.3 具体爬取网站
3.3.1 美团
我们以大伊山风景区为列http://www.meituan.com/xiuxianyule/1262239/。
首先通过火狐浏览器查看html中是否有评论信息,如下图:
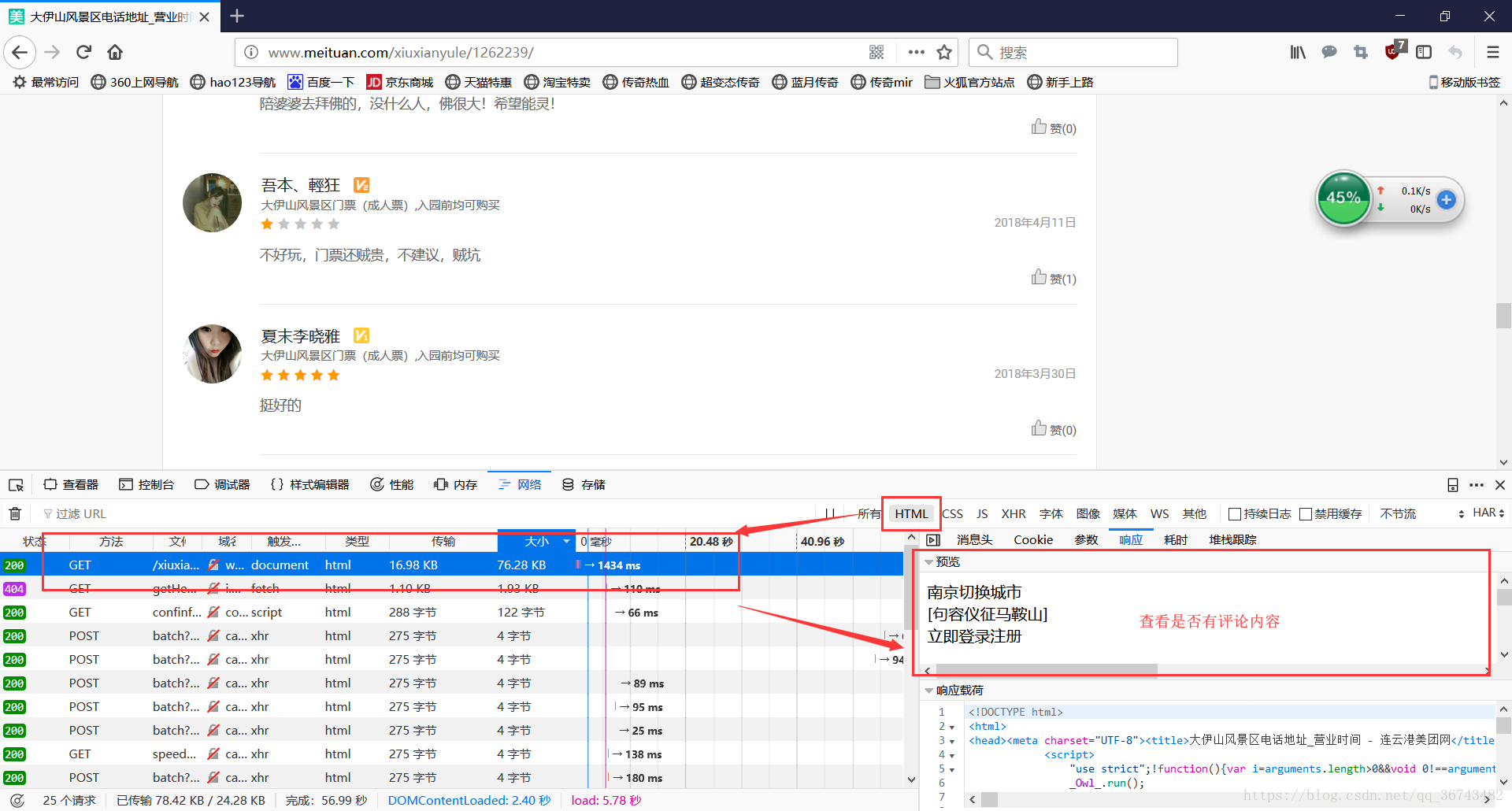
遗憾的是,并没有在html中发现评论信息,我们继续寻找。
本次查看XHR对象,终于发现了评论信息,如下图:
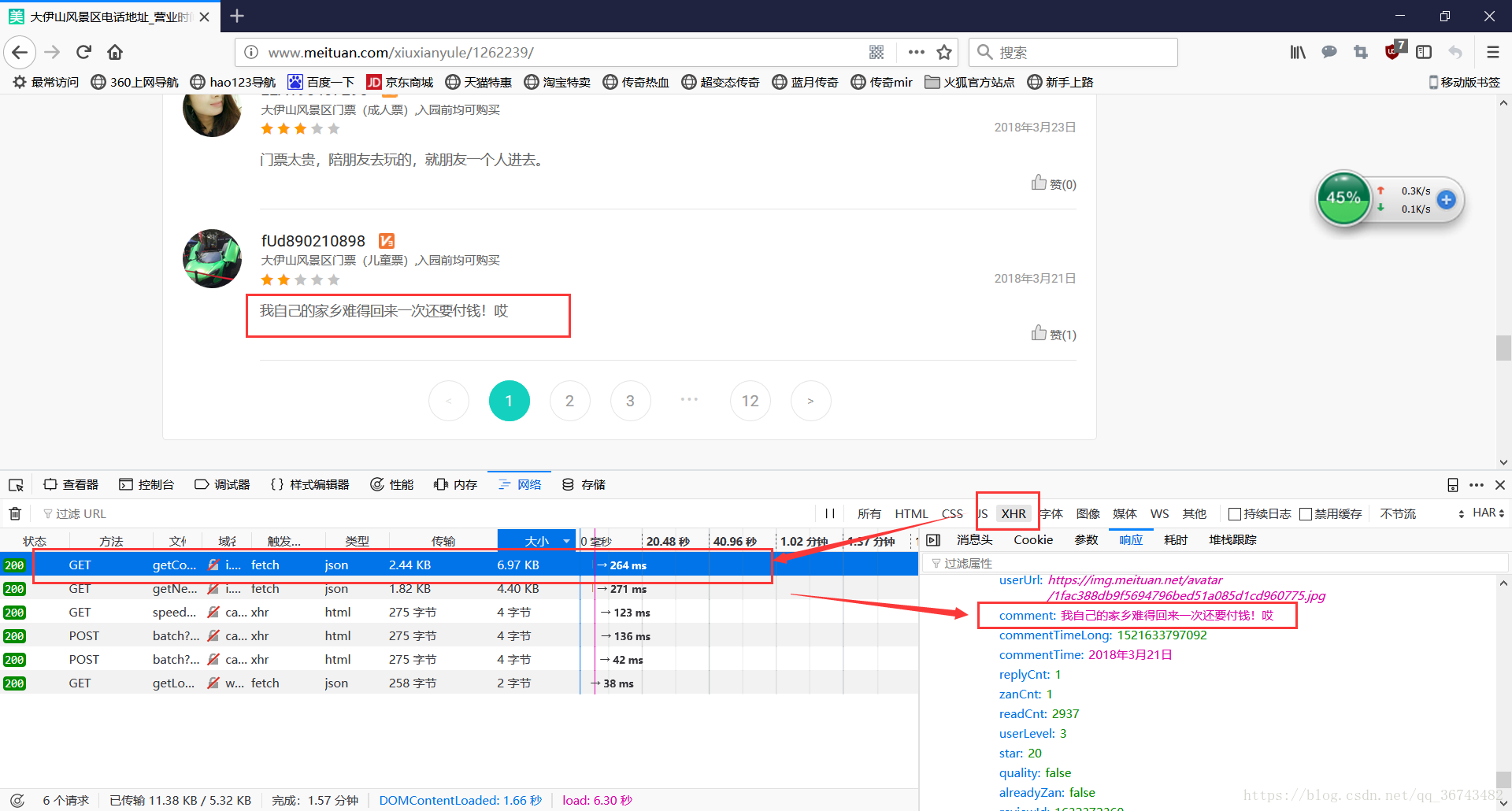
这样问题基本就解决了,我们直接复制请求url即可
http://i.meituan.com/xiuxianyule/api/getCommentList?poiId=1262239&offset=0&pageSize=10&sortType=1&mode=0&starRange=10%2C20%2C30%2C40%2C50&tag=我们直接把连接放在FireFox里,就会返回Json格式数据。
通过该url我们可以看出传递的参数,poiId 景区;offset,偏移量;pageSize,页面大小;sortType,排序方式;
但是还有一个问题,下一页我们该如何实现呢?
其实很简单,只要我们把pageSize设置的大点即可,如1000,就可以返回所有的评论。并且把sortType设置为0,就是按照时间排序,所以,我们把url变为以下方式即可:
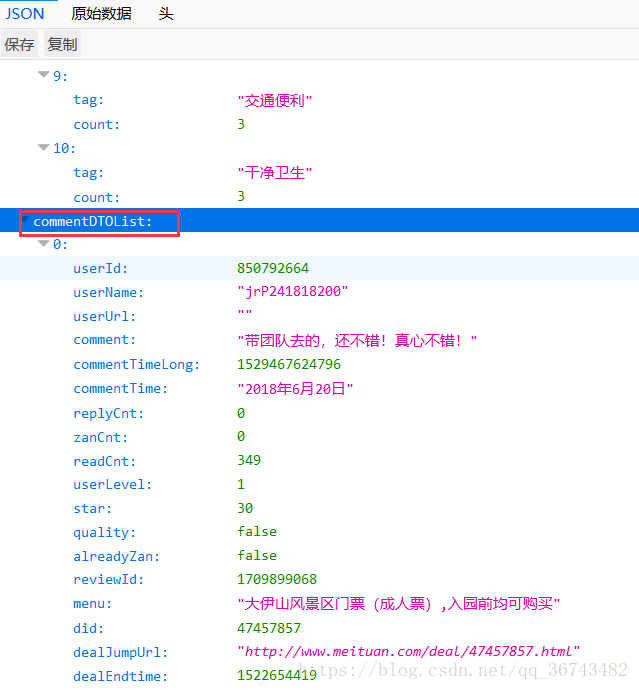
http://i.meituan.com/xiuxianyule/api/getCommentList?poiId=1262239&offset=0&pageSize=1000&sortType=0&mode=0&starRange=10%2C20%2C30%2C40%2C50&tag=%E5%85%A8%E9%83%A8接下来,我们直接解析这个Json对象的commentDTOList即可,如下图:
代码很简单,如下:
# 美团网
def meituan(self, url):
# 美团评价采用动态网页,访问对应的接口解析JSON即可
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
# 定义新闻源
source = u'美团'
# 访问网页
req = requests.get(url,headers = headers)
# 获取内容
charset = req.encoding
content = req.text.encode(charset).decode('utf-8')
# 转化为JSON对象
json_con = json.loads(content)
# 获取评论列表
comment_list = json_con['data']['commentDTOList']
# 根据url中的poiId判断地点
if url[58:60] == '16':
spot = '伊芦山'
else:
spot = '大伊山'
# 获取具体内容
for comment in comment_list:
# 地点
# spot = comment['menu'][:5]
# 评论时间
comment_time = datetime.datetime.strptime(comment['commentTime'],'%Y年%m月%d日')
time = datetime.datetime.strftime(comment_time,"%Y-%m-%d %H:%M")
# 用户
userid = comment['userName']
# 内容
content = comment['comment']
# 星级
star = comment['star']/10
if time > self.get_last_time(source,spot):
self.saveData(source,spot,time,userid,content,star)3.3.2 去哪儿
首先,我们查看能否通过requests实现,发现html中确实有评论。
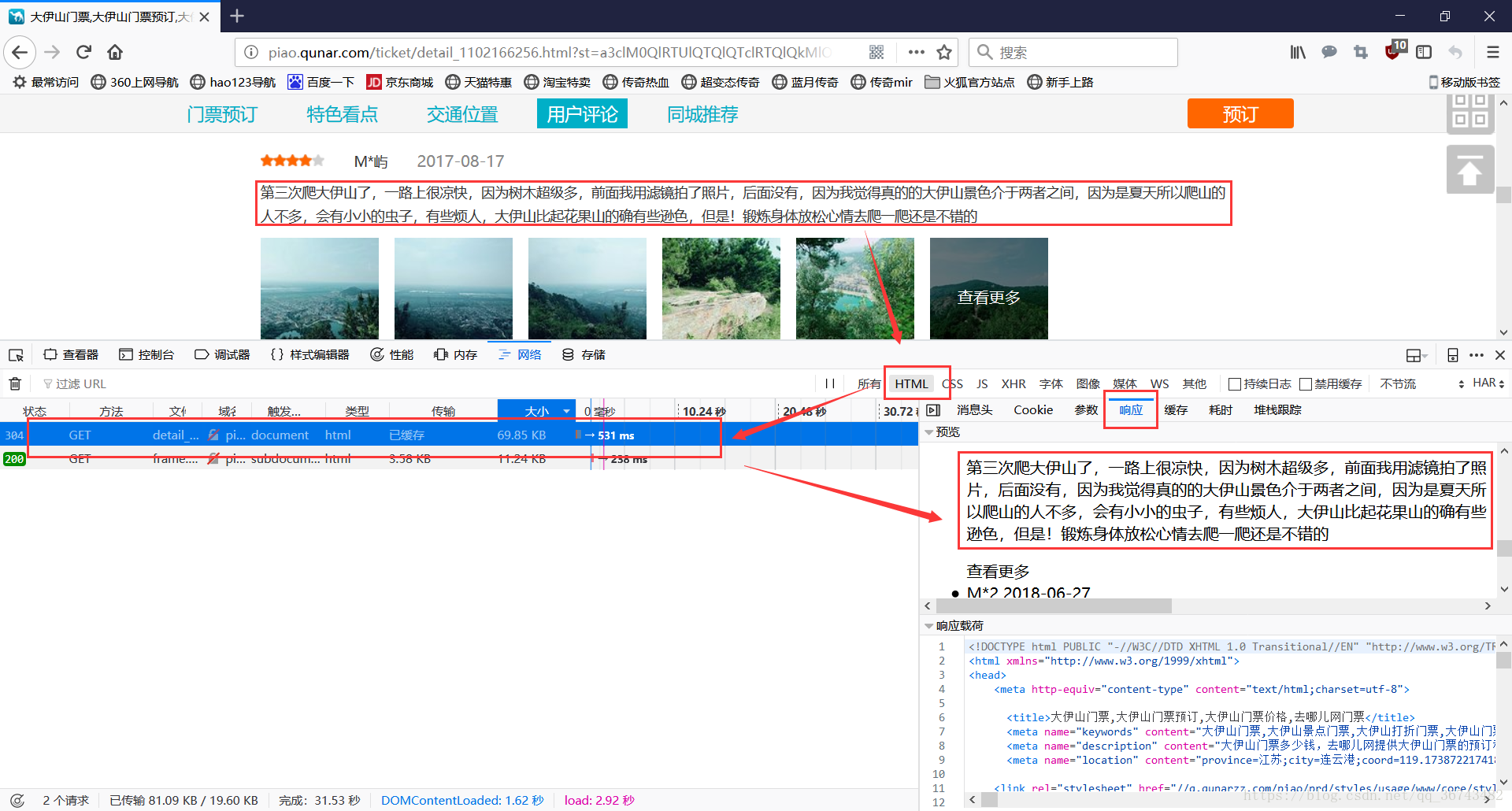
但是,还有一个问题要解决,我们看下一页怎么实现的。
当我们点击下一页,发现html并没有变化,并且是以缓存状态。这就意味这必然是通过其他方式实现的。我们看下是不是通过JSON实现的。
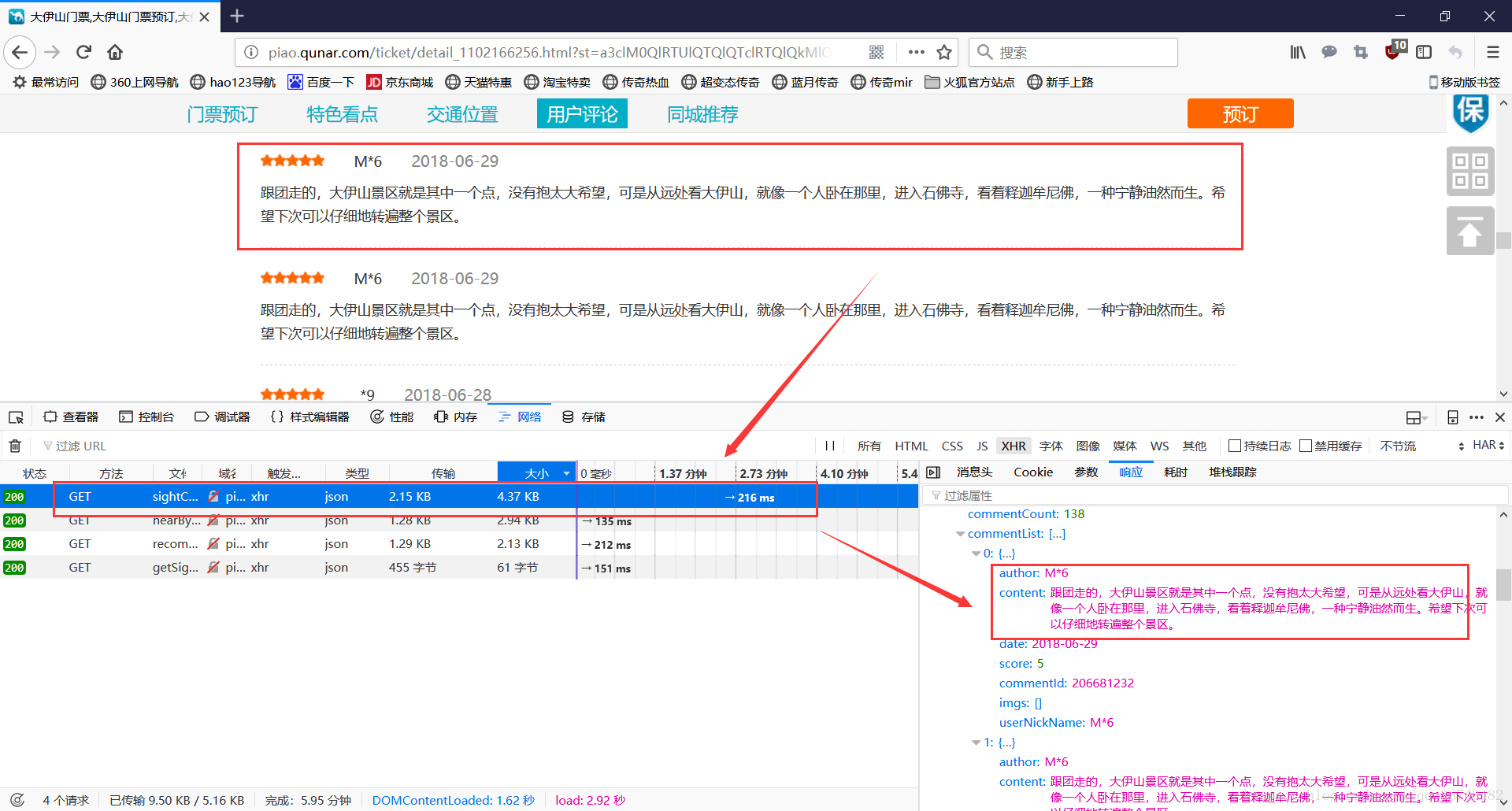
果然是通过JSON实现的。那么接下来就是定位参数含义,并且传递相关参数就行了,与美团类似。
# 去哪儿
def qunar(self, url):
# 网站来源
source = u'去哪儿'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
url[:45]
qunar_dir = {'http://piao.qunar.com/ticket/detail_110216625':{'sightId':31828,'spot':u'大伊山'}, # 大伊山
'http://travel.qunar.com/p-oi10010340-yilushan':{'sightId':None,'spot':u'伊芦山'}, # 伊芦山
'http://travel.qunar.com/p-oi10025389-chaohewa':{'sightId':None,'spot':u'潮河湾'}, # 潮河湾
'http://piao.qunar.com/ticket/detail_526407124':{'sightId':467928,'spot':u'伊甸园'} # 伊甸园
}
sightId = qunar_dir[url[:45]]['sightId']
spot = qunar_dir[url[:45]]['spot']
if sightId is None:
return
url = 'http://piao.qunar.com/ticket/detailLight/sightCommentList.json?sightId=%s&index=1&page=1&pageSize=500&tagType=0'%(sightId)
# print(url)
# 访问网页
req = requests.get(url,headers = headers)
# 获取内容
charset = req.encoding
content = req.text.encode(charset).decode('utf-8')
# 转化为JSON对象
json_con = json.loads(content)
# 获取页面数
# pages = json_con['data']['tagList'][0]['tagNum']
# 获取评论列表
comment_list = json_con['data']['commentList']
# 获取具体内容
for comment in comment_list:
userid = comment['author']
com_time = comment['date']
star = comment['score']
content = comment['content']
# print(content)
if com_time > self.get_last_time(source,spot):
self.saveData(source,spot,com_time,userid,content,star)3.3.3 驴妈妈
驴妈妈这个网站比较奇怪,最近手动访问,也没有评论,只能等这个网站好了在解释,先把代码放上来。
# 驴妈妈
def lvmama(self, url):
# 获取参数信息
lvDir = {'http://ticket.lvmama.com/scenic-103108':{'currentPage':9,'placeId':'103108','spot':'大伊山'},
'http://ticket.lvmama.com/scenic-11345447':{'currentPage':None,'placeId':'11345447','spot':'伊甸园'},
'http://ticket.lvmama.com/scenic-11345379':{'currentPage':None,'placeId':'11345379','spot':'伊芦山'}
}
if lvDir[url]['currentPage'] is None:
return
# 网站来源
source = u'驴妈妈'
spot = lvDir[url]['spot']
# 驴妈妈POSTurl
rurl = 'http://ticket.lvmama.com/vst_front/comment/newPaginationOfComments'
# 获取参数
for i in range(1,lvDir[url]['currentPage']):
print(i)
# 配置参数
params = {
'currentPage':i,
'isBest':None,
'isELong':'N',
'isPicture':None,
'isPOI':'Y',
'placeId':lvDir[url]['placeId'],
'placeIdType':'PLACE',
'productId':None,
'totalCount':72,
'type':'all'
}
# 获取soup对象
soup = self.getBS(rurl,params)
# 获取评论列表
comment_list = soup.find_all(class_ = 'comment-li')
# 遍历,获取每条的详细信息
for comment in comment_list:
star = comment.find(class_ = 'ufeed-level').i.get('data-level')
userid = comment.find(class_ = 'com-userinfo').p.a.get('title')
time = comment.find(class_ = 'com-userinfo').p.em.text
content = comment.find(class_ = 'ufeed-content').text.replace('\r\n','').replace(' ','')
# print(content)
if time > self.get_last_time(source,spot):
self.saveData(source,spot,time,userid,content,star)最总代码:
# -*- coding: utf-8 -*-
import requests
import cx_Oracle
import json
import datetime
import pymysql
import re
import time
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.support import expected_conditions as EC
from dianping import get_dianping
class StopSpyder(BaseException):pass
class NewsGain(object):
# 初始化
def __init__(self):
self.login = False
self.data = pd.DataFrame(columns = ["source","spot","time","userid","content","star"])
# 连接数据库
def con_mysql(self):
db = pymysql.connect('localhost','root','111111','arvin', charset='utf8')
return db
# 查询数据库的最新日期
def get_last_time(self,source,spot):
db = self.con_mysql()
# 创建cursor游标对象
cursor = db.cursor()
row_1 = '0'
# 插入语句
sql = 'select max(comment_time) time from t_jiangsu_tourism_sight where source_web =%s and sight_name =%s'
try:
row_count = cursor.execute(sql,(source,spot))
row_1 = cursor.fetchone()[0]
# print(row_count,row_1)
db.commit()
except Exception as e:
db.rollback()
print(e)
# 关闭数据库连接
cursor.close()
db.close()
if row_1 is None:
row_1 = '0'
return row_1
#插入数据库Oracle
def inOrcl(self,data):
# 将dataframe对象转化为list
L = np.array(data).tolist()
# 创建数据库连接
db = cx_Oracle.connect('arvin', '11111', '127.0.0.1:1521/orcl')
# 创建游标对象
cursor = db.cursor()
# 插入语句
cursor.prepare('insert into test(source,spot,time,userid,content,star) values(:1,:2,:3,:4,:5,:6)')
# 批量插入
cursor.executemany(None,L)
# 提交事务
db.commit()
#插入数据库Mysql
def inMysql(self,data):
# 将dataframe对象转化为list
L = np.array(data).tolist()
# 获取数据库连接
db = self.con_mysql()
# 创建cursor游标对象
cursor = db.cursor()
# 插入语句
sql = 'insert into t_jiangsu_tourism_sight(source_web,sight_name,comment_time,comment_user,comment_text,comment_score) values(%s,%s,%s,%s,%s,%s)'
try:
cursor.executemany(sql,L)
db.commit()
except Exception as e:
db.rollback()
print(e)
# 关闭数据库连接
cursor.close()
db.close()
# 获取BeautifulSoup对象
def getBS(self,url,params = None):
#定义访问文件头
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
# 访问网页
req = requests.get(url, headers = headers, params=params)
# 获取编码
charset = req.encoding
# 获取网页内容
content = req.text
# 先根据原编码转化为字节bytes,转化为utf-8字符串str
content = content.encode(charset).decode('utf-8')
# 获取bs对象,类型未lxmlfin
soup = BeautifulSoup(content, 'lxml')
# soup = BeautifulSoup(content, 'html.parser')
# 去掉style标签
[s.extract() for s in soup('style')]
# 返回soup
return soup
# 保存数据到data
def saveData(self, source, spot, time, userid, content, star):
index = self.data.shape[0]
self.data.at[index,'source'] = source
self.data.at[index,'spot'] = spot
self.data.at[index,'time'] = time
self.data.at[index,'userid'] = userid
self.data.at[index,'content'] = content
self.data.at[index,'star'] = star
# Test 导出csv文件
def toCSV(self,data,charset = 'utf-8'):
try:
self.data.to_csv('test.csv', index = False, encoding = charset)
except Exception as e:
pass
#新闻爬取入口
def startGain(self,url):
if url[12] == 'd':
returnlist = get_dianping(url)
for one in returnlist:
if one[1] > self.get_last_time(u'点评',one[0][:3]):
self.saveData(u'点评', one[0][:3],one[1],one[2],one[3],one[4])
pass
elif url[9] == 'm':
self.meituan(url = url)
pass
elif url[7:9] == 'ti':
self.lvmama(url = url)
pass
elif url[12:17] or url[14:19] == 'qunar':
self.qunar(url = url)
pass
else:
pass
######################################具体爬取网站####################################
# 美团网
def meituan(self, url):
# 美团评价采用动态网页,访问对应的接口解析JSON即可
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
# 定义源
source = u'美团'
# 访问网页
req = requests.get(url,headers = headers)
# 获取内容
charset = req.encoding
content = req.text.encode(charset).decode('utf-8')
# 转化为JSON对象
json_con = json.loads(content)
# 获取评论列表
comment_list = json_con['data']['commentDTOList']
# 根据url中的poiId判断地点
if url[58:60] == '16':
spot = '伊芦山'
else:
spot = '大伊山'
# 获取具体内容
for comment in comment_list:
# 地点
# spot = comment['menu'][:5]
# 评论时间
comment_time = datetime.datetime.strptime(comment['commentTime'],'%Y年%m月%d日')
time = datetime.datetime.strftime(comment_time,"%Y-%m-%d %H:%M")
# 用户
userid = comment['userName']
# 内容
content = comment['comment']
# 星级
star = comment['star']/10
if time > self.get_last_time(source,spot):
self.saveData(source,spot,time,userid,content,star)
# self.toCSV(data)
# self.inMysql(data)
# 大众点评是javascript渲染的页面,html返回的评论信息不全,考虑采用selenium
def dazhong(self, url):
self.loginDianPing()
# 定义新闻源
source = u'大众'
# 访问网页
self.driver.get(url)
# self.dr.get('http://www.dianping.com/shop/5400289')
time.sleep(3)
# 获取景点名称
try:
wholeSpot = self.driver.find_element_by_xpath("/html/body/div[1]/div[2]/div/div[2]/div[1]/h1").text
except:
wholeSpot = self.driver.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[1]/h1").text
spot = wholeSpot[:3]
wholeSpot = spot
# wholeSpot = '潮河湾'
print(wholeSpot)
try:
while True:
# 获取当前页面的评论
currentPageCommentItem = self.driver.find_elements_by_class_name("comment-item")
# 遍历每一条评论
for index,item in enumerate(currentPageCommentItem):
date = item.find_element_by_class_name("time").text # 评论的时间
date = datetime.datetime.strptime(re.sub("\D","",date)[:8], "%Y%m%d")
if self.stopSpyder(source, wholeSpot, date): # 判断是否需要继续爬取
raise StopSpyder
else:
# 爬取信息
userId = item.find_element_by_class_name("name").text
print(userId)
try:
item.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[8]/ul/li['+ str(index[0]) +']/div/div[1]/a').click()
content = item.find_element_by_class_name("desc J-desc").text
except:
content = item.find_element_by_class_name("desc").text
star = item.find_element_by_xpath("/html/body/div[1]/div[2]/div/div[2]/div[8]/ul/li[1]/div/p[1]/span").get_attribute("class")
star = round(int(re.sub("\D","",star)) / 10)
# 保存数据
index = self.data.shape[0]
self.data.at[index,"time"] = datetime.datetime.strftime(date,"%Y%m%d")
print('time:{}'.format(datetime.datetime.strftime(date,"%Y%m%d")))
self.data.at[index,"id"] = userId
print('id:{}'.format(userId))
self.data.at[index,"source"] = source
print('source:{}'.format(source))
self.data.at[index,"spot"] = spot
print('spot:{}'.format(spot))
self.data.at[index,"content"] = content
print('content:{}'.format(content))
self.data.at[index,"star"] = star
print('star:{}'.format(star))
self.data.to_csv("result.csv",index=False,encoding="utf-8")
break
except StopSpyder:
pass
except Exception as e:
print(e)
# # 访问网页
## soup = self.getBS(url)
#
## news = soup.find_all(class_ = 'comment-item')
#
def loginDianPing(self):
if not self.login:
# 登陆网站
self.driver.get('http://account.dianping.com/login')
WebDriverWait(self.driver, 10).until(EC.frame_to_be_available_and_switch_to_it(self.driver.find_element_by_xpath('//iframe[contains(@src, "account")]')))
self.driver.find_element_by_class_name('bottom-password-login').click()
self.driver.find_element_by_id('tab-account').click()
self.driver.find_element_by_id('account-textbox').clear()
self.driver.find_element_by_id('account-textbox').send_keys('15366181451')
self.driver.find_element_by_id('password-textbox').clear()
self.driver.find_element_by_id('password-textbox').send_keys('hongxin12')
self.driver.find_element_by_id('login-button-account').click()
cur_url = self.driver.current_url
while cur_url == self.driver.current_url:
time.sleep(5)
self.driver.switch_to_default_content()
self.driver.get('http://www.dianping.com/shop')
time.sleep(3)
self.login = True
# 驴妈妈
def lvmama(self, url):
# 获取参数信息
lvDir = {'http://ticket.lvmama.com/scenic-103108':{'currentPage':9,'placeId':'103108','spot':'大伊山'},
'http://ticket.lvmama.com/scenic-11345447':{'currentPage':None,'placeId':'11345447','spot':'伊甸园'},
'http://ticket.lvmama.com/scenic-11345379':{'currentPage':None,'placeId':'11345379','spot':'伊芦山'}
}
if lvDir[url]['currentPage'] is None:
return
# 网站来源
source = u'驴妈妈'
spot = lvDir[url]['spot']
# 驴妈妈POSTurl
rurl = 'http://ticket.lvmama.com/vst_front/comment/newPaginationOfComments'
# 获取参数
for i in range(1,lvDir[url]['currentPage']):
print(i)
# 配置参数
params = {
'currentPage':i,
'isBest':None,
'isELong':'N',
'isPicture':None,
'isPOI':'Y',
'placeId':lvDir[url]['placeId'],
'placeIdType':'PLACE',
'productId':None,
'totalCount':72,
'type':'all'
}
# 获取soup对象
soup = self.getBS(rurl,params)
# 获取评论列表
comment_list = soup.find_all(class_ = 'comment-li')
# 遍历新闻,获取每条的详细信息
for comment in comment_list:
star = comment.find(class_ = 'ufeed-level').i.get('data-level')
userid = comment.find(class_ = 'com-userinfo').p.a.get('title')
time = comment.find(class_ = 'com-userinfo').p.em.text
content = comment.find(class_ = 'ufeed-content').text.replace('\r\n','').replace(' ','')
# print(content)
if time > self.get_last_time(source,spot):
self.saveData(source,spot,time,userid,content,star)
# 去哪儿
def qunar(self, url):
# 网站来源
source = u'去哪儿'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
url[:45]
qunar_dir = {'http://piao.qunar.com/ticket/detail_110216625':{'sightId':31828,'spot':u'大伊山'}, # 大伊山
'http://travel.qunar.com/p-oi10010340-yilushan':{'sightId':None,'spot':u'伊芦山'}, # 伊芦山
'http://travel.qunar.com/p-oi10025389-chaohewa':{'sightId':None,'spot':u'潮河湾'}, # 潮河湾
'http://piao.qunar.com/ticket/detail_526407124':{'sightId':467928,'spot':u'伊甸园'} # 伊甸园
}
sightId = qunar_dir[url[:45]]['sightId']
spot = qunar_dir[url[:45]]['spot']
if sightId is None:
return
url = 'http://piao.qunar.com/ticket/detailLight/sightCommentList.json?sightId=%s&index=1&page=1&pageSize=500&tagType=0'%(sightId)
# print(url)
# 访问网页
req = requests.get(url,headers = headers)
# 获取内容
charset = req.encoding
content = req.text.encode(charset).decode('utf-8')
# 转化为JSON对象
json_con = json.loads(content)
# 获取页面数
# pages = json_con['data']['tagList'][0]['tagNum']
# 获取评论列表
comment_list = json_con['data']['commentList']
# 获取具体内容
for comment in comment_list:
userid = comment['author']
com_time = comment['date']
star = comment['score']
content = comment['content']
# print(content)
if com_time > self.get_last_time(source,spot):
self.saveData(source,spot,com_time,userid,content,star)
# self.inMysql(self.data)
# 程序入口
if __name__ == "__main__":
# 目标爬取网站
sourcetUrl = ['http://i.meituan.com/xiuxianyule/api/getCommentList?poiId=1262239&offset=0&pageSize=1000&sortType=0&mode=0&starRange=10%2C20%2C30%2C40%2C50&tag=%E5%85%A8%E9%83%A8', #'http://www.meituan.com/xiuxianyule/1262239/' #大伊山
'http://i.meituan.com/xiuxianyule/api/getCommentList?poiId=165644028&offset=0&pageSize=1000&sortType=0&mode=0&starRange=10%2C20%2C30%2C40%2C50&tag=%E5%85%A8%E9%83%A8', #'http://www.meituan.com/xiuxianyule/165644028/' #伊芦山
'https://www.dianping.com/shop/5400289/review_all', #大伊山
'https://www.dianping.com/shop/11884431/review_all', #潮河湾
'https://www.dianping.com/shop/98669133/review_all', #伊芦山
'https://www.dianping.com/shop/14713390/review_all', #伊芦山
'https://www.dianping.com/shop/98241681/review_all', #伊芦山
'http://ticket.lvmama.com/scenic-103108', #驴妈妈大伊山
'http://ticket.lvmama.com/scenic-11345447', #驴妈妈伊甸园
'http://ticket.lvmama.com/scenic-11345379', #驴妈妈伊芦山梅园
'http://piao.qunar.com/ticket/detail_1102166256.html?st=a3clM0QlRTUlQTQlQTclRTQlQkMlOEElRTUlQjElQjElMjZpZCUzRDMxODI4JTI2dHlwZSUzRDAlMjZpZHglM0QxJTI2cXQlM0RuYW1lJTI2YXBrJTNEMiUyNnNjJTNEV1dXJTI2YWJ0cmFjZSUzRGJ3ZCU0MCVFNiU5QyVBQyVFNSU5QyVCMCUyNnVyJTNEJUU4JUJGJTlFJUU0JUJBJTkxJUU2JUI4JUFGJTI2bHIlM0QlRTYlOUMlQUElRTclOUYlQTUlMjZmdCUzRCU3QiU3RA%3D%3D#from=qunarindex', # 去哪儿大伊山
'http://travel.qunar.com/p-oi10010340-yilushan', #去哪儿伊芦山
'http://travel.qunar.com/p-oi10025389-chaohewanshengtaiyuan', #去哪儿潮河湾
'http://piao.qunar.com/ticket/detail_526407124.html?from=mpd_recommend_sight' # 去哪儿伊甸园
]
# 获取爬取程序实例
newsGain = NewsGain()
# 爬取数据
for url in sourcetUrl:
newsGain.startGain(url)
newsGain.inMysql(newsGain.data)
大众点评是单独写:

#coding=utf-8
from bs4 import BeautifulSoup
import requests
import sys
stdi,stdo,stde=sys.stdin,sys.stdout,sys.stderr
#reload(sys)
sys.stdin,sys.stdout,sys.stderr=stdi,stdo,stde
#sys.setdefaultencoding("utf-8")
import json
#cfgcookie.txt人工输入的cookie
def getcookiestr(path):
'''
path:配置文件路径
'''
try:
dicookie = {}
with open(path + r'cfgcookie.txt', 'r') as r:
inputstr = r.read()
for one in inputstr.split('; '):
dicookie[one.split('=')[0]] = one.split('=')[1]
# for x,y in dicookie.items():
# print (type(y))
print(dicookie)
return dicookie
except Exception as e:
print (str(e))
print (u'请检查cfgcookie.txt配置文件正确性!')
#cfgcookie.txt人工输入的cookie
#newcookie.json记录每次操作后更新的cookie
def getcookies(path):
'''
path:配置文件路径
'''
try:
dicookie = {}
with open(path + r'newcookie.json','r') as r:
try:
dicookie = json.load(r)
print (dicookie)
except Exception as e:
print (str(e))
#newcookie.json读取错误之后读取cfgcookie.txt
with open(path + r'cfgcookie.txt', 'r') as r:
inputstr = r.read()
for one in inputstr.split('; '):
dicookie[one.split('=')[0]] = one.split('=')[1]
# for x,y in dicookie.items():
# print (type(y))
return dicookie
except Exception as e:
print (str(e))
print (u'请检查cfgcookie.txt配置文件正确性!')
def savenewcookie(path, dicookie):
'''
存储最新的cookie
path:配置文件路径
dicookie:存储的dict
'''
try:
with open(path + r'newcookie.json','w') as w:
json.dump(dicookie,w)
except Exception as e:
print (str(e))
print (u'存储newcookie.json出错了!')
def get_dianping(scenic_url):
proxies = {
# "http": "50.233.137.33:80",
"http":"45.77.25.235:8081",
}
headers = {
'Host': 'www.dianping.com',
'Referer': 'http://www.dianping.com/shop/22711693',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/535.19',
'Accept-Encoding': 'gzip'
}
headers['Referer'] = scenic_url.replace('https', 'http').replace('/review_all', '')
cookies = {'cy':'835',
'cye':'guanyun',
'_lxsdk_cuid':'16426247fafc8-0cf040f6fc4a118-4c312b7b-100200-16426247fafc8',
'_lxsdk':'16426247fafc8-0cf040f6fc4a118-4c312b7b-100200-16426247fafc8',
'_hc.v':'7b5b3de6-776c-46d2-e7d3-e468d13446dc.1529648284',
'_dp.ac.v':'c584c92c-95aa-4220-a4e0-bb40878ae863',
'ua':'15366181451',
's_ViewType':'10',
'_lxsdk_s':'1644ec042ce-f7f-0ee-489%7C%7C1176',
'cityInfo':'%7B%22cityId%22%3A835%2C%22cityEnName%22%3A%22guanyun%22%2C%22cityName%22%3A%22%E7%81%8C%E4%BA%91%E5%8E%BF%22%7D',
'__mta':'146585483.1530329665619.1530330562343.1530330863738.6',
'ctu':'4a3974cdf5b2e5b0fd3b2d9a6ec23a7d48c74ae4f2a36e72bfed34b59b322f331e42d186b52cd0db5fa5a045e40f22d4',
'dper':'79ff66a7e0fc79b70c8ac58013ca79eda9a3b87d62b5ad42a670e8244ddcbba0ee1a751db6a8e0ff39608623d5575eb1e6f8237e50713a9455f35c1d81ef75cbed81c68fc95315a4c2dde5930e0a840d14eddc61aee31c213f59c602aba3d13d',
'll':'7fd06e815b796be3df069dec7836c3df',
'_lx_utm':'utm_source%3DBaidu%26utm_medium%3Dorgani'}
# cookies= getcookiestr('.\\')
# cookies = {,
# '_lxsdk_cuid': '16146a366a7c8-08cd0a57dad51b-32637402-fa000-16146a366a7c8',
# '_lxsdk': '16146a366a7c8-08cd0a57dad51b-32637402-fa000-16146a366a7c8',
# '_hc.v': 'ec20d90c-0104-0677-bf24-391bdf00e2d4.1517308569',
# 's_ViewType': '10',
# 'cy': '16',
# 'cye': 'wuhan',
# '_lx_utm': 'utm_source%3DBaidu%26utm_medium%3Dorganic',
# '_lxsdk_s': '1614abc132e-f84-b9c-2bc%7C%7C34'
# }
requests.adapters.DEFAULT_RETRIES = 5
s = requests.session()
s.keep_alive = False
returnList = []
# url = "https://www.dianping.com/shop/%s/review_all" % scenic_id
r = requests.get(scenic_url, headers=headers, cookies=cookies, proxies = proxies)#
# print r.text
with open(r'downloade0.html','wb') as w:
w.write(r.text.encode('utf-8'))
soup = BeautifulSoup(r.text, 'lxml')
# print soup
lenth = soup.find_all(class_='PageLink').__len__() + 1
print ("lenth:%d"%(lenth))
title = soup.select_one('.shop-name')
try:
title = title.get_text()
except Exception as e:
pass
print ("title:%s"%(title))
coment = soup.select('.reviews-items ul li')
for one in coment:
try:
if one['class'][0]=='item':
continue
except Exception:
pass
time = one.select_one('.main-review .time')
time = time.get_text().strip()
print ("time:%s"%(time))
name = one.select_one('.main-review .dper-info .name')
name = name.get_text().strip()
print ("name:%s"%(name))
star = one.select_one('.main-review .review-rank span')
star = star['class'][1][7:8]
print ("star:%s"%(star))
pl = one.select_one('.main-review .review-words')
words = pl.get_text().strip().replace(u'展开评论','')
print ("word:%s"%(words))
returnList.append([title,time,name,words,star])
print ('=============================================================')
if lenth > 1:
headers['Referer'] = scenic_url.replace('https', 'http')
for i in range(2,lenth+1):
urlin = scenic_url + '/p' + str(i)
r = requests.get(urlin, headers=headers, cookies=cookies, proxies = proxies)
with open(r'downloade.html','wb') as w:
w.write(r.text.encode('utf-8'))
# print r.text
soup = BeautifulSoup(r.text, 'lxml')
title = soup.select_one('.shop-name')
title = title.get_text()
print ("title:%s"%(title))
coment = soup.select('.reviews-items ul li')
for one in coment:
try:
if one['class'][0]=='item':
continue
except Exception:
pass
time = one.select_one('.main-review .time')
time = time.get_text().strip()
print ("time:%s"%(time))
name = one.select_one('.main-review .dper-info .name')
name = name.get_text().strip()
print ("name:%s"%(name))
star = one.select_one('.main-review .review-rank span')
star = star['class'][1][7:8]
print ("star:%s"%(star))
pl = one.select_one('.main-review .review-words')
words = pl.get_text().strip().replace(u'展开评论','').replace(u'收起评论','')
print ("word:%s"%(words))
returnList.append([title,time,name,words,star])
print ('=============================================================')
return returnList
def atest():
headers = {
'Host': 'www.baidu.com',
'Referer': 'https://www.baidu.com/link?url…6885dc00070b51000000035b3765f4',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/535.19',
'Accept-Encoding': 'gzip'
}
cookies= getcookiestr('.\\')
cookies = requests.utils.cookiejar_from_dict(cookies, cookiejar=None, overwrite=True)
resion = requests.Session()
resion.cookies = cookies
r = resion.get('https://www.baidu.com/', headers=headers)
savenewcookie('.\\', r.cookies.get_dict())#存储更新后的cookie
if __name__ == "__main__":
get_dianping('https://www.dianping.com/shop/13754477/review_all')
# atest()