目录
@
1 知识回顾
1.1 梯度下降法
导数:一个函数在某一点的导数描述了这个函数在这一点附近的变化率,也可以认为是函数在某一点的导数就是该函数所代表的曲线在这一点的切线斜率。导数值越大,表示函数在该点处的变化越大。
梯度:梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向取的最大值,即函数在该点处沿着该方向变化最快,变化率最大(即该梯度向量的模);当函数为一维函数的时候,梯度其实就是导数。
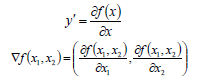
梯度下降法(Gradient Descent, GD)常用于求解无约束情况下凸函数(Convex Function)的极小值,是一种迭代类型的算法,因为凸函数只有一个极值点,故求解出来的极小值点就是函数的最小值点。
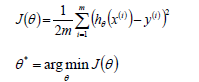
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以梯度下降法也被称为“最速下降法”。梯度下降法中越接近目标值,变量变化越小。计算公式如下:
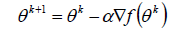
α被称为步长或者学习率(learning rate),表示自变量x每次迭代变化的大小。
收敛条件:当目标函数的函数值变化非常小的时候或者达到最大迭代次数的时候,就结束循环。
1.2 拉格朗日乘子法
拉格朗日乘子法就是当我们的优化函数存在等值约束的情况下的一种最优化求解方式;其中参数α被称为拉格朗日乘子,要求α不等于0。
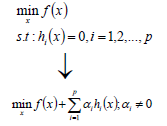
1.2.1 对偶问题
在优化问题中,目标函数f(x)存在多种形式,如果目标函数和约束条件都为变量x的线性函数,则称问题为线性规划;如果目标函数为二次函数,则称最优化问题为二次规划;如果目标函数或者约束条件为非线性函数,则称最优化问题为非线性优化。每个线性规划问题都有一个对应的对偶问题。对偶问题具有以下几个特性:
- 对偶问题的对偶是原问题;
- 无论原始问题是否是凸的,对偶问题都是凸优化问题;
- 对偶问题可以给出原始问题的一个下界;
- 当满足一定条件的时候,原始问题和对偶问题的解是完美等价的。
1.3 KKT条件
KKT条件是泛拉格朗日乘子法的一种形式;主要应用在当我们的优化函数存在不等值约束的情况下的一种最优化求解方式;KKT条件即满足不等式约束情况下的条件。
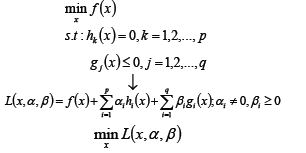
KKT条件理解:参考链接
- 可行解必须在约束区域g(x)之内,由图可知可行解x只能在g(x)<0和g(x)=0的区域取得;
- 当可行解x在g(x)<0的区域中的时候,此时直接极小化f(x)即可得到;
- 当可行解x在g(x)=0的区域中的时候,此时直接等价于等式约束问题的求解。
- 当可行解在约束内部区域的时候,令β=0即可消去约束。
- 对于参数β的取值而言,在等值约束中,约束函数和目标函数的梯度只要满足平行即可,而在不等式约束中,若β≠0,则说明可行解在约束区域的边界上,这个时候可行解应该尽可能的靠近无约束情况下的解,所以在约束边界上,目标函数的负梯度方向应该远离约束区域朝无约束区域时的解,此时约束函数的梯度方向与目标函数的负梯度方向应相同;从而可以得出β>0。
1.3.1 KKT条件总结
- 拉格朗日取得可行解的充要条件;
- 将不等式约束转换后的一个约束,称为松弛互补条件;
- 初始的约束条件;
- 初始的约束条件;
- 不等式约束需要满足的条件。
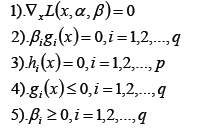
1.4 最优化问题的求解
最优化问题一般是指对于某一个函数而言,求解在其指定作用域上的全局最小值问题,一般分为以下三种情况(备注:以下几种方式求出来的解都有可能是局部极小值,只有当函数是凸函数的时候,才可以得到全局最小值):
无约束问题:求解方式一般求解方式梯度下降法、牛顿法、坐标轴下降法等。
等式约束条件:求解方式一般为拉格朗日乘子法。
不等式约束条件:求解方式一般为KKT条件。
1.5 距离知识回顾
- 点到直线/平面的距离公式:
- 假定点p(x0,y0),平面方程为f(x,y)=Ax+By+C,那么点p到平面f(x)的距离为:

从三维空间扩展到多维空间中,如果存在一个超平面f(X)=θX+b; 那么某一个点X0到这个超平面的距离为:
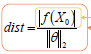
上式子中分母为函数距离,分子为几何距离。
- 假定点p(x0,y0),平面方程为f(x,y)=Ax+By+C,那么点p到平面f(x)的距离为:
1.6 感知器模型
感知器算法是最古老的分类算法之一,原理比较简单,不过模型的分类泛化能力比较弱,不过感知器模型是SVM、神经网络、深度学习等算法的基础。感知器的思想很简单:一个班有很多学生,分为男生和女生,感知器模型就是试图找到一条直线,能够把所有的男学员和女学员分隔开,如果是高维空间中,感知器模型寻找的就是一个超平面,能够把所有的二元类别分割开。感知器模型的前提是:数据是线性可分的。
- 对于m个样本,每个样本n维特征以及一个二元类别输出y,如下:
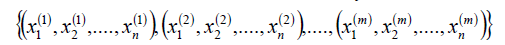
- 目标是找到一个超平面,即:
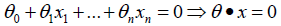
- 让一个类别的样本满足:θ·x > 0;另外一个类别的满足:θ·x > 0。
- 感知器模型为:
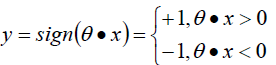
- 正确分类:yθx>0,错误分类:yθx<0;所以我们可以定义我们的损害函数为:期望使分类错误的所有样本(m条样本)到超平面的距离之和最小。
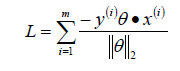
因为此时分子和分母中都包含了θ值,当分子扩大N倍的时候,分母也会随之扩大,也就是说分子和分母之间存在倍数关系,所以可以固定分子或者分母为1,然后求另一个即分子或者分母的倒数的最小化作为损失函数,简化后的损失函数为(分母为1):
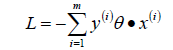
- 直接使用梯度下降法就可以对损失函数求解,不过由于这里的m是分类错误的样本点集合,不是固定的,所以我们不能使用批量梯度下降法(BGD)求解,只能使用随机梯度下降(SGD)或者小批量梯度下降(MBGD);一般在感知器模型中使用SGD来求解。
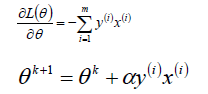
2 SVM
支持向量机(Support Vecor Machine, SVM)本身是一个二元分类算法,是对感知器算法模型的一种扩展,现在的SVM算法支持线性分类和非线性分类的分类应用,并且也能够直接将SVM应用于回归应用中,同时通过OvR或者OvO的方式我们也可以将SVM应用在多元分类领域中。在不考虑集成学习算法,不考虑特定的数据集的时候,在分类算法中SVM可以说是特别优秀的。
2.1 线性可分SVM
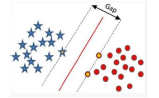
在感知器模型中,算法是在数据中找出一个划分超平面,让尽可能多的数据分布在这个平面的两侧,从而达到分类的效果,但是在实际数据中这个符合我们要求的超平面是可能存在多个的。

在感知器模型中,可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点都离超平面尽可能的远,但是实际上离超平面足够远的点基本上都是被正确分类的,所以这个是没有意义的;反而比较关心那些离超平面很近的点,这些点比较容易分错。所以说我们只要让离超平面比较近的点尽可能的远离这个超平面。
- 线性可分(Linearly Separable):在数据集中,如果可以找出一个超平面,将两组数据分开,那么这个数据集叫做线性可分数据。
- 线性不可分(Linear Inseparable):在数据集中,没法找出一个超平面,能够将两组数据分开,那么这个数据集就叫做线性不可分数据。
- 分割超平面(Separating Hyperplane):将数据集分割开来的直线/平面叫做分割超平面。
- 间隔(Margin):数据点到分割超平面的距离称为间隔。
- 支持向量(Support Vector):离分割超平面最近的那些点叫做支持向量。
- 支持向量到超平面的距离为:

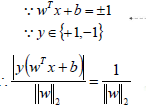
备注:在SVM中支持向量到超平面的函数距离一般设置为1。 - SVM模型是让所有的分类点在各自类别的支持向量的两边,同时要求支持向量尽可能的原理这个超平面,用数学公式表示如下:
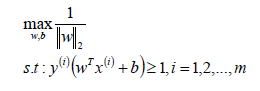
将上式子优化为SVM的损失函数为:
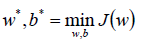
将此时的目标函数和约束条件使用KKT条件转换为拉格朗日函数,从而转换为无约束的优化函数。
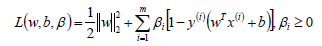
引入拉格朗日乘子后,优化目标变成:
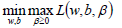
根据拉格朗日对偶化特性,将该优化目标转换为等价的对偶问题来求解,从而优化目标变成:
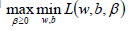
所以对于该优化函数而言,可以先求优化函数对于w和b的极小值,然后再求解对于拉格朗日乘子β的极大值。- 首先求让函数L极小化的时候w和b的取值,这个极值可以直接通过对函数L分别求w和b的偏导数得到:
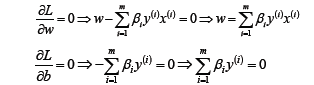
将求解出来的w和b带入优化函数L中,定义优化之后的函数如下:
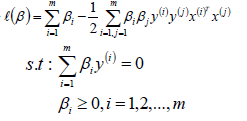
- 通过对w、b极小化后,我们最终得到的优化函数只和β有关,所以此时我们可以直接极大化我们的优化函数,得到β的值,从而可以最终得到w和b的值。
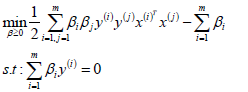
假设存在最优解β*; 根据w、b和β的关系,可以分别计算出对应的w值和b值(一般使用所有支持向量的计算均值来作为实际的b值);
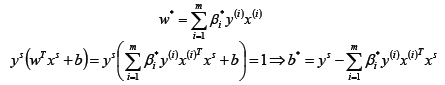
这里的(xs,ys)即支持向量,根据KKT条件中的对偶互补条件(松弛条件约束),支持向量必须满足一下公式:
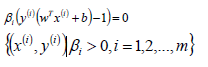
2.1.1 算法流程
- 输入线性可分的m个样本数据{(x1,y1),(x2,y2),..,(xm,ym)},其中x为n维的特征向量,y为二元输出,取值为+1或者-1;SVM模型输出为参数w、b以及分类决策函数。
- 构造约束优化问题;
- 使用SMO算法求出上式优化中对应的最优解β*;
- 找出所有的支持向量集合S;
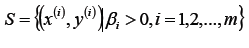
- 更新参数w、b的值;
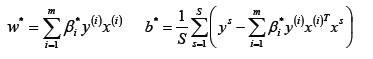
- 构建最终的分类器。
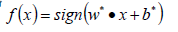
- 构造约束优化问题;
2.1.1 算法总结
- 要求数据必须是线性可分的;
- 纯线性可分的SVM模型对于异常数据的预测可能会不太准;
- 对于线性可分的数据,SVM分类器的效果非常不错。
2.2 SVM的软间隔模型
线性可分SVM中要求数据必须是线性可分的,才可以找到分类的超平面,但是有的时候线性数据集中存在少量的异常点,由于这些异常点导致了数据集不能够线性划分;直白来讲就是:正常数据本身是线性可分的,但是由于存在异常点数据,导致数据集不能够线性可分;
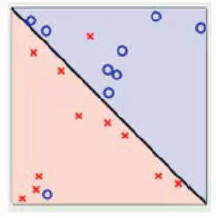
如果线性数据中存在异常点导致没法直接使用SVM线性分割模型的时候,可以通过引入软间隔的概念来解决这个问题;
硬间隔:可以认为线性划分SVM中的距离度量就是硬间隔,在线性划分SVM中,要求函数距离一定是大于1的,最大化硬间隔条件为:
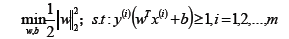
软间隔:SVM对于训练集中的每个样本都引入一个松弛因子(ξ),使得函数距离加上松弛因子后的值是大于等于1;这表示相对于硬间隔,对样本到超平面距离的要求放松了。
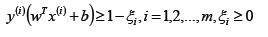
松弛因子(ξ)越大,表示样本点离超平面越近,如果松弛因子大于1,那么表示允许该样本点分错,所以说加入松弛因子是有成本的,过大的松弛因子可能会导致模型分类错误,所以最终的目标函数就转换成为:
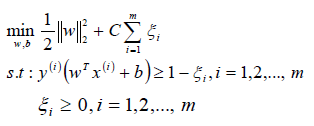
备注:函数中的C>0是惩罚参数,是一个超参数,类似L1/L2 norm的参数;C越大表示对误分类的惩罚越大,C越小表示对误分类的惩罚越小;C值的给定需要调参。
- 同线性可分SVM,构造软间隔最大化的约束问题对应的拉格朗日函数如下:
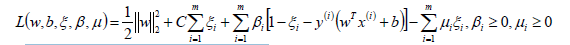
- 从而将我们的优化目标函数转换为:
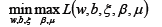
- 优化目标同样满足KKT条件,所以使用拉格朗日对偶将优化问题转换为等价的对偶问题:
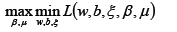
- 先求优化函数对于w、b、ξ的极小值,这个可以通过分别对优化函数L求w、b、ξ的偏导数得,从而可以得到w、b、ξ关于β和μ之间的关系。
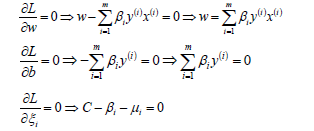
- 将w、b、ξ的值带入L函数中,就可以消去优化函数中的w、b、ξ,定义优化之后的函数如下:
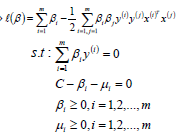
- 最终优化后的目标函数/损失函数和线性可分SVM模型基本一样,除了约束条件不同而已, 也就是说也可以使用SMO算法来求解。

2.2.1 算法流程
输入线性可分的m个样本数据{(x1,y1),(x2,y2),...,(xm,ym)},其中x为n维的特征向量,y为二元输出,取值为+1或者-1;SVM模型输出为参数w、b以及分类决策函数。
- 选择一个惩罚系数C>0,构造约束优化问题;
- 使用SMO算法求出上式优化中对应的最优解β*;
- 找出所有的支持向量集合S;
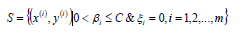
- 更新参数w、b的值;
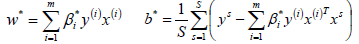
- 构建最终的分类器。
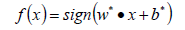
2.2.1 算法总结
- 可以解决线性数据中携带异常点的分类模型构建的问题;
- 通过引入惩罚项系数(松弛因子),可以增加模型的泛化能力,即鲁棒性;
- 如果给定的惩罚项系数越小,表示在模型构建的时候,就允许存在越多的分类错误的样本, 也就表示此时模型的准确率会比较低;如果惩罚项系数越大,表示在模型构建的时候,就越不允许存在分类错误的样本,也就表示此时模型的准确率会比较高。