Ranking Relevance in Yahoo Search
Yahoo! Inc
KDD2016 Industry track best paper
ABSTRACT
queries 和 URLs 之间的 semantic gap 是搜索的主要屏障。点击行为可以帮助我们提高相关性,但是对于大部分长尾 query,点击行为过于稀疏,而且噪声过大。为了增加相关性,时间地点的敏感性对于结果也是很重要的。
本文介绍搜索中的三点关键技术
- ranking functions,
- semantic matching features
- query rewriting。
Keywords: learning to rank; query rewriting; semantic matching; deep learning
INTRODUCTION
搜索排名早期的工作主要集中在 queries 和 documents 的 text matching,例如 BM25,probabilistic retrieval model,vector space model。
后来结合用户行为搜索结果的相关性进一步提高,例如 click modeling。
现在 state of the art 的搜索方法所展现的瓶颈使得我们需要考虑 text matching 和 click modeling 之外的方法:
- semantic gap 是主要的困难(query: how much tesla -> doc: tesla price)
- 大量的长尾 query 使得无法利用用户行为信息
- 用户会把搜索引擎当作是 Q&A systems,产生越来越多的自然语言的搜索
- 需要考虑时空维度的信息,例如:最安全的汽车(当然是如今最安全的汽车),沃尔玛(附近的)
本文主要的贡献是:
- 设计了一个全新的 learning to rank 算法和 contextual reranking 算法
- 发展了 semantic matching features,包括 click similarity, deep semantic matching, and translated text matching
- 提出了 query rewriting 和搜索相关算法
- 提出了时空敏感的排序方案
BACKGROUND
Overview of Architecture
Yahoo search engine 可以很快的完成搜索这是因为:
- 平行的对一个 query 进行多个 servers
- 不断从 a cheaper ranking function 筛选出候选集然后再用更好一点的 ranking function 筛选
数据集被分为等大小的分片(根据 URL 的 MD5 分配),索引服务器提供接下来的服务。 每个查询由先由分片处理,每个分片返回其最佳候选文档。 然后将它们合并并重新排列以生成最终结果集。
在一个分片中,第一步是查找与查询匹配的所有文档,这称为召回(通常对每个查询词的文档集取交集以获取包含所有词的文档集)。 然后对这些文档进行第一轮排序,对每个文档用轻量级函数进行评分。 然后对分片强制执行简单的多样性约束,例如限制来自单个主机或域的文档数量。 然后,从排名靠前的候选者中提取查询相关特征,然后使用更 expensive 的第二轮函数对其进行排序,也称为 Core Ranking Function。
Ranking Features
- Web graph:描述文档的质量和流行程度,例如PageRank
- Document statistics:计算文档的一些基本统计信息,例如各个字段中的单词数
- Document classifier:文档的分类信息,例如页面的语种,主题,质量等
- Query Features: term 数,query 和 term 的频率和点击率
- Text match:文本匹配特征,例如:BM25
- Topical matching:话题级别的相似度
- Click:用户点击结果的 feedback
- Time:跟时间相关的特征
Evaluation of Search Relevance
评价搜索的相关性分为 human labeling 和 user behavioral metrics。一般用 user behavioral 来评价搜索相关性会更复杂一点,因为可能受到字体,位置等的影响。本文采用 human labeling 的方式进行评价,采用的指标是 DCG : , 表示位置 上的文档的相关性评分。
根据 query 的出现频率,我们可以把 query 分为头部,腰部和尾部。本文主要关注腰部和尾部的 query。
MACHINE LEARNED RANKING
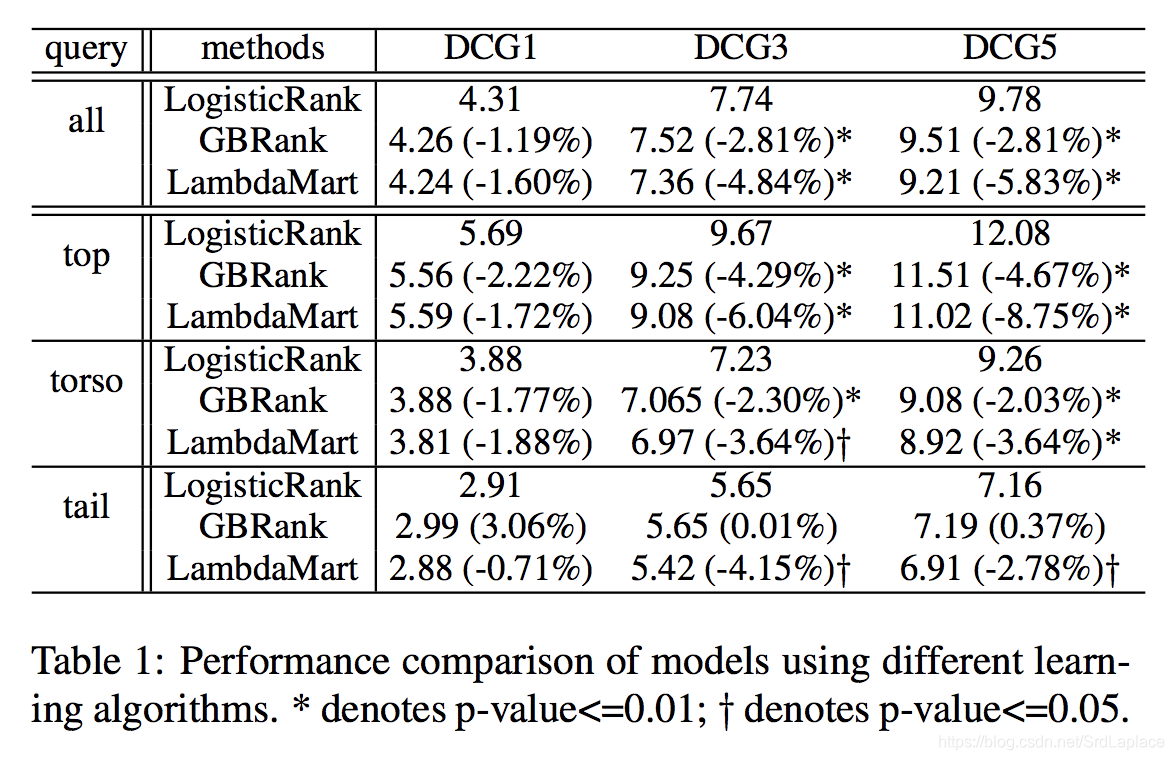
搜索可以被当作二分类问题。 在实验中,我们观察到具有 logistic loss 的 GBDT 通常能够减少顶部位置的不好 URL。但是它不能完美的对 URLs 进行排序。
Core Ranking
We first flat the labels “Perfect”, “Excellent” and “Good” to “Positive” (+1) and “Fair”, “Bad” to “Negative” (-1). The log likelihood (loss) is
Then the pseudo-response of stage
is
回归的结果不但可以判断 doc 是否相关,而且可以给出合理的排序。但是一个简单的二分类器不足以很好的进行排序,需要把 “Perfect”, “Excellent” and “Good” back to the model。因此我们引入 gradient scale for GBDT。The pseudo-response of stage m will become:
根据经验,我们设置
。
命名我们的算法为 LogisticRank,总体而言,要比其他算法效果好。
Contextual Reranking
Core ranking 只考虑了 query-URL pair features, 忽略了上下文信息。实际的原因即使使用简单的特征对于大规模的 doc 速度也会很慢。
因此我们只重新排序第一轮结果的前几十个结果,例如前 30 个。对于这些结果,我们提取他们的上下文特征:
- Rank: 通过特征值降序对 URL 进行排序
- Mean: 计算前30个 URL 特征的平均值
- Variance: 计算前30个 URL 特征的方差
- Normalized feature: 用均值和方差对特征进行归一化
- Topic model feature: 聚合这30个 URL 的主题分布以创建查询主题模型向量,并计算与每个单独结果的相似性
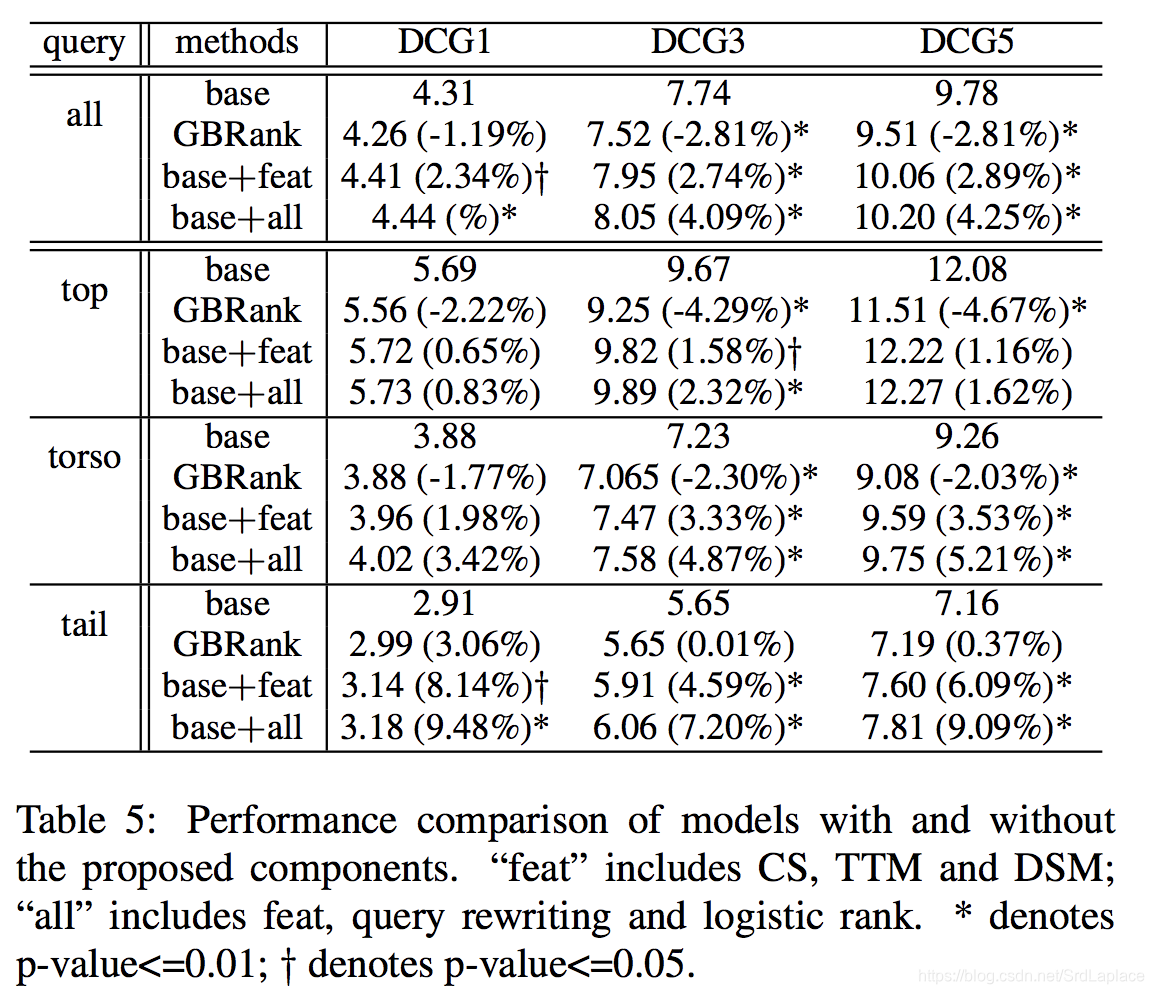
除了上下文特征之外,Reranking 的另一个优点是该阶段的训练数据不太容易出现样本选择偏差,因为已经进行了第一轮的筛选。在实践中,我们发现使用 Core Ranking 结果的排名作为特征比直接使Core Ranking 的分数结果更加健壮。尽管得分比排名信息量更大,但分数会随着排序刷新而漂移,从而降低第三阶段的表现。由于 Reranking 在前30个结果上运行,其主要目的是进一步区分相关结果(“Perfect”, “Excellent”, “Good”),而不是识别和删除不良结果。影响如表2所示。我们看到通过重新排名可以显着且持续地改善整体性能。
Implementation and deployment
在每个节点上平行计算,返回 topk 个结果然后排序,在进行 Reranking。
SEMANTIC MATCHING FEATURES
对于长尾的 query,由于过于稀疏和充满噪声,user behavior features 将会失效;docs 中也会缺少相应的 anchor text。Text matching features suffer from the vocabulary gap between queries and documents。为了克服这些问题,我们引入三个全新的特征:click similarity, translated text matching and deep semantic matching。这些特征是以不同方式从点击日志计算出来的,并相互补充。
Click Similarity
传统的 Traditional content-based models(例如 VSM)因为 query 和 doc 之间的词汇使用不同而产生 gap。从点击日志我们可以得到 query 和 docs 的二分图,显然 query 之间越相似,它们点击的 doc 也越相似。我们通过迭代得到每个 query 和 doc 的向量
为了优化计算我们只考虑非零的连边,但连边依然数据量很大,我们发现只保留 topK 的 term 来做迭代所得结果精度损失很小。考虑点击相似度之后DCGN有所上升。
在实际中,每个月用新的点击日志进行对 query 和 doc 的向量进行更新。在使用中,query 和 document 的 Click Similarity 作为一个特征应用在排序模型中。
Translated Text Matching
尽管 click similarity feature 十分高效,但是不能计算从未在 log 中出现的 query 和 doc。直觉上可以用 Translated Text Matching ,也就是说讲 query 翻译成 doc 或者 doc 翻译成 query 来弥补词汇之间的 gap。我们根据点击日志,得到 query 和 doc 之间的 bitext,将 query 转换为 k 个 document title space 的备用 query。最后计算原始 query 和 doc 之间的final similarity score
,
是第
个翻译的 query 和 doc 的相似度,
表示整合着 k 个值的方法(max, mean, median, etc)。
实际中我们取
,
为去 max,计算query to doc 和 doc to query 的翻译结果,计算余弦相似度。
下一章 QUERY REWRITING 会详细描述。
Deep Semantic Matching
头部的 query 比较容易运用机器学习进行 rank,而腰部和尾部的 query 由于点击的次数有限,机器学习起来有些困难。前面提到的 CS 和 TTM 在一定程度上缓解了困难:CS 平滑了点击信息并消除了点击的噪音,TTM 是 query 重写的 soft version 本并有 n-gram 的等价新型。 但是,这两种方法都是单词级别的特征。 为了进一步提升排名结果,我们需要深入了解语义信息和用户背后的意图。 深度学习技术可以帮助从头部的 query 中提取语义和上下文信息,然后泛化到腰部和尾部的 query。
腰部和尾部 query 的罕见性主要是由拼写错误、同义词、缩写、长或描述性 query 引起的。 一般来说,尾部的 query (平均有四到五个单词)往往比头部的 query 长得多。 较长的查询很难与网页的标题或内容相匹配。 但是,与具有一个或两个单词的较短查询相比,它可能包含更多语义信息。
采用 DSSM 作为排序模型的前馈神经网络。用1年的数据,筛选出页面展现超过100的数据,进行训练。
QUERY REWRITING
Methodology
The Learning Phase
使用人标注的 rewritten queries 来训练几乎不可能,因为需要的数据量很大而且人难以标注。
一般文章标题相对较短、富含信息,而且与 query 更相似。我们利用点击信息训练翻译模型,一般题目比 query 长很多,我们词对齐时调整 null-word alignment probability 到相对较高的0.9来过滤噪声。
The Decoding Phase
给定 query,用若干种方法分词,每个分词都有若干个翻译,导致有上百个 query 的改写。现在需要挑出最可信的几个,Typically each candidate
is scored via a linear combination of
feature functions and the decoding is formally defined as:
是特征函数, 是它的系数。我们设计出了三种特征:
- Query feature functions: -number of words in q, -number of stop words in q, -language model score of the query , h4- query frequency of q, h5-average length of words in q;
- Rewrite query feature functions: -number of words in , -number of stop words in , -language model score of the query rewrite , -query frequencies of the query rewrite , - average length of words in
- Pair feature functions: -Jaccard similarity of URLs shared by and in the query-URL graph, -difference between the frequencies of the original query and the rewrite candidate , -word-level cosine similarity between and , -difference between the number of words between and , -number of common words in and , -difference of language model scores between and , -difference between the number of stop words between and , -difference between the average length of words in and .
通过定义 loss function 学习和调整 。我们的经验表明, , , 是三个最重要的特征。
Ranking Strategy
QUERY REWRITING 很难通过人工标记来训练和评估。如何利用 QUERY REWRITING 来进行检索,直觉上可以直接替换,我们的经验表明,这样很有风险,因为很差的改写将会严重影响检索结果的相关性。我们的方法是对改写的 query 和原始 query 进行检索,结果取交集,评分取较大的评分。
在生产环境中,为了保证速度,我们在 cache 中保留最常见的 100 million queries 的 rewrites,来保证速度。
COMPREHENSIVE EXPERIMENTS
RECENCY-SENSITIVE RANKING
日常搜索中,希望结果 not only relevant, but also fresh。
我们利用 recency dataset 训练一个二分类器,区分 doc 是否与时效有关,如果有关的话在计算 doc 的时效分。
LOCATION-SENSITIVE RANKING
和 RECENCY-SENSITIVE 类似,分数增加一项地点相关:
表示距离,
为归一化距离。当
,则
。
CONCLUSION
本文介绍了雅虎搜索的相关性综合解决方案。 方案有效、实用,并且已经在雅虎的商业搜索引擎中大规模部署和测试。这些方案不仅可以用于网络搜索,还可以用于垂直搜索引擎。