版权声明:原创文章未经博主允许不得转载O(-_-)O!!! https://blog.csdn.net/u013894072/article/details/84541648
KMeans聚类
在聚类算法中,最出名的应该就是k均值聚类(KMeans)了,几乎所有的数据挖掘/机器学习书籍都会介绍它,有些初学者还会将其与KNN等混淆。k均值是一种聚类算法,属于无监督学习的一种,而KNN是有监督学习/分类学习的一种。
聚类:顾名思义,就是讲某些相似的事物聚在一起,形成一个类。这里就涉及到几个概念
1.如何表示一个事物?通常我们会准备好一个数据集,里面是我们的数据,每一行代表的都是一个数据,每一列是一个数据的一种特征。比如经典的分类数据集 iris(鸢尾花数据),每一行代表的是每一朵花,每一朵花都有花萼长度,花萼宽度,花瓣长度,花瓣宽度 4个特征,即有4列特征。
2.如何度量事物间的距离?我们拿到每一个数据的特征值之后,需要根据实际情况来进行两种数据之间的计算,常用的方法是欧氏距离、马氏距离、余弦距离等。
3.按照什么样的过程进行聚类?这里就涉及到具体的算法了,目前聚类大致有几个比较流行的方法:基于划分、基于层次、基于密度、基于网络。这里的K均值就属于基于划分的方法,后续会继续写其余几种方法的代表算法。
4.如何能判断聚类过程结束呢?当每一种类别中的数据趋于稳定,即为完成聚类
KMeans过程

上图是截取别人blog中的图片(参考文献1),这里讲的其实很清楚了。
上代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
Author LiHao
Time 2018/11/26 9:21
"""
import os
import sys
import numpy as np
import scipy as sp
from sklearn.datasets import load_iris
# 欧式距离函数
from ml_learn.algorithm.distance import eculide
import matplotlib.pyplot as plt
def load_data():
"""
导入iris标准数据集
:return:
"""
iris = load_iris()
data = iris.data
target = iris.target
target_names = iris.target_names
return data,target,target_names
class Group(object):
"""
定义类簇
"""
def __init__(self):
self._name = ""
self._no = None
self._members = []
self._center = None
@property
def no(self):
return self._no
@property
def name(self):
return self._name
@name.setter
def name(self,no):
self._no = no
self._name = "G"+str(self._no)
@property
def members(self):
return self._members
@members.setter
def members(self,member):
if member is None:
raise TypeError("member is None,please set value")
self._members.append(member)
def clear_members(self):
self._members = []
@property
def center(self):
return self._center
@center.setter
def center(self,c):
self._center = c
class KMeans(object):
def __init__(self,k = 2):
if (k <= 1) or (k is None):
raise ValueError("k's num must not none and must > 1.")
self._k = k
# 类簇
self._groups = self._make_groups(k)
self._pre_mean_value = 0
self._current_mean_value = 1
def _make_groups(self,k):
"""
生成类簇
:param k:
:return:
"""
groups = []
for i in range(k):
g = Group()
g.name = i+1
groups.append(g)
return groups
def _random_x_index(self,xlen):
indexes = np.random.randint(0,xlen,self._k).tolist()
return indexes
def _compute_mean_value(self):
sum = 0
for i in range(len(self._groups)):
average = self._compute_members_mean(self._groups[i].members)
self._groups[i].center = average
sum += average
return sum/(len(self._groups))
def _compute_members_mean(self,members):
np_members = np.array(members)
average = np.average(np_members,axis=0)
return average
def _find_most_nearby_group(self,x):
np_groups = np.array([group.center for group in self._groups])
distances = eculide(x,np_groups)
most_similarity_index = np.argmin(distances).squeeze()
self._groups[most_similarity_index].members = x
return most_similarity_index
def _clear_groups_members(self):
for group in self._groups:
group.clear_members()
def fit(self,X):
rows,cols = X.shape
# 1.首先选取k个点为初始聚类中心点
init_indexes = self._random_x_index(rows)
for i,index in enumerate(init_indexes):
self._groups[i].center = X[index]
self._groups[i].members = X[index]
# 2.计算每个数据与聚类中心的距离,加入到最近那一个类
while(True):
for i in range(rows):
#发现距离最近的group 并将数据加入至类簇中
self._find_most_nearby_group(X[i])
# 3.重新计算每个类簇的平均值
# 计算各个类别的聚类中心并返回所有类簇的均值
self._current_mean_value = self._compute_mean_value()
epos = np.sum(self._current_mean_value-self._pre_mean_value,axis=0).squeeze()
if epos <= 0.00001:
break
# 清除历史成员 并将计算得到的均值误差保存
self._clear_groups_members()
self._pre_mean_value = self._current_mean_value
# 4.重复2-3的运算,直到每个类簇额均值不再发生变化
def plot_example(self):
figure = plt.figure()
ax = figure.add_subplot(111)
ax.set_title("KMeans Iris Example")
colors = ['b','r','y','k','g','c','m']
plt.xlabel("first dim")
plt.ylabel("third dim")
legends = []
for i in range(len(self._groups)):
group = self._groups[i]
members = group.members
x = [member[0] for member in members]
y = [member[2] for member in members]
ax.scatter(x,y,c=colors[i],marker='o')
legends.append(group.name)
plt.legend(legends,loc="best")
plt.show()
data,target,target_names = load_data()
kmeans = KMeans(k=3)
kmeans.fit(data)
kmeans.plot_example()
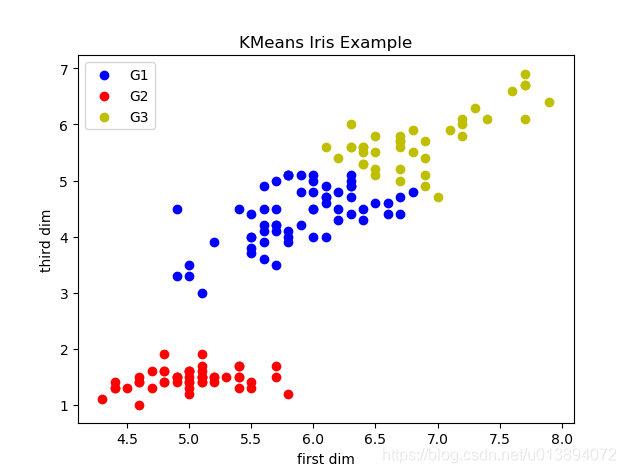
经过运行,可以得到类似下图的结果:选取的是iris数据集,展示的是第一维和第三维的二位平面图。iris真实数据是分为3类,每一类50个数据。
每次运行的结果可能不一样,因为我们选取的初始中心点是随机的,这样就会造成结果的不稳定性。因此,很多K均值的改进方法就会从初始点选取进行优化;还有的是优化了均值计算,变成了中位数计算(K_median算法)