一、机器学习概览
为什么使用机器学习?
机器学习善于:
- 需要进行大量手工调整或需要拥有长串规则才能解决的问题:机器学习算法通常可以简化代码、提高性能。
- 问题复杂,传统方法难以解决:最好的机器学习方法可以找到解决方案。
- 环境有波动:机器学习算法可以适应新数据。洞察复杂问题和大量数据
机器学习系统的类型
机器学习可以根据训练时监督的量和类型进行分类。主要有四类:监督学习、非监督学习、半监督学习和强化学习。
监督学习

一个典型的监督学习任务是分类。垃圾邮件过滤器就是一个很好的例子:用许多带有归类(垃圾邮件或普通邮件)的邮件样本进行训练,过滤器必须还能对新邮件进行分类。另一个典型任务是预测目标数值,例如给出一些特征(里程数、车龄、品牌等等)称作预测值,来预测一辆汽车的价格。
下面是一些重要的监督学习算法(本书都有介绍):
- K近邻算法
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
非监督学习
在非监督学习中,训练数据是没有加标签的,系统在没有老师的条件下进行学习。

下面是一些最重要的非监督学习算法(我们会在第 8 章介绍降维):
聚类
K 均值
层次聚类分析(Hierarchical Cluster Analysis,HCA)
期望最大值
可视化和降维
主成分分析(Principal Component Analysis,PCA)
核主成分分析
局部线性嵌入(Locally-Linear Embedding,LLE)
t-分布邻域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE)
关联性规则学习
Apriori 算法
Eclat 算法
聚类:例如,假设你有一份关于你的博客访客的大量数据。你想运行一个聚类算法,检测相似访客的分组。例如,算法可能注意到 40% 的访客是喜欢漫画书的男性,通常是晚上访问,20% 是科幻爱好者,他们是在周末访问等等。如果你使用层次聚类分析,它可能还会细分每个分组为更小的组。这可以帮助你为每个分组定位博文。

可视化算法也是极佳的非监督学习案例:给算法大量复杂的且不加标签的数据,算法输出数据的2D或3D图像(图 1-9)。算法会试图保留数据的结构(即尝试保留输入的独立聚类,避免在图像中重叠),这样就可以明白数据是如何组织起来的,也许还能发现隐藏的规律。

t-SNE 可视化案例,突出了聚类(注:注意动物是与汽车分开的,马和鹿很近、与鸟距离远,以此类推)
降维:降维的目的是简化数据、但是不能失去大部分信息。做法之一是合并若干相关的特征。例如,汽车的里程数与车龄高度相关,降维算法就会将它们合并成一个,表示汽车的磨损。这叫做特征提取。
提示:在用训练集训练机器学习算法(比如监督学习算法)时,最好对训练集进行降维。这样可以运行的更快,占用的硬盘和内存空间更少,有些情况下性能也更好。
另一个重要的非监督任务是异常检测(anomaly detection) —— 例如,检测异常的信用卡转账以防欺诈,检测制造缺陷,或者在训练之前自动从训练数据集去除异常值。异常检测的系统使用正常值训练的,当它碰到一个新实例,它可以判断这个新实例是像正常值还是异常值

最后,另一个常见的非监督任务是关联规则学习,它的目标是挖掘大量数据以发现属性间有趣的关系。例如,假设你拥有一个超市。在销售日志上运行关联规则,可能发现买了烧烤酱和薯片的人也会买牛排。因此,你可以将这些商品放在一起。
半监督学习
一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上小部分带标签数据。这称作半监督学习
一些图片存储服务,比如 Google Photos,是半监督学习的好例子。一旦你上传了所有家庭相片,它就能自动识别相同的人 A 出现了相片 1、5、11 中,另一个人 B 出现在了相片 2、5、7 中。这是算法的非监督部分(聚类)。现在系统需要的就是你告诉这两个人是谁。只要给每个人一个标签,算法就可以命名每张照片中的每个人,特别适合搜索照片。
多数半监督学习算法是非监督和监督算法的结合。例如,深度信念网络(deep beliefnetworks)是基于被称为互相叠加的受限玻尔兹曼机(restricted Boltzmann machines,RBM)的非监督组件。RBM 是先用非监督方法进行训练,再用监督学习方法进行整个系统微调。
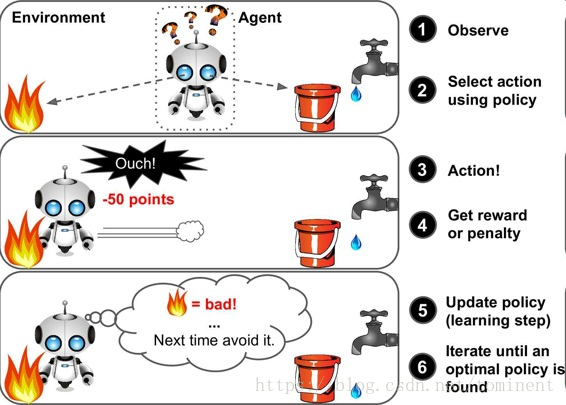
强化学习
强化学习非常不同。学习系统在这里被称为智能体(agent),可以对环境进行观察,选择和执行动作,获得奖励(负奖励是惩罚)。然后它必须自己学习哪个是最佳方法(称为策略,policy),以得到长久的最大奖励。策略决定了智能体在给定情况下应该采取的行动。
批量和在线学习
它是否能从导入的数据流进行持续学习。
批量学习
在批量学习中,系统不能进行持续学习:必须用所有可用数据进行训练。这通常会占用大量时间和计算资源,所以一般是线下做的。首先是进行训练,然后部署在生产环境且停止学习,它只是使用已经学到的策略。这称为离线学习。
如果你想让一个批量学习系统明白新数据(例如垃圾邮件的新类型),就需要从头训练一个系统的新版本,使用全部数据集(不仅有新数据也有老数据),然后使用新系统替换老徐他。幸运的是,训练、评估、部署一套机器学习的系统的整个过程可以自动进行,所以即便是批量学习也可以适应改变。只要有需要,就可以方便地更新数据、训练一个新版本。但是用全部数据集进行训练会花费大量时间,所以一般是每 24 小时或每周训练一个新系统。如果系统需要快速适应变化的数据(比如,预测股价变化),就需要一个响应更及时的方案。
另外,用全部数据训练需要大量计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O 等等)。如果你有大量数据,并让系统每天自动从头开始训练,就会开销很大。如果数据量巨大,甚至无法使用批量学习算法。
最后,如果你的系统需要自动学习,但是资源有限(比如,一台智能手机或火星车),携带大量训练数据、每天花费数小时的大量资源进行训练是不实际的。
幸运的是,对于上面这些情况,还有一个更佳的方案可以进行持续学习。
在线学习
注意在线学习整个过程通常是离线完成的,即不在部署的系统上,也称为持续学习,在在线学习中,是用数据实例持续地进行训练,可以一次一个或一次几个实例(称为小批量)。每个学习步骤都很快且廉价,所以系统可以动态地学习到达的新数据。
在线学习很适合系统接收连续流的数据(比如,股票价格),且需要自动对改变作出调整。如果计算资源有限,在线学习是一个不错的方案:一旦在线学习系统学习了新的数据实例,它就不再需要这些数据了,所以扔掉这些数据(除非你想滚回到之前的一个状态,再次使用数据)。这样可以节省大量的空间。

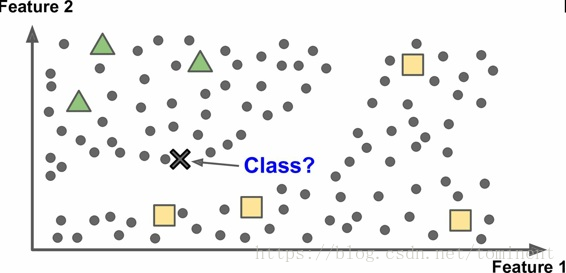
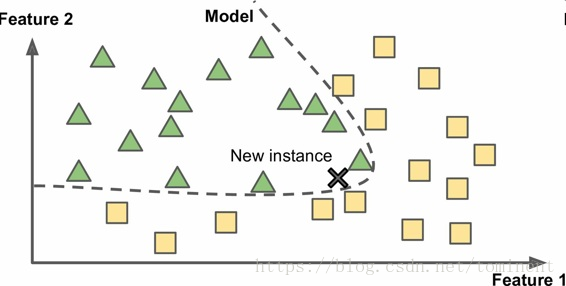
基于实例 vs 基于模型学习
实例:最简单的学习形式就是用记忆学习。如果用这种方法做一个垃圾邮件检测器,只需标记所有和用户标记的垃圾邮件相同的邮件,测量两封邮件的相似性。一个(简单的)相似度测量方法是统计两封邮件包含的相同单词的数量。如果一封邮件含有许多垃圾邮件中的词,就会被标记为垃圾邮件。这被称作基于实例学习:系统先用记忆学习案例,然后使用相似度测量推广到新的例子

模型学习:另一种从样本集进行归纳的方法是建立这些样本的模型,然后使用这个模型进行预测。这称
作基于模型学习
机器学习的主要挑战
训练数据量不足
机器学习需要大量数据,才能让多数机器学习算法正常工作。即便对于非常简单的问题,一般也需要数千的样本,对于复杂的问题,比如图像或语音识别,你可能需要数百万的样本(除非你能重复使用部分存在的模型)。
样本偏差
指的是在研究过程中因样本选择的非随机性而导致得到的结论存在偏差,也称选择性偏差为选择性效应(Selection Effect)。这会严重降低学得模型的泛化能力。
低质量数据
很明显,如果训练集中的错误、异常值和噪声(错误测量引入的)太多,系统检测出潜在规律的难度就会变大,性能就会降低。花费时间对训练数据进行清理是十分重要的。事实上,大多数据科学家的一大部分时间是做清洗工作的。
不相关的特征
俗语说:进来的是垃圾,出去的也是垃圾。你的系统只有在训练数据包含足够相关特征、非相关特征不多的情况下,才能进行学习。机器学习项目成功的关键之一是用好的特征进行训练。这个过程称作特征工程,包括:
- 特征选择:在所有存在的特征中选取最有用的特征进行训练。
- 特征提取:组合存在的特征,生成一个更有用的特征(如前面看到的,可以使用降维算法)。
- 收集新数据创建新特征。
过拟合
通俗一点地来说过拟合就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差。
解决方法:
- 重新清洗数据
- 增大数据的训练量
- 正则化方法
- Early stopping、dropout方法(在神经网络里面很常用)
欠拟合
欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
解决方法:
- 添加其他特征项
- 添加多项式特征
- 减少正则化参数
测试和确认
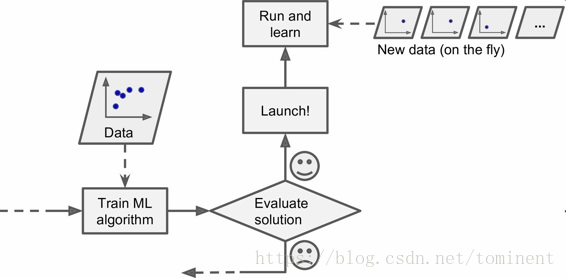
要知道一个模型推广到新样本的效果,唯一的办法就是真正的进行试验。一种方法是将模型部署到生产环境,观察它的性能。这么做可以,但是如果模型的性能很差,就会引起用户抱怨 —— 这不是最好的方法。
更好的选项是将你的数据分成两个集合:训练集和测试集。正如它们的名字,用训练集进行训练,用测试集进行测试。对新样本的错误率称作推广错误(或样本外错误),通过模型对测试集的评估,你可以预估这个错误。这个值可以告诉你,你的模型对新样本的性能。
如果训练错误率低(即,你的模型在训练集上错误不多),但是推广错误率高,意味着模型对训练数据过拟合。
提示:一般使用 80% 的数据进行训练,保留20%用于测试。
因此,评估一个模型很简单:只要使用测试集。现在假设你在两个模型之间犹豫不决(比如一个线性模型和一个多项式模型):如何做决定呢?一种方法是两个都训练,,然后比较在测试集上的效果。
现在假设线性模型的效果更好,但是你想做一些正则化以避免过拟合。问题是:如何选择正则化超参数的值?一种选项是用 100 个不同的超参数训练100个不同的模型。假设你发现最佳的超参数的推广错误率最低,比如只有 5%。然后就选用这个模型作为生产环境,但是实际中性能不佳,误差率达到了 15%。发生了什么呢?答案在于,你在测试集上多次测量了推广误差率,调整了模型和超参数,以使模型最适合这个集合。这意味着模型对新数据的性能不会高。
这个问题通常的解决方案是,再保留一个集合,称作验证集合。用训练集和多个超参数训练多个模型,选择在验证集上有最佳性能的模型和超参数。当你对模型满意时,用测试集再做最后一次测试,以得到推广误差率的预估。
为了避免“浪费”过多训练数据在验证集上,通常的办法是使用交叉验证:训练集分成互补的子集,每个模型用不同的子集训练,再用剩下的子集验证。一旦确定模型类型和超参数,最终的模型使用这些超参数和全部的训练集进行训练,用测试集得到推广误差率。
QA
9.在线学习系统可以逐步学习,而不是批量学习 - 系统。这使它能够快速适应不断变化的数据和自治系统,以及对大量数据的培训。
10.核外算法可以处理大量不适合的数据电脑的主存。核外学习算法将数据切入小批量和使用在线学习技术来学习这些迷你批次。
12.机器学习中参数和超参数之间的区别
答:一个模型具有一个或多个模型参数,这些参数决定了在给定新实例(例如,线性模型的斜率)的情况下它将会预测的内容。学习算法试图找到这些参数的最佳值,以使该模型很好地适用于新实例。而超参数是学习算法本身的参数,而不是模型的参数(例如,神经网络的层数和每层结点数量)。
19.什么是交叉验证,使用验证集的好处有什么?
交叉验证是一种技术,可以比较模型(用于模型选择和超参数调整),而不需要单独的验证集,这节省了宝贵的训练数据。同时,如果使用测试集作为验证集时,当模型过拟合,将可能上线一个泛化能力很差的模型,影响到用户。