第一眼看到逻辑回归(Logistic Regression)这个词时,脑海中没有任何概念,读了几页后,发现这非常类似于神经网络中单个神经元的分类方法。
书中逻辑回归的思想是用一个超平面将数据集分为两部分,这两部分分别位于超平面的两边,且属于两个不同类别(和SVM的想法有些相似),如下图:

因此,一般的逻辑回归只能处理两分类问题,同时两个类别必须是线性可分的。对于线性不可分问题,在SVM中,可以使用核函数升维的方式解决,不过那都是后话了。还是先看看逻辑回归吧。
一、Sigmoid函数
了解神经网络的朋友想必不会对这个东西陌生,在神经网络中它就是所谓的激励函数,其最常用的一种表现形式如下:
函数曲线如下:
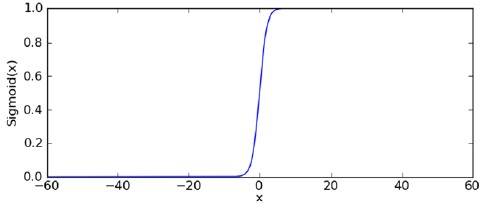
很显然它是对阶跃函数的一个很好的近似,当输入大于零时,输出趋近于1,输入小于零时,输出趋近于0,输入为0时,输出刚好为0.5。
在逻辑回归中,训练和分类所用数据的取值范围是任意的,因此我认为,Sigmoid在逻辑回归中除了有分类作用外,最主要作用是将数据映射到0和1之间,之后我会说明具体原因。
二、超平面与梯度上升(下降)
作为分界面的超平面定义如下:
其中可取x0 = 1,即将w0作为一个常量偏移。
通过该式可以计算得到一个z值,这个z值将作为Sigmoid函数的输入,其输出大于0.5和小于0.5分别表示两个不同的类别,也即实现了两分类。现在的问题是,给定一组训练数据,如何求出超平面中的系数,即w。
我们使用梯度上升算法进行优化求解。了解神经网络的朋友对梯度上升或梯度下降应该也很熟悉吧。一个函数的梯度定义为:
注意,这里并不是f(w)的导数,其中的w是一个向量,因此上式代表对w中每一个元素求偏导。
梯度是有方向的,总是指向函数值上升最快的方向,因此当我们沿着梯度方向或反方向行进时,就能达到一个函数的最大值或最小值处。因此,梯度上升算法就是根据下式不断更新w,直到梯度没有变化或变化很小,即函数达到了最大值:
其中alpha为沿着梯度行进的步长。
也许有人会问,如何用代码求函数的梯度,在Machine Learning In Action一书中,作者没有解释,直接写出了以下几行代码:
h = sigmoid(dataMatrix*weights) error = (labelMat - h) weights = weights + alpha * dataMatrix.transpose()* error
从代码可以看出,作者用误差值error乘以输入数据矩阵的转置代表梯度,这里我就来尝试推导一下这个等式吧。
首先说明,我们的这个分类问题,可以等效为一个最小二乘问题,设:
其中A是包含训练数据的矩阵,也就是上面代码中的dataMatrix,w是我们要求的系数,而b是我们期望的每个训练样本乘以w后应该有的值,比如我们希望输入这个样本后,Sigmoid函数输出1,那么就应该期望这个样本乘以w后的值大于零,比如说20 。
要达到最好的分类,必然希望Aw中的每一项都接近b中的对应项,即要使下式达到最小:
这就是我们要优化的函数,于是对其求梯度,有:
由梯度的定义知:
由矩阵的微分方法可知(具体过程略):
最后合在一起可得:
其中(Aw - b)正好就是实际输出值与期望值的误差,前面的系数2和步长alpha合并,就得到了上面代码中所用的公式。
现在也可以解释用Sigmoid函数映射数据的作用了,如果不用Sigmoid函数,训练样本中的取值可能较大,因此误差值error也会较大,将这样的error值带入上式后,就会造成w的剧烈变化,最后甚至难以收敛,因此在代码中,作者将dataMatrix*weights的结果送入Sigmoid后才得到用于计算误差的输出结果,同时由于Sigmoid的使用,期望值b就和Label的值一样了(0和1),对代码的编写还起到简化作用。
以上是我的个人理解,如有错误或不严密的地方,还请指出!
三、代码实现
到具体实现代码时,以上算法就有一些问题了,首先,以上算法的步长值alpha是固定的,太小会使算法收敛很慢,太大又有不能收敛的可能。其次,以上算法的结果往往在一个最佳值附件来回震荡。为此我们使用随机梯度上升算法,在神经网络中也被称为LMS(最小均方)算法。
随机梯度上升算法与普通梯度上升算法不同在于,更新w时不使用全部训练样本,而只是从中随机选择一个样本来计算误差并更新w,这样通过多次迭代,每次都随机选择不同的样本,最终w趋于收敛,且结果与普通梯度上升算法没有差别,这种方式可以抑制结果的来回震荡。同时,使用可变的步长,使步长alpha随着迭代次数的增加而减小,这样可使算法在刚开始时,快速沿着梯度前进,当接近最佳值时,alpha减小,保证算法能正确收敛到最佳值上,从而在总体上加快算法的收敛速度。
由于随机梯度上升算法每次只取一个样本,和样本总体无关,所以它还是一种支持在线学习的算法。所谓在线就是指能实时处理新加入的训练数据,而不必从新将所有数据又处理一遍。
下面给出C#版本的实现:
class LogisticRegressiond
{
private double[] m_weights;
public double[] Weights
{
get { return m_weights; }
}
private double Sigmoid(double input)
{
return 1 / (1 + Math.Exp(-input));
}
/// <summary>
/// Use stochastic gradient descent\ascent method to train a binary classifier.
/// </summary>
/// <param name="samples">Samples used to train the classifier.</param>
/// <param name="labels">Binary labels corresponding to samples.</param>
/// <param name="iteration_count">Iteration count</param>
/// <param name="online">Specify whether use the online training method.</param>
/// <param name="max_step">Max step size.</param>
/// <param name="min_step">Min step size.</param>
public void Train(List<double[]> samples, bool[] labels, int iteration_count = 150, bool online = false, double max_step = 4.0, double min_step = 0.01)
{
if (samples.Count != labels.Length)
throw new ArgumentException("'samples' has different count with 'labels'");
double[] weights = new double[samples[0].Length];
if (online && m_weights != null)
{
if (m_weights.Length != weights.Length)
{
throw new ArgumentException("Sample length is different with the previous samples'");
}
m_weights.CopyTo(weights, 0);
}
else
{
weights.AllSetToOne();
}
Random rand = new Random();
for (int i = 0; i < iteration_count; i++)
{
for (int j = 0; j < samples.Count; j++)
{
double alpha = max_step / (1 + i + j) + min_step;
int rand_index = rand.Next(samples.Count);
double[] sample = samples[rand_index];
sample.Multiply(weights);
double res = Sigmoid(sample.ElementsSum());
double error = res - (labels[rand_index] ? 1.0 : 0.0);
sample.Multiply(alpha * error);
weights.Plus(sample);
samples.RemoveAt(rand_index);
}
}
m_weights = weights;
}
public bool Classify(double[] vector)
{
if (m_weights == null)
throw new AccessViolationException("Classifier has not been trained yet.");
vector.Multiply(m_weights);
double res = Sigmoid(vector.ElementsSum());
return res > 0.5;
}
}
最后总结一下逻辑回归的优缺点。
优点:
1、实现简单;
2、分类时计算量非常小,速度很快;
3、所需存储资源极低;
缺点:
1、容易过拟合;
2、准确度可能不高;
3、只能处理两分类问题,且必须线性可分;