代理池设置:
这里代理ip从快代理那获取,新用户有4小时免费测试时间。从http://dps.kdlapi.com/api/getdps/中获取我们的ip代理池,根据用户名密码最后生成proxy_auth代理池。
proxy_auth = []
username = "####"
password = "####"
ips = requests.get('http://dps.kdlapi.com/api/getdps/?orderid=#####&num=30&pt=1&format=json&sep=1')
ips_arr = json.loads(ips.text)
for ip in ips_arr['data']['proxy_list']:
proxy_auth_temp = {"http": "http://%(user)s:%(pwd)s@%(ip)s/" % {'user': username, 'pwd': password, 'ip': ip},
"https": "http://%(user)s:%(pwd)s@%(ip)s/" % {'user': username, 'pwd': password, 'ip': ip}}
proxy_auth.append(proxy_auth_temp)美团网抓取鲜花商家信息:
在输入鲜花信息后,点击搜索,打开network,分析我们想要的数据
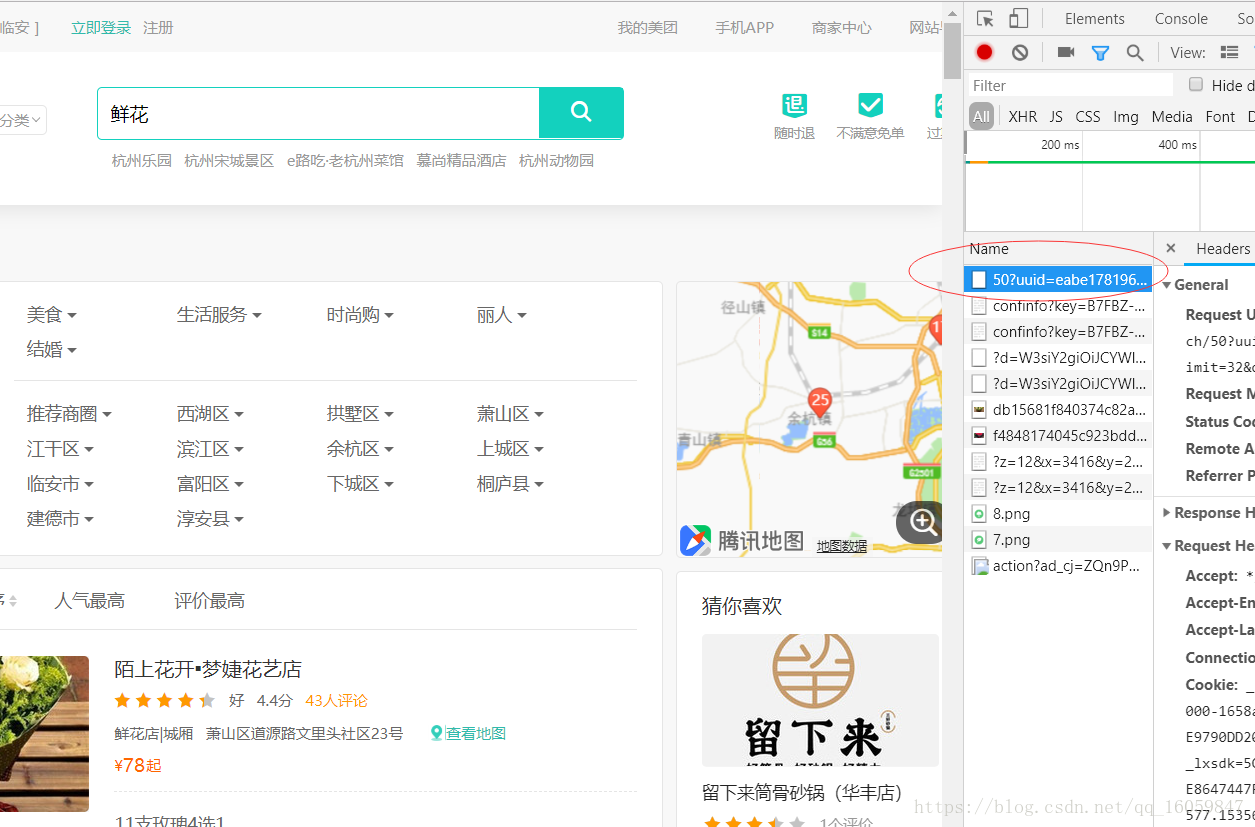

分析Query String Parameters构成,不难推测各个参数的意思,由于商家具体信息需要点列表的超链接进去二级详细页面,所以我们需要获取到列表页的超链接信息。 最后的python代码为
data = {
'uuid':'2a344b34b62b4666af73.1535625802.1.0.0',
'userid':-1,
'limit':32,
'offset':32*page_num,
'cateId':-1,
'q':search,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
url = 'http://apimobile.meituan.com/group/v4/poi/pcsearch/50?'
reponse = requests.get(url,params=data,headers=headers)
data = json.loads(reponse.text)
if data and 'data' in data.keys():
for item in data.get('data').get('searchResult'):
url = 'http://www.meituan.com/shenghuo/'+ str(item.get('id'))+'/'
print(url)最后在商家详细页面抓取我们想要的商家信息:
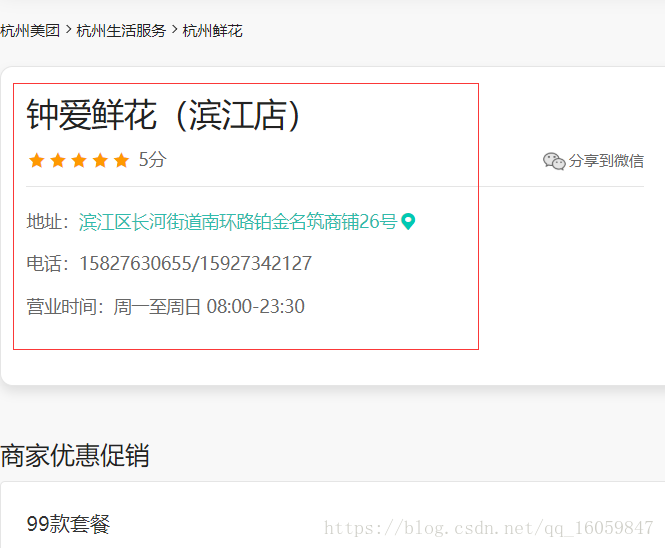
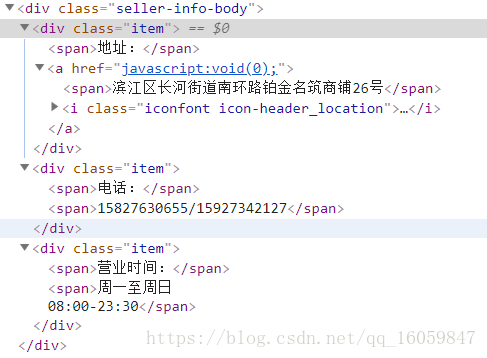
headers = {
'Host': 'www.meituan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
prox = random.choice(proxy_auth)
try:
detail = requests.get(url, proxies=prox,headers=headers,timeout=10)
except requests.RequestException as e:
proxy_auth.remove(prox)
else:
soup = BeautifulSoup(detail.text,'html.parser')
end = {
'seller_name' : soup.select('.seller-name')[0].get_text().strip(),
'address' : soup.select('.seller-info-body .item')[0].get_text().strip(),
'mobile' : soup.select('.seller-info-body .item')[1].get_text().strip(),
# 'time' : soup.select('.seller-info-body .item')[2].get_text().strip(),
}
print(end)
result.append(end)
# exit()
urls.append(url)
time.sleep(3)注意点:
prox = random.choice(proxy_auth) 从我们的代理池中随机挑选代理。
在详情页使用try捕获异常,如果产生异常时说明代理失效,从当前代理池中删除
扫描二维码关注公众号,回复:
3084411 查看本文章

完整示例:
from urllib.parse import urlencode
import requests
import json
from bs4 import BeautifulSoup
import random
import time
urls = []
result = []
proxy_auth = []
username = "#########"
password = "#######"
ips = requests.get('http://dps.kdlapi.com/api/getdps/?orderid=#######&num=30&pt=1&format=json&sep=1')
ips_arr = json.loads(ips.text)
for ip in ips_arr['data']['proxy_list']:
proxy_auth_temp = {"http": "http://%(user)s:%(pwd)s@%(ip)s/" % {'user': username, 'pwd': password, 'ip': ip},
"https": "http://%(user)s:%(pwd)s@%(ip)s/" % {'user': username, 'pwd': password, 'ip': ip}}
proxy_auth.append(proxy_auth_temp)
def getAllUrls(page_num,search):
data = {
'uuid':'2a344b34b62b4666af73.1535625802.1.0.0',
'userid':-1,
'limit':32,
'offset':32*page_num,
'cateId':-1,
'q':search,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
url = 'http://apimobile.meituan.com/group/v4/poi/pcsearch/50?'
reponse = requests.get(url,params=data,headers=headers)
data = json.loads(reponse.text)
if data and 'data' in data.keys():
for item in data.get('data').get('searchResult'):
url = 'http://www.meituan.com/shenghuo/'+ str(item.get('id'))+'/'
print(url)
headers = {
'Host': 'www.meituan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
prox = random.choice(proxy_auth)
try:
detail = requests.get(url, proxies=prox,headers=headers,timeout=10)
except requests.RequestException as e:
proxy_auth.remove(prox)
else:
soup = BeautifulSoup(detail.text,'html.parser')
end = {
'seller_name' : soup.select('.seller-name')[0].get_text().strip(),
'address' : soup.select('.seller-info-body .item')[0].get_text().strip(),
'mobile' : soup.select('.seller-info-body .item')[1].get_text().strip(),
# 'time' : soup.select('.seller-info-body .item')[2].get_text().strip(),
}
print(end)
result.append(end)
# exit()
urls.append(url)
time.sleep(3)
def main():
page_counts = 3
search = '鲜花'
for i in range(0,page_counts):
total = getAllUrls(i,search)
if __name__ == '__main__':
main()
# print(json.dumps(result))