
偏差:度量了模型的期望预测和真实结果的偏差, 刻画了模型本身的拟合能力

方差:度量了同样大小的训练集的变动所导致的学习性能的变化, 刻画了数据扰动所造成的影响
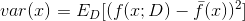

- 低偏差低方差时,是我们所追求的效果,此时预测值正中靶心(最接近真实值),且比较集中(方差小)。
- 低偏差高方差时,预测值基本落在真实值周围,但很分散,此时方差较大,说明模型的稳定性不够好。
- 高偏差低方差时,预测值与真实值有较大距离,但此时值很集中,方差小;模型的稳定性较好,但预测准确率不高,处于“一如既往地预测不准”的状态。
- 高偏差高方差时,是我们最不想看到的结果,此时模型不仅预测不准确,而且还不稳定,每次预测的值都差别比较大。
噪声:表达了当前任务上任何模型所能达到的期望泛化误差的下界, 刻画了学习问题本身的难度
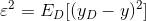
泛化误差就是偏差的期望,可以分解为方差\偏差\噪声之和

偏差-方差分解说明,泛化性能是由学习算法的能力,数据的充分性以及学习任务本身的难度所共同决定。给定学习任务,为了能够取得好的泛化性能,需要使
1)偏差较小,即能够充分的拟合数据;
2)方差较小,即使得数据的扰动产生的影响小。
过拟合Under-Fitting、欠拟合Over-Fitting
- 模型训练不足时,拟合能力不够强,训练数据的扰动(不同训练集之间的差异)不足以使学习器产生显著变化,此时偏差主导泛化误差—欠拟合;
- 模型训练程度加深,拟合能力增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导泛化误差;
- 当训练充足,模型拟合能力非常强,训练数据的轻微不同就能导致学习器的差距很大,若训练数据自身的、非全局的特性被学习器学到了,方差主导泛化误差,就会发生过拟合;