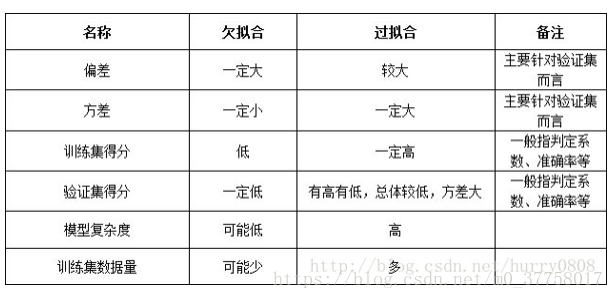
欠拟合-过拟合与偏差-方差关系
过拟合
在训练数据上表现良好,在未知数据上表现差。高方差
模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,使得测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差
解决方法:
1)重新清洗数据
2)增大数据的训练量
3)采用正则化方法,正则化方法包括L0正则、L1正则和L2正则,而正则一般是在目标函数之后加上对于的范数。但是在机器学习中一般使用L2正则
原因:
L0范数是指向量中非0的元素的个数,L1范数是指向量中各个元素绝对值之和
两者都可以实现稀疏性,既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近 似, 而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。
L2范数是指向量各元素的平方和然后求平方根
可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。L2正则项起到使得参数w变小加剧的效果,但是为什么可以防止过拟合呢?一个通俗的理解便是:更小的参数值w意味着模型的复杂度更低,对训练数据的拟合刚刚好(奥卡姆剃刀),不会过分拟合训练数据,从而使得不会过拟合,以提高模型的泛化能力。还有就是看到有人说L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题(具体这儿我也不是太理解)。
4)采用dropout方法,常用于神经网络,在训练的时候让神经元以一定的概率不工作
欠拟合
在训练数据和未知数据上表现都很差,高偏差
解决方法:
1)添加其他特征项,例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段
2)添加多项式特征,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强
3)减少正则化参数,正则化的目的是用来防止过拟合的
正则化Regularization
通过对参数θ的惩罚来影响整个模型
https://blog.csdn.net/jinping_shi/article/details/52433975
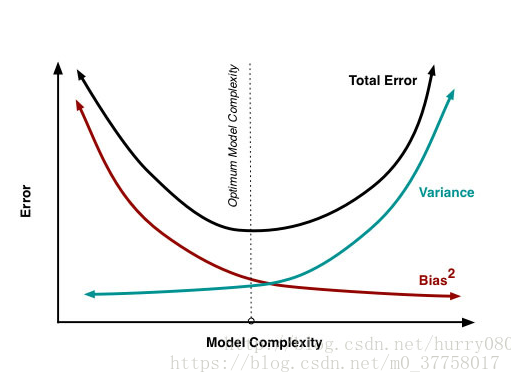
模型的偏差-方差折衷
Error反映的是整个模型的准确度,
Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,
Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
交叉验证
用于防止模型过于复杂而引起的过拟合
一般要尽量满足:
1)训练集的比例要足够多,一般大于一半
2)训练集和测试集要均匀抽样
分类:
1)k-folder cross-validation 十折交叉验证
k个子集,每个子集均做一次测试集,其余的作为训练集。交叉验证重复k次,每次选择一个子集作为测试集,并将k次的平均交叉验证识别正确率作为结果。
优点:所有的样本都被作为了训练集和测试集,每个样本都被验证一次。
10-folder通常被使用
2)K * 2 folder cross-validation
对每一个folder,都平均分成两个集合s0,s1,我们先在集合s0训练用s1测试,然后用s1训练s0测试。
优点:测试和训练集都足够大,每一个个样本都被作为训练集和测试集。
一般使用k=10
3) least-one-out cross-validation(loocv) 留一法
假设dataset中有n个样本,那LOOCV也就是n-CV,意思是每个样本单独作为一次测试集,剩余n-1个样本则做为训练集。
如果有k个样本,则需要训练k次,测试k次。
优点:
1)每一回合中几乎所有的样本皆用于训练model,因此最接近母体样本的分布,估测所得的generalization error比较可靠。
2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
缺点:计算成本高,为需要建立的models数量与总样本数量相同,当总样本数量相当多时,LOOCV在实作上便有困难,除非每次训练model的速度很快,或是可以用平行化计算减少计算所需的时间。
计算最繁琐,但样本利用率最高。适合于小样本的情况。
4) hold -out cross validation 简单交叉验证
步骤如下:
1、 从全部的训练数据 S中随机选择 中随机选择 s的样例作为训练集 train,剩余的 作为测试集 作为测试集 test。
2、 通过对测试集训练 ,得到假设函数或者模型 。
3、 在测试集对每一个样本根据假设函数或者模型,得到训练集的类标,求出分类正确率。
4,选择具有最大分类率的模型或者假设。