一、资源调度
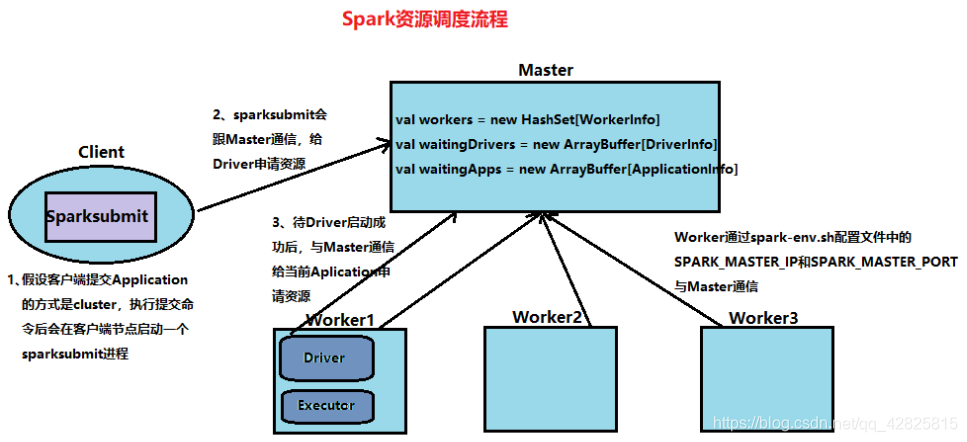
1、待集群Spark集群启动成功后,Woker与Master通信,此时Worker的各种信息(IP、port等)会存在Master中的wokers集合中,其数据类型是HashSet。此时Master会为各个Worker分配资源。
2、当sparksubmit向Master为Driver申请资源时,申请信息会封装在Master
中的waitingDrivers集合中,此时有个Schedule()方法会监控waitingDrivers集合是否为空,若不为空,说明有客户端向Master申请资源,然后查看当前集群的资源情况,从而找到符合要求的节点启动Driver,待Driver启动成功,就把这个申请信息从waitingDrivers集合中删除。
3、Driver启动成功后,Driver会向Master为Application申请资源,申请信息会封装在Master中的waitingApps集合中,同样Schedule()方法会监控waitingApps集合是否为空,若不为空,说明有Driver为当前Application申请资源,然后查看当前集群的资源情况,从而找到符合要求的节点去启动Executor进程,待Executor启动成功后,就把这个申请信息从waitingApps集合中删除。
总结:
当为Driver或者当前Application申请资源时,会直接调用Schedule()方法,根据不同的申请去反调相应的方法,即一个Schedule()方法中有两套处理逻辑。
资源调度结论:
- 默认情况下,每一个Worker会为当前的Application启动一个Executor进程,并且这个Executor会使用1G内存和当前Worker所能管理的所有core。
- 如果想要在一个Worker上启动多个Executor,可以在提交Application的时候,指定Executor使用的core数,命令为:
spark -submit --executor-cores。 - 默认情况下Executor的启动方式为轮训启动。
Executor在worker上启动的条件是什么?
- Worker分配给Executor的cores大于Executor所需要的最小cores。
- Worker空闲 cores大于Executor所需最小cores。
- Worker的空闲内存大于Executor所需要的内存。
二、任务调度
三、资源调度与任务调度整合
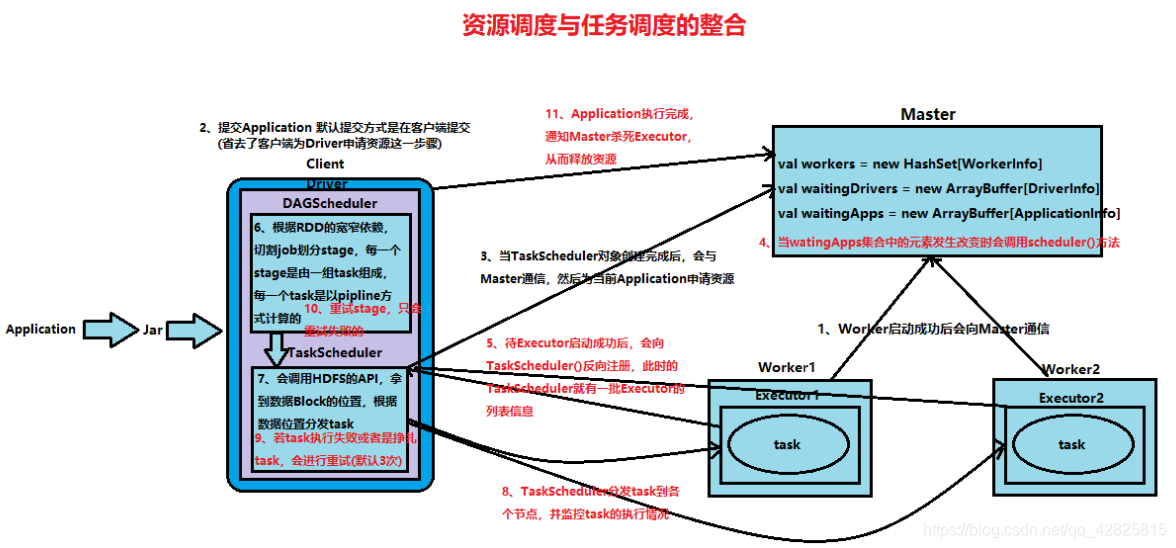
整个过程中的部分问题:
- 客户端没有向Master为Driver申请资源,Driver是如何启动起来的?
通过Application程序中的SparkContext上下文启动起来的。 - 为什么waitingWorkers的数据类型是HashSet?
因为Set的特点是唯一性,当worker与Master失去通信的时候,Master会设置一个时间间隔,若超过时间间隔worker还没有与Master建立通信,那么Master认为这个worker挂掉,从而释放这部分资源。若建立通信,Master则把原来那部分资源分配个worker,从而保证每个worker分配到一份资源。 - 启动Executor的方式为轮训启动,其优点是什么?
这种启动方式可以使计算能够更好地找到数据,有助于数据的本地化。
四、粗细粒度资源调度
1、什么是粗粒度资源调度?
在任务执行之前,会先将资源申请完毕,当所有的task执行完毕,才会释放这部分资源。Spark就是典型的代表。
优点:
每一个task执行之前,不需要自己去申请资源,直接使用申请好的资源就行,task启动速度变快,执行时间缩短,整体效率提升。
缺点:
需要将所有的task执行完才会释放资源,假设有10000个task,9999个task执行完毕了,但是资源不能释放,需等待最后一个task执行完成,才会释放资源,这样导致集群的资源无法充分的利用。
2、什么是细粒度资源调度?
Application提交的时候,每一个task自己去申请资源,只有申请到资源才可以执行,执行完成后立马释放。MapReduce就是细粒度资源调度。
优点:
每一个task执行完释放,有利于充分利用集群资源。
缺点:
由于每个task需要自己去申请资源,申请需要时间,导致task启动时间边长,进而stage、job、Application的时间就边长,整体效率降低。