本章内容概要:
- 机器学习基础
- 相比传统方法机器学习的优势
- 机器学习流程概览
- 模型性能优化方法综述
1959年,IBM工程师Arthur Samuel 编写了一个玩跳棋的程序。他为棋盘上的每一个格子都根据获胜的概率赋予一定的分数。其中,分数是根据一些因素计算出来的,例如,可以根据双方的棋子数、国王的数量。尽管这个反方很有效果,但是Samuel 让程序进行了上千场的自我博弈,并利用结果进行重新定义分数。20世纪中期,该程序的能力已经达到了一个高级业余棋手的水平。
Samuel 通过让程序进行自我学习提高机器下棋的水平,这既是机器学习。本书的目的不是详细阐述机器学习算法的细节。相反,本书的目的是将机器学习更好的融入现实生活中。首先在第一章中展现了真实的商业例子-贷款申请审查,并与传统的方法进行对比以展现机器学习的优势。
理解机器是如何学习的
当我们讨论到人类学习的时候,会谈到机械学习、死记硬背甚至是智商。尽管记忆一些电话号码或指令可以称为学习,但是学习通常不止这些。
当小孩们一起玩耍的时候,他们会观测其他人对自己行为的反应。这些学习观察会对他们未来的行为产生影响。因此,学习不仅是指知识的收集,也是孩子们建立社会洞察力的过程。
试想一下,在通过卡片教小孩区别猫和狗的时候,你展示一张卡片,小孩做出选择,然后根据小孩的选择将选择正确和错误的卡片分开放置。随着孩子的不断练习,区分猫和狗的能力越来越强。有趣的是,该过程并没有实现交给孩子什么是猫和狗。人类的认知能力中内置分类功能,在小孩熟悉卡片上的猫狗之后,他不仅可以对卡片上的图片进行识别,同时也可对其他地方的猫狗进行分类。这种通过学习已知知识并泛化到未学习的领域,这是人类和机器学习的关键特征。
当然,人类的学习过程远比现有高级算法复杂的多。但是,计算机有更强大的“记忆”、“回忆”、“处理”能力,可以利用本书介绍的技术从历史数据中学习到知识。
人类学习和机器学习之间的类比会让人联想到人工智能(AI)这个术语。一个显而易见的问题是,AI和机器学习的区别是什么?对于这个问题,目前还没有明确的共识,大多数的观点是:ML是人工智能的一种形式,人工智能是涵盖机器人、自然语言处理、计算机视觉等领域更广泛的学科。目前,机器学习也被广泛的应用于这些相近的人工智能领域。也可以说,机器学习指的是一个特定的知识体和相关技术的组合。对于什么是机器学习,什么不是机器学习可以有很明确的判定,但是对于什么是人工智能就不能这样理解,就像Tom Mitchell经常引用的定义所说:“人工智能就是一组完成特定任务的计算机程序,并且会随着经验的增加而提高性能”。
就像Kaggle上的猫狗识别大赛,参赛者根据比赛方提供的12500张已知类别的图片进行模型训练,并用12500张无标签数据对模型进行测试。
当我们像被人介绍kaggle的猫狗识别大赛的时候,人们通常会想到去寻找可能适用于区分猫狗的规则,比如猫的耳朵是三角形的,而且是竖起来的,而狗的耳朵则是耷拉的。但是,这些规则在很多情况下并不成立。试想一下,一个从未见过猫狗的人是如何辨别猫狗的?
人们可以使用包括形状、颜色、纹理以及比例等特征进行学习,并从实例中进行一定的推广。机器学习亦是如此,利用各种规则策略的组合完成既定任务的学习。
这些策略可以由进几十年来发展的统计学、计算机科学、机器人学以及相关算法中体现,并广泛的应用于在线搜索、娱乐、数字广告、语言翻译等场景中。不同的策略各有特点,有的用于分类任务,而有的是用于预测一个数值,还有一些则是用于度量实例之间的异同(人,猫,狗,过程,机器等)。而这些策略(算法)也就是从这些实例中学习到知识,并将学习到的知识用于未知的实例。
在猫狗识别大赛中,参赛者在模型训练阶段,尝试各种算法以提高模型的分类性能。算法在迭代过程中不断的执行分类计算,结果验证,模型调整以不断的提高模型的性能。大赛的获胜者以测试数据分类准确98.914%的准确率高居榜首。考虑到人眼识别的误差在7%左右,这个结果是相当不错的。图1.1为整个识别流程,通过对有标签的数据进行分析,并利用机器学习方法构建模型,实现没有标签数据的预测。图中有一只猫是误分类的。
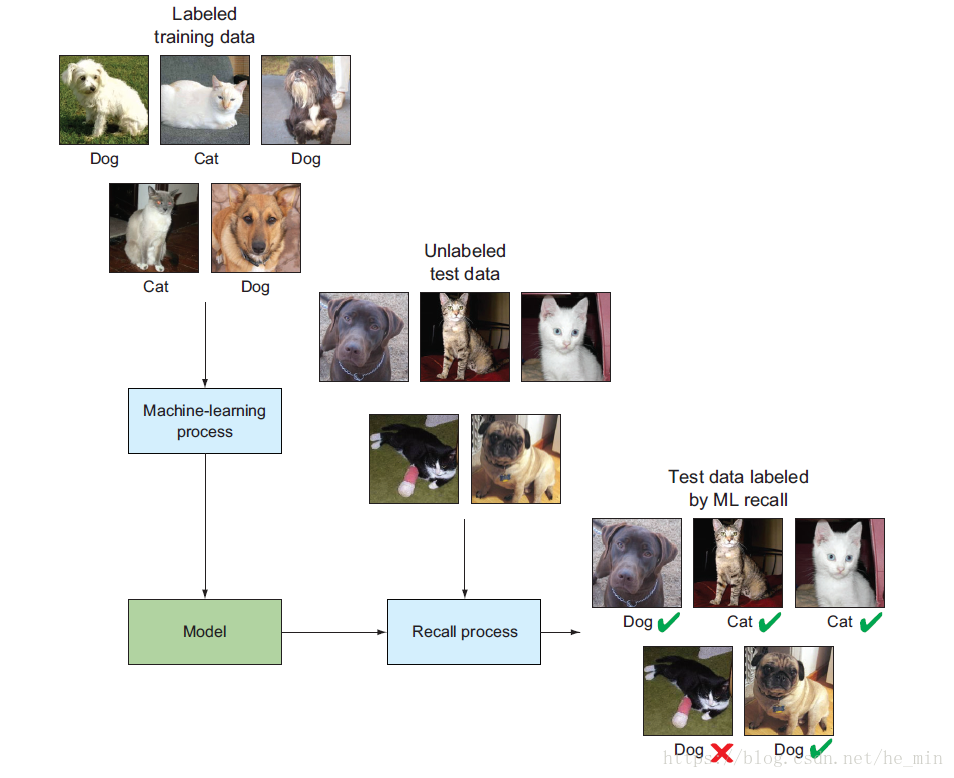
图1-1 机器学习在猫狗识别中的流程
这里需要注意的是,该流程仅为机器学习中的一种—监督学习,其他的方式将会在后续章节中进行介绍。
机器学习可以被广泛的应用于商业领域,从欺诈检测到客户定位与个性化产品推荐,从实时工业检测到情感分析与医疗诊断。机器学习可以处理那些因为数据量太大,人工无法合理分析的问题,当数据量很大的时候,机器学习会分析数据之间的关系,并将这些“弱”的关系组合起来形成强有力的预测因子。
从数据中学习知识,并将知识应用于未知数据上,是非常强大的,事实上,机器学习也正在迅速成为推动数据驱动经济的引擎。
表1-1描述了广泛应用于有监督机器学习的技术以及实例。
| 问题 | 描述 | 案例 |
|---|---|---|
| 分类 | 根据输入数据确定每个样本所属的类别 | 垃圾邮件过滤、情感分析、欺诈检测、客户广告定位、客户流失预测、支持案例标记、内容个性化、制造缺陷检测、客户细分、事件发现、基因组学、药物功效 |
| 回归 | 根据输入数据对每个样本进行连续值预测 | 股票预测,价格估计,需求预测,风险管理,天气预报,体育预测 |
| 推荐 | 在候选内容中选择更合适的 | 商品推荐,招聘,在线约会内容推荐 |
| 补值 | 对缺失值进行填补 | 病人病历数据不完整,客户数据缺失,人口数据普查 |
利用数据作出决策
如下例子是现实生活中真实的受益于机器学习的商业例子,并与其他方法进行对比以展示ML的优势。
如果你负责一家小额信贷公司,想对一些社区中陷入困难但想创办企业的人提供贷款,早期的时候,每周仅有几个申请,你可以亲自阅读这些申请,并对每位申请者进行背景调查,以此来决定是否放贷。整个流程如图1.2所示,你的客户因为你的审理周期短,以及周到的服务感到满意,公司的名誉远播四方。
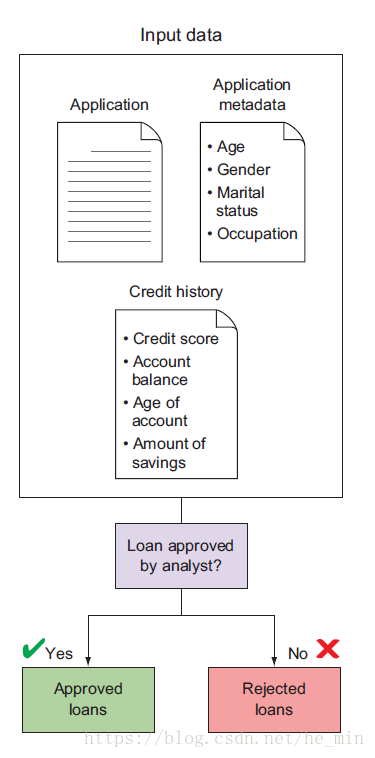
图1-2 小额贷款审批流程
随着公司声誉的传播,申请贷款的数量开始增加,你每周将会收到数百份申请书,你试图通过加班来对这些申请进行审核,但是申请书却在不断的积累,那些申请人厌倦了等待,并寻找竞争对手寻求贷款。很显然,手动对每个申请进行处理并不是很好的可持续发展战略。
那么我们该怎么办呢?在下面的章节中,你将对一些可以促进业绩的方法进行探索。
传统方法
我们对两种传统审核方法进行探讨:(1)手工分析;(2)业务规则。对于每种方法,我们均介绍其实现过程,并对它无法实现业务的扩展进行阐述。
- 雇佣更多的分析师
你决定雇一个分析师帮你进行申请审核,你不得不把部分利润分给新员工。使用第二个人进行申请审核,可以将你的审核速度提升一倍,这样你可以在一周内减少一定的积压量。在前两周,两个人一起工作仍然不能满足业务的增长,然而申请的数量依然在翻番的增长。为了赶上业务的增长速度,你不得不雇佣更多的人,试想一下未来,这种模式并不是可持续发展的。你从新的贷款申请者中获取的利润会直接分配给你的雇员,而不是信贷业务的发展。随着业务需求的增长,雇佣更多的员工会阻碍你业务的增长,此外你还会发现,招聘分析师的过程成本高昂。而且随着团队的扩大,新员工在处理类似事件的经验不比老员工,团队管理的压力也会变的更大。
处理增加成本这一明显缺陷之外,人们在决策过程中也会有一定的偏见,为了确保决策的一致性,你可以制作审批处理流程,并为分析师提供培训,然而不仅会增加成本且并不能完全消除偏见。
- 制定分析规则
试想一下,1000个贷款已经逾期,仅有70%的贷款能及时的偿还,由图1-3所示:
图1-3 几个月后,有2500个贷款申请,其中1000个是批准的,其中700个可以按时还款,剩余300个则逾期,这些观测信息对以后的自动化操作有至关重要的作用
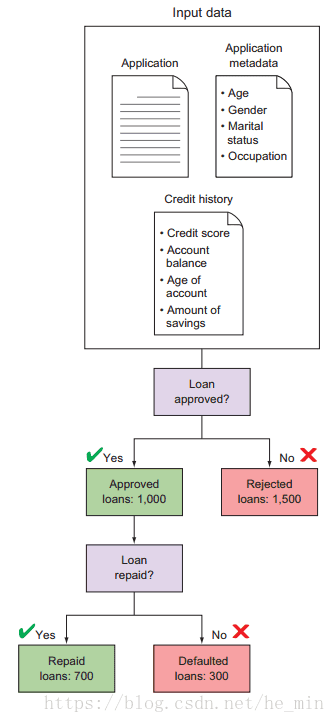
目前你在寻找申请数据和贷款偿还率之间的关系,实际上,你正在一大堆数据里寻找一个过滤规则,从而找到那些可以及时偿还的贷款。通过人工分析上百份的申请信息,你可以获得判别申请好坏的经验,并通过自我反省与反馈测试,你在信贷背景下的数据中找到了一些规律。
- 信用额度超过$7500的申请者大多拖欠贷款
- 大多数不能及时还款的借款人没有支票账户
现在你可以设计上述过滤机制来削掉不满足上述规则的申请者。
你的第一条规则自动拒绝了很多信用额度超过$7500的申请者,通过观测历史数据,你发现,86个申请中有44个申请者的信用额度超过了 $7500 大约有51%具有高额信用额度的申请者逾期,28%归还,这条规则看起来是条不错的规则来排除一些高风险的申请者。但是,你意识到仅有8.6%(1000中的86个)的申请者具有如此高的额度,意味着你还得手动处理90%的申请,你需要做更多的过滤工作来使得你的工作量下降。
你的第二条规则自动的批准那些没有支票的申请者,这看起来是条不错的规则,但是在394个申请者中有348个没有支票账户(88%)这两条判断规则。根据这两条新制定的规则,可以自动的接受或者拒绝45%的申请,因此,你需要手工分析一半的申请信息,图1-4可以详细的看出这两条过滤规则。
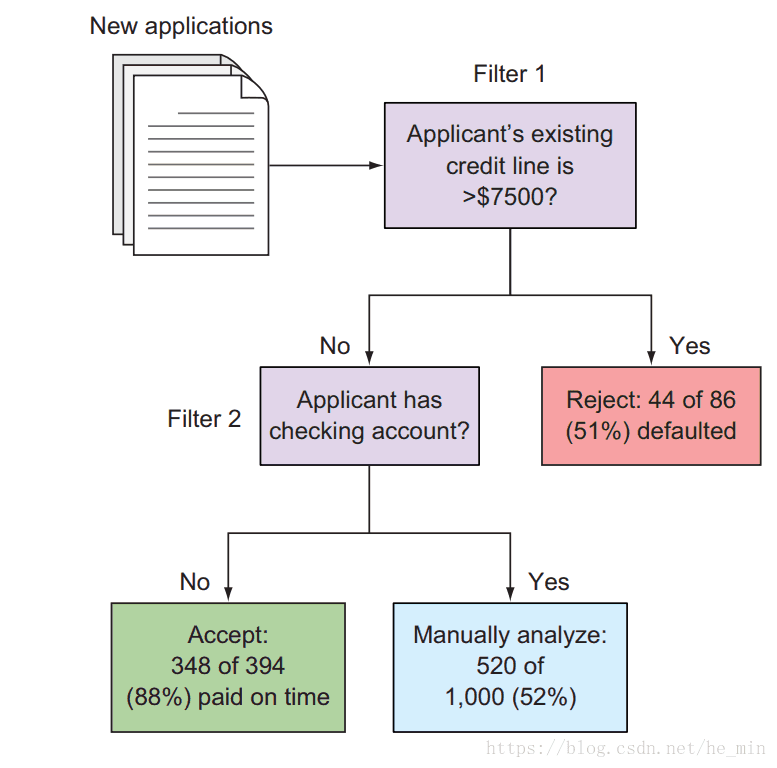
图1-4 根据两条规则,还有52%的申请信息需要手工处理
根据这两条规则,你不但不需要雇分析师,还可以将生意扩大两倍,因为你仅需手工判断52%的申请者。除此之外,在知道这1000人的结果之后,你期望你的过滤机制可以达到4.2%的假阴率和4.6的假阳率。
随着业务的扩大,你期望你的系统可以在没有增加错误率的前提下,自动的接受或者拒绝大量的申请。为此,你需要添加更多的规则。但是你很快发现了一些问题:
- 人工发现规则是越来越难,如果不是不可能,系统会越来越复杂
- 商业规则变得如此复杂和不透明,以至于调试和分裂这些规则变得不现实
- 你构造的规则并没有严格的统计,虽然你认为这些规则可以有效的,但是并不能得到有效的证明
- 随着时间的改变,信贷模式可能发生改变,系统也需要随着进行改变。
所有的这些缺点都可以归结为虚弱的商业规则方法。
数据驱动模型,从简单的统计学习模型到更复杂的机器学习工作流都可以克服上述的问题。