Python爬取网页所有小说
python 2.7.15
练习beautifulsoup的使用
不了解bs的可以先看一下这个bs文档
一、看URL的规律
因为是要爬取网页上所有的小说,所以不仅要获取网页的URL,还要获取网页里的连接们的URL。它们一般是有规律的,如果没有的话就用正则或bs抓一个列表出来遍历。
我找了一个东野圭吾作品集的网站,网址如下:

然后是作品列表,点击图片或名字都可以进入这个小说的网页
好了,上源码
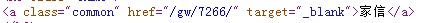
这是列表里第一本小说《家信》的相关信息,它存在一个class为common的a标签里,其中的href属性的值就是这本小说的URL

我们要获取所有小说的这个值,代码如下
url ="http://www.shunong.com/author/311/"
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read()
soup = BeautifulSoup(content,'html.parser')
a = soup.find_all("a" , class_="common")
n = 1
for b in a :
if n%2==0:
add = b.get('href').encode('utf-8')
name = b.get_text().encode('utf-8')
print name
book(add, name)
n+=1
这个if是因为源码里同样的信息出现了两遍,去一个就行
列表里遍历出来的值后面一定要加一个encode,因为bs对象都是Unicode,写到文档里就成乱码了
这样就获得了这个网页上的所有小说的网址了,这个book函数就是对书名及其网址的操作
二、爬取章节
还是找URL的规律以《家信》为例

这是源代码里全部的章节及其网址
这一部分就是 刚才的book函数,这里我用的正则
def book(add, name):
url = "http://www.shunong.com" + add
print url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read()
pattern = re.compile('<li><a href="(.*?)" title=".*?</a></li>')
items = re.findall(pattern, content)
获取之后循环遍历执行下一个章节函数,同时打开一个文本文档准备存这一本小说
n = 0
f = open(name.decode('utf-8') + '.txt', 'a')
for item in items:
if n>4:
books = item
d =chapter(books)
print d
#f.writelines(d)
n+=1
f.close()
三、爬取内容
得到章节的网址后就可以爬取章节里的内容了
还是先看源码

章节名在h1标签里,章节内容在p标签里,但是源码里的p标签不止一个,这就需要我们筛选。先打印所有p标签,每打印一个,就输出一些符号,便于观察,打印出来后看正文是第几个标签,这里是第二个。
soup = BeautifulSoup(content,'html.parser')
a = soup.find('h1')
b = soup.find_all('p')
a = a.get_text(strip=True)
a = a.encode('utf-8')
d = a + '\n'
c = b[1].get_text(strip=True).encode('utf-8')
d = d + c
d = d + '\n'
return d
获取到内容后return,递给上一个函数,写入文档。
四、完整代码
# coding=utf-8
from bs4 import BeautifulSoup
import urllib2
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def chapter(books):
url = "http://www.shunong.com" + books
print url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read()
soup = BeautifulSoup(content,'html.parser')
a = soup.find('h1')
b = soup.find_all('p')
a = a.get_text(strip=True)
a = a.encode('utf-8')
d = a + '\n'
c = b[1].get_text(strip=True).encode('utf-8')
d = d + c
d = d + '\n'
return d
def book(add, name):
url = "http://www.shunong.com" + add
print url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read()
pattern = re.compile('<li><a href="(.*?)" title=".*?</a></li>')
items = re.findall(pattern, content)
n = 0
f = open(name.decode('utf-8') + '.txt', 'a')
for item in items:
if n>4:
books = item
d =chapter(books)
print d
f.writelines(d)
n+=1
f.close()
url ="http://www.shunong.com/author/311/"
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read()
soup = BeautifulSoup(content,'html.parser')
a = soup.find_all("a" , class_="common")
n = 1
for b in a :
if n%2==0:
add = b.get('href').encode('utf-8')
name = b.get_text().encode('utf-8')
print name
book(add, name)
n+=1