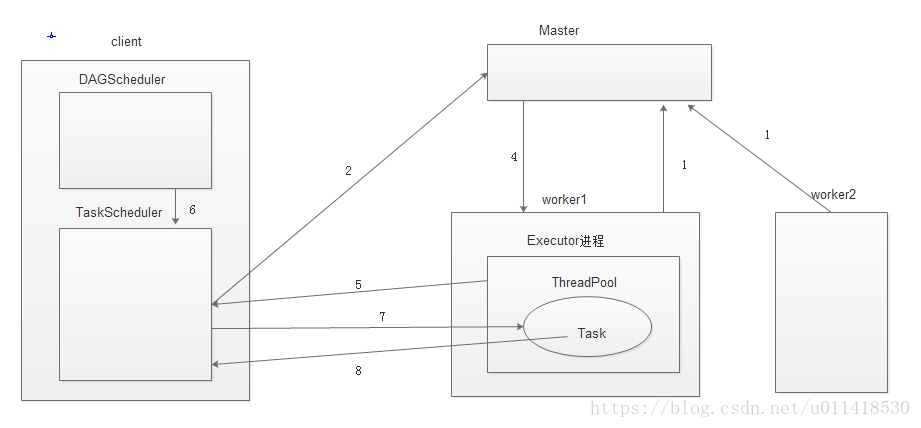
1,当每个worker启动起来之后,会向master注册信息(内容:当前worker进程所管理的资源情况);这样Master就掌握了整个集群的资源情况
2,当new SparkConf 和SparkContext的时候Driver当中就启动了DAGScheduler和TaskScheduler;这时候TaskScheduler会向Master发送请求(内容:当前Application执行所需要的资源,对于一个Application来说资源就是计算进程(Executor))
3,Master接受了TaskScheduler发送的请求,寻找资源满足的Worker,向这批Worker发送信息(内容:给我启动一个Executor进程)
4,Worker接受信息之后启动Executor进程,会产生一个ThreadPool线程池
5,Executor启动完成后会反向注册给Driver里的TaskScheduler;这样TaskScheduler就掌握了这批Executor地址
6,这时候DAGScheduler会将当前的Job切割,划分成一个个的stage,然后以taskSet的形式给TaskScheduler
7,TaskScheduler接受到了taskSet,遍历taskSet将每一个task根据数据本地化的算法发送到Executor中执行
8,Task执行完成之后将计算情况汇报给TaskScheduler
Driver是如何启动的:
spark-submit在客户端提交后,实际上会根据我们class在本地执行我们的jar,这时候启动起来的JVM进程就是Driver进程
资源调度分两种:
粗粒度资源调度(spark) spark每一个task是一个进程
细粒度的资源调度(MapReduce) jvm会单独启动一个线程来运行这个进程,执行完之后直接kill掉这个线程
粗粒度资源调度:
在每一个Application执行之前,会将Application所需要的所有资源全部申请完毕,申请成功之后才会进行下一步的任务调度,直到所有的task执行完毕,才会释放掉这部分资源。
优点:
每一个task在执行前不需要自己去申请资源,这样task执行就变快了,相对应的stage,job,application就都变快了
缺点:
资源浪费,因为是在最后一个task执行完毕才释放资源,集群资源不会被充分利用
细粒度的资源调度:
在每一个application执行之前不需要先去申请资源,在每一个task执行之前自己去申请,申请到资源,task才能执行,task执行完毕立即释放资源
优点:集群资源可以充分利用
缺点:每一个task启动变慢,application就变慢了
RDD的第三大特性:RDD之间有一系列的依赖关系
宽依赖:父RDD与子RDD,partition之间是一对多的关系
窄依赖:父RDD与子RDD,partition之间是一对一的关系
父RDD与子RDD,partition之间是多对一的关系
切割job划分stage