import numpy as np
import matplotlib.pyplot as plt
import math
import random
import pandas as pd
data=pd.read_csv("svm.csv")
kdataList=data.values.tolist() #把DataFrame解析成列表
fig=plt.figure()
ax=fig.add_subplot(121)
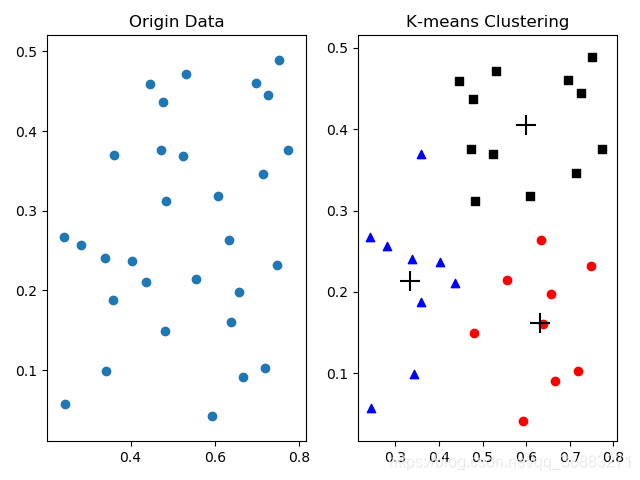
ax.scatter(data["factor1"],data["factor2"]) #原始数据散点图
plt.title("Origin Data")
listData0=[]
listData1=[]
listData2=[]
listU=[]
listULast=[]
dis=[]
k=3 #簇个数
data=data.values
center=np.zeros((k,np.shape(data)[1]))
for i in range(k):
for j in range(np.shape(data)[1]):
minI=min(data[:,j])
rangeI=float(max(data[:,j])-minI)
center[i][j]=random.random()*rangeI+minI
listU=center.tolist()
while True:
if listULast!=listU:
for i in range(30):
for j in range(3):
dis.append(math.sqrt(pow(kdataList[i][0]-listU[j][0],2)+pow(kdataList[i][1]-listU[j][1],2))) #计算样本点与均值向量的距离
minDis = dis[0]
disIndex=0
for m in range(1,3):
if dis[m]<minDis:
minDis=dis[m]
disIndex=m
if disIndex==0:
listData0.append(kdataList[i])
elif disIndex==1:
listData1.append(kdataList[i])
else:
listData2.append(kdataList[i])
dis=[]
listULast = listU
listU=[]
npData0=np.matrix(listData0)
npData1=np.matrix(listData1)
npData2=np.matrix(listData2)
listData0=[]
listData1=[]
listData2=[]
u0=np.mean(npData0,axis=0).tolist()[0]
if listULast[0]!=u0[0]:
listU.append(u0)
else:
listU.append(listULast[0])
u1=np.mean(npData1,axis=0).tolist()[0]
if listULast[1]!=u1[0]:
listU.append(u1)
else:
listU.append(listULast[1])
u2=np.mean(npData2,axis=0).tolist()[0]
if listULast[2]!=u2[0]:
listU.append(u2)
else:
listU.append(listULast[2])
else:
break
finalList0=npData0.tolist()
finalList1=npData1.tolist()
finalList2=npData2.tolist()
ax1=fig.add_subplot(122)
for i in range(len(finalList0)):
ax1.scatter(finalList0[i][0],finalList0[i][1],c='b',marker='^')
for i in range(len(finalList1)):
ax1.scatter(finalList1[i][0],finalList1[i][1],c='r',marker='o')
for i in range(len(finalList2)):
ax1.scatter(finalList2[i][0],finalList2[i][1],c='k',marker='s')
for i in range(len(listU)):
ax1.scatter(listU[i][0],listU[i][1],marker='+',c='k',s=200)
plt.title("K-means Clustering")
plt.show()
以下是运行结果: