KNN算法是学者Cover和Hart早在1968年提出的算法,最初的最邻近规则分类算法最早也是被用来处理分类的问题,是基于实例的学习(instance-based learning),也叫做懒惰学习(lazy learning),之所以这么说呢,是因为最开始我们并不设计算法的模型,而是基于实例来给他归类。
假设我们有一个电影集,我们有一个任务,来给电影分类。电影有很多类型,如浪漫的,动作片。对于每个电影我们可以把它想象成实例,我们的任务是给他归类,在实例中我们可以提取不同的特征值,在下面的这张图片中我们提取了两个特征值:打斗次数,接吻次数。最终实现对未知电影根据特征值分类。
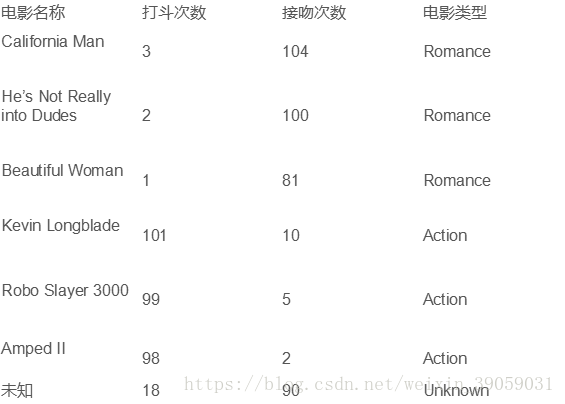
首先我们如何将电影这个例子表达得更像一个数学模型,我们可以表达地如下图所示:
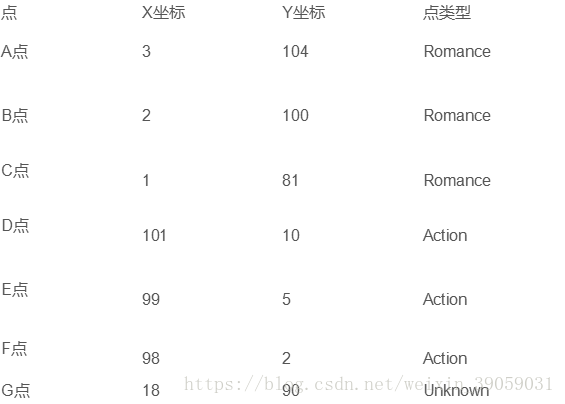
也就是我们可以把每部电影表达为每个实例点,每个点相当于空间中的多维向量,我们的目的是为了将其归类。
KNN算法祥述:
为了判断未知实例的类别,以所有已知类别的实例作为参考,选择参数K,计算未知实例与所有已知实例的距离,选择最近K个已知实例,根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多的类别。举个例子来说呢就是:

假设我们有一个豆子A,我们不知道他是哪一类的,我们根据已知的这三类豆子给他进行分类。我们选择最近的K个豆子,假设K=3,那么我们就看这最近的三个豆子属于哪一类,并根据少数服从多数的投票法则来判断这个豆子A的类别。
细节:
K如何选取?我们可以依据训练时候的准确度来选取。
关于距离的衡量方法:
Euclidean Distance(欧几里得距离)
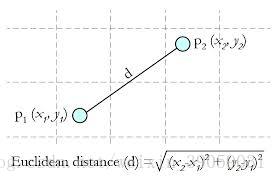
其他距离衡量:余弦值(cos),相关度(correlation),曼哈顿距离(Manhanttan distance)
以上面所讲的电影的数据集为例,介绍一下具体的算法工作流程:
1. 算G点到A、B、C、D、E、F,点的距离,程序计算欧几里得距离如下(以A和G点之间的距离为例):
import math
def ComputeEuclideanDistance(x1, y1, x2, y2):
d = math.sqrt(math.pow((x1 - x2), 2) + math.pow((y1- y2), 2))
return d
d_ag = ComputeEuclideanDistance(18, 90, 3, 104)
print(d_ag)
2. 之后的话我们选取三个距离最小的三个临近豆子,看这三个临近豆子属于哪一类,用少数服从多数的原则判别出这个豆子的种类。
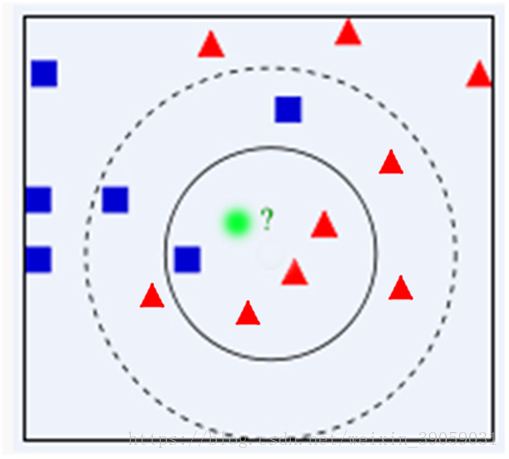
KNN的算法对K的选择非常敏感,如下图所示:
算法优点:简单;易于理解;容易实现;通过对K的选择可具备丢噪音数据的健壮性。
算法缺点:需要大量空间存储所有已知实例;算法复杂度高(需要比较所有已知实例与要分类的实例);当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例并不接近目标样本。
Python实现:
from sklearn import neighbors
from sklearn import datasets
# 调用KNN的分类器
knn = neighbors.KNeighborsClassifier()
# 加载数据库
iris = datasets.load_iris()
# 打印数据集 包含一个四维的特征值和其对应的标签
print(iris)
knn.fit(iris.data, iris.target)
# 预测[0.1, 0.2, 0.3, 0.4]属于哪一类
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
# 打印出预测的标签
print(predictedLabel)