CVPR 2018 腾讯团队
目前,大多数图像描述工作都是基于单个图像的在线描述,忽略了群组图像之间的关联度和多样性。在许多真实世界的应用程序中,如描述相册或事件,图像不适合单独描述。《GroupCap: Group-based Image Captioning with Structured Relevance and Diversity Constraints》这篇论文提出提了基于群组的图像描述架构:GroupCap,联合建模群组图像之间的结构化关联性和多样性,以实现最佳的协作描述。作者认为,群组图像中基于群组的描述的基本问题在于:以离线的方式从视觉角度对其相关性(Correlation)建模,相关性就包括关联性(Relevance)和多样性(Diversity)。一方面,视觉结构相关性可以准确地建模群组内图像在离线训练期间的细粒度多样性;另一方面,学习这种离线的视觉结构可以更好的捕获并准确的解释群组间图像的关联性。
模型的基本架构如图1所示:
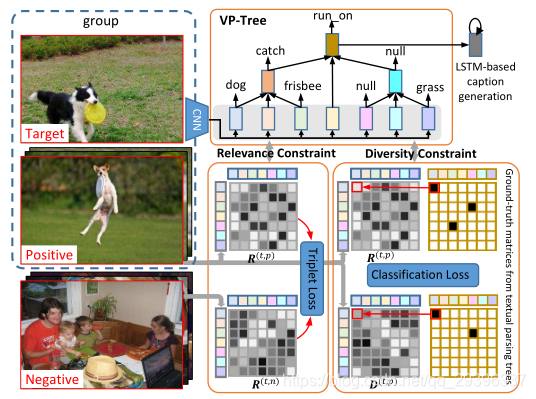
首先用一个预训练的CNN模型来提取每个给定图像的视觉特征,借着训练一个视觉解析树模型(VP-Tree)来来提取这些图片的视觉实体及其关系,然后提出一种方案来量化基于树的相关性,建模图像-图像之间的相关度。最后将整个模型联合训练。
1、构建VP-Tree
以图1为例,给定一个图片-描述对,首先从预训练的最后全连接层提取深度视觉特征G。然后将G映射到相应节点的实体/关系的特征表示,这步称为“语义映射”。定义VP-Tree为![]() ,其中h表示节点特征,l表示树的层数,
,其中h表示节点特征,l表示树的层数,![]() 表示节点特征的维度,
表示节点特征的维度,![]() 表示第l层的节点指针。在语义映射阶段,G映射为
表示第l层的节点指针。在语义映射阶段,G映射为![]() 如下:
如下:
![]()
其中,F是线性映射函数,转换视觉特征为语义条目(实体和关系),w表示第j1个节点在第一层的参数。
根据树的结构,结合实体或关系的特征,将他们映射到关系更高层次的特征表示,这步称为的“组合”。接下来合并底层孩子节点的特征到到父节点:
![]()
![]()
![]()
其中,F和w分别为线性映射函数和他的参数。
与此同时,每个节点的特征映射到一个类别(实体或关系)空间,这一步叫做“分类”。通过Softmax分类器将每个节点分类为实体/关系类别:
![]()
![]()
其中,yn为根据实体字典或关系字典预测出的概率向量,F和w分别为线性映射函数和他的参数。
注意,描述句子通过标准文本解析器解析为一个文本解析树Tt,在训练期间用于监督相应的实体/关系分类。
定义![]() ,最小化类别分类损失来优化整个树模型。
,最小化类别分类损失来优化整个树模型。
2、结构化关联性和多样性约束
定义三元组图像为(目标,正例,负例)。给定一个图像三元组(i,j,k),基于叶子节点的特征矩阵估算成对图像之间的关联度矩阵。叶结点为![]() (K是叶子节点个数,这里等于7)。以目标和正例这一对图像组为例:
(K是叶子节点个数,这里等于7)。以目标和正例这一对图像组为例:
![]()
![]()
其中,R是K*K的关联度矩阵,D是K*K的多样性矩阵,U为参数,ϕ![]() 表示Sigmod函数。然后比较组内图像与组间图像的相似度如下:
表示Sigmod函数。然后比较组内图像与组间图像的相似度如下:
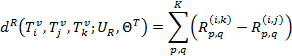
其中![]() 表示i图p节点与j图q节点之间的关联度得分。
表示i图p节点与j图q节点之间的关联度得分。
假设有N个图像三元组,应用三元组损失来最大化组内相似度,最小化组间相似度:
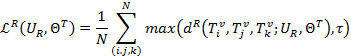
其中,τ![]() 表示为预定义的三元组损失矩阵。
表示为预定义的三元组损失矩阵。
引入一个基于对齐方式的logistic回归来计算分类损失,以在同组内的图片i,j为例:
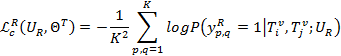
其中,y表示关联度矩阵中中p、q节点之间的关联度估算,如果相关等于1,否则等于0。多样性计算类似:
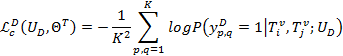
3、联合学习
给定一个图像三元组的视觉特征集合![]() ,GroupCap的联合损失定义为:
,GroupCap的联合损失定义为:
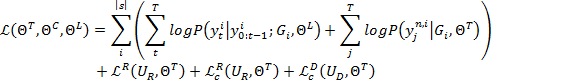
其中,T为输出序列长度,K为树节点个数,yti![]() 为t时刻输出单词,yjn,i
为t时刻输出单词,yjn,i![]() 为i样例的j节点的实体/关系类别。
为i样例的j节点的实体/关系类别。
区分一下在线学习和离线学习,在线学习就是每跑完一个batch就更新参数,而离线学习是在整个数据集的基础上更新参数,也就是说,在线学习是优化了这一个batch的数据,有一定的随机性,而离线学习每次的优化是在整个数据集上的。这篇论文的方法是基于离线学习的。