第三天 – Spark shuffle – DAG – 广播变量 – 二次排序
一、Spark shuffle
Spark shuffle简介
shuffle操作,是对Spark的RDD操作中调用了一些特殊的算子才会触发的一种操作。shuffle操作,会导致大量的数据在不同节点之间进行传输,因此,shuffle过程是Spark中最复杂且最耗性能的一种操作。
比如,reduceByKey算子会将上一个RDD中的每个key对应的所有value都聚合成一个value,然后生成一个新的RDD,新的RDD的元素类型就是<key, value>形式,每个key对应一个聚合起来的value。在这个过程中,对于上一个RDD来说,并不是一个key对应的所有的value都在一个partition中的,更不太可能key的所有value都在一个节点上。对于这种情况,就必须在集群中将各个节点上的各个分区上的同一个key对应的value统一传输到一个节点上进行聚合处理,这个过程就会发生大量的网络IO导致效率降低。
shuffle过程中分为shuffle write和shuffle read,而且会在不同的stage中进行。在进行一个key对应的value的聚合时,首先,上一个stage的每个map task就必须保证将自己所处理的当前分区中的相同key的数据写入一个分区文件中,可能会产生多个不同的分区文件;接着下一个stage的reduce task就必须从上一个stage的所有task所在的节点上,在各个map task写入的分区文件中找到属于自己的分区文件,然后将属于自己的分区数据拉取到,这样就可以保证每个key对应的所有values都汇聚到一个节点上进行处理和聚合。此过程就成为spark shuffle。
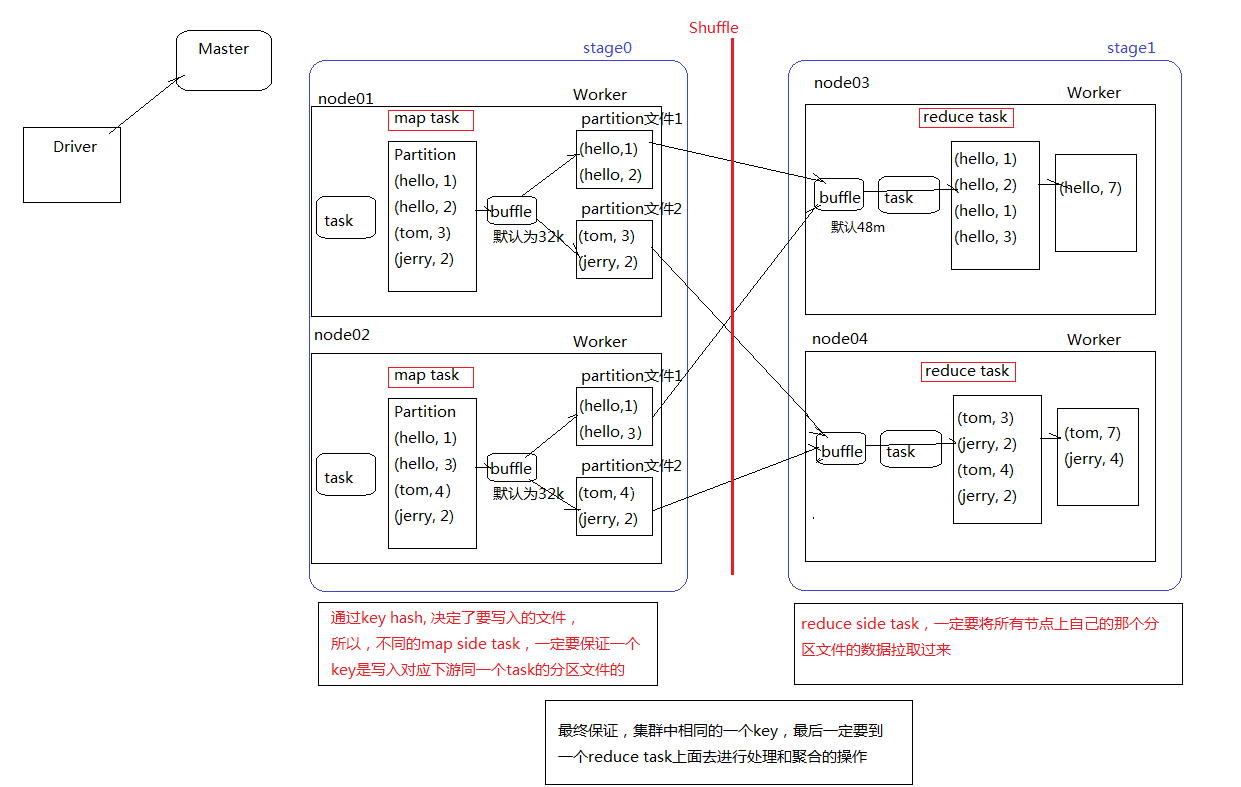
触发shuffle操作的算子
- byKey类的算子:比如reduceByKey、groupByKey、sortByKey、aggregateByKey、combineByKey
- repartition类的算子:比如repartition(少量分区变成多个分区会发生shuffle)、repartitionAndSortWithinPartitions、coalesce(需要指定是否发生shuffle)、partitionBy
- join类的算子:比如join(特殊情况:先groupByKey后再join就不会发生shuffle)、cogroup
注意:对于上述操作,如果能不用shuffle操作就尽量不用。如果使用了shuffle操作,那么就需要对shuffle进行调优,甚至是解决遇到的数据倾斜问题。
shuffle过程中的分区排序问题
默认情况下,shuffle操作是不会对每个分区中的数据进行排序的。如果想要对每个分区中的数据进行排序,可以使用以下三种方法:
- 使用mapPartition算子把每个partition取出来进行排序
- 使用repartitionAndSortWithinPartitions(该算子是对RDD进行重分区的算子),在重分区的过程中同时就进行分区内数据的排序
- 使用sortByKey对所有分区的数据进行全局排序
以上三种方法中,mapPartition的代价比较小,因为不需要进行额外的shuffle操作,而另外两种可能需要进行额外的shuffle操作,性能会降低。
map task和reduce task
为了实时shuffle操作,spark有了stage概念,在发生shuffle操作的算子中,需要进行stage的划分
shuffle操作的前半部分,属于上一个stage的范围,通常称为map task。map task负责数据的组织,也就是将同一个key对应的value都写入到同一个下游task对应的分区文件中。map task会将数据先保存在内存中,如果内存不够时,就溢写到磁盘文件中。
shuffle操作的后半部分,属于下一个stage的范围,通常称为reduce task。reduce task负责数据的聚合,也就是将上一个stage的task所在的节点上,将属于自己的各个分区文件都拉取过来进行聚合。
task的生成,一定是在stage范围内,不会跨越stage。task的数量可以这样计算:RDD分区的数量乘以stage的数量(未进行重分区操作的情况下)
shuffle操作的消耗
shuffle操作会消耗大量的内存,因为无论是网络传输数据之前还是之后,都会使用大量的内存中的数据结构来实施聚合操作,在聚合过程中,如果内存不够,就只能溢写到磁盘文件中去,此时会发生大量的网络IO,降低性能。所以,spark性能的消耗体现在:内存的消耗、磁盘IO、网络的IO
shuffle write和shuffle read
shuffle write:在map task端会法还是能shuffle write,把要shuffle的数据写到磁盘的过程。把数据写到磁盘的原因:主要是为了避免shuffle的数据太大而占用内存太大导致oom(out of memory),其次把数据存储到磁盘保证了数据的安全性。
shuffle read:在reduce task端发生shuffle read,是指下游RDD读取上游RDD的过程,也就是reduce task读取并合并数据的过程
checkpoint流程
应用背景:
在任务执行的过程中,有的中间结果数据或shuffle后的数据很重要,后期的计算过程中会多次调用,为了提高运行效率,可以把数据checkpoint到磁盘或hdfs。注意:在checkpoint之前,最好先把数据层缓存起来,这样便于任务运行时快速调用,也便于在checkpoint的时候直接从缓存里获取数据,这样可以提高获取数据的速度。
步骤:
-
设置checkpoint目录
sc.setCheckpointDir(“hdfs://cdhnocms01:8020/userdata/cp-20181121-1”)
-
把中间结果数据进行缓存
val cachedRDD = rdd.cache
-
做checkpoint
cachedRDD.checkpoint
二、Spark shuffle优化参数
| 属性名称 | 默认值 | 属性说明 |
|---|---|---|
| spark.reducer.maxSizeInFlight | 48m | reduce task的buffer缓冲,代表了每个reduce task每次能够拉取的map side数据最大大小,如果内存充足,可以考虑加大,从而减少网络传输次数,提升性能 |
| spark.shuffle.blockTransferService | netty | shuffle过程中,传输数据的方式,两种选项,netty或nio,spark 1.2开始,默认就是netty,比较简单而且性能较高,spark 1.5开始nio就是过期的了,而且spark 1.6中会去除掉 |
| spark.shuffle.compress | true | 是否对map side输出的文件进行压缩,默认是启用压缩的,压缩器是由spark.io.compression.codec属性指定的,默认是snappy压缩器,该压缩器强调的是压缩速度,而不是压缩率 |
| spark.shuffle.consolidateFiles | false | 默认为false,如果设置为true,那么就会合并map side输出文件,对于reduce task数量特别少的情况下,可以极大减少磁盘IO开销,提升性能 |
| spark.shuffle.file.buffer | 32k | map side task的内存buffer大小,写数据到磁盘文件之前,会先保存在缓冲中,如果内存充足,可以适当加大,从而减少map side磁盘IO次数,提升性能 |
| spark.shuffle.io.maxRetries | 3 | 网络传输数据过程中,如果出现了网络IO异常,重试拉取数据的次数,默认是3次,对于耗时的shuffle操作,建议加大次数,以避免full gc或者网络不通常导致的数据拉取失败,进而导致task lost,增加shuffle操作的稳定性 |
| spark.shuffle.io.retryWait | 5 | 每次重试拉取数据的等待间隔,默认是5s,建议加大时长,理由同上,保证shuffle操作的稳定性 |
| spark.shuffle.io.numConnectionsPerPeer | 1 | 机器之间的可以重用的网络连接,主要用于在大型集群中减小网络连接的建立开销,如果一个集群的机器并不多,可以考虑增加这个值 |
| spark.shuffle.io.preferDirectBufs | true | 启用堆外内存,可以避免shuffle过程的频繁gc,如果堆外内存非常紧张,则可以考虑关闭这个选项 |
| spark.shuffle.manager | sort | ShuffleManager,Spark 1.5以后,有三种可选的,hash、sort和tungsten-sort,sort-based ShuffleManager会更高效实用内存,并且避免产生大量的map side磁盘文件,从Spark 1.2开始就是默认的选项,tungsten-sort与sort类似,但是内存性能更高 |
| spark.shuffle.memoryFraction | 0.2 | 如果spark.shuffle.spill属性为true,那么该选项生效,代表了executor内存中,用于进行shuffle reduce side聚合的内存比例,默认是20%,如果内存充足,建议调高这个比例,给reduce聚合更多内存,避免内存不足频繁读写磁盘 |
| spark.shuffle.service.enabled | false | 启用外部shuffle服务,这个服务会安全地保存shuffle过程中,executor写的磁盘文件,因此executor即使挂掉也不要紧,必须配合spark.dynamicAllocation.enabled属性设置为true,才能生效,而且外部shuffle服务必须进行安装和启动,才能启用这个属性 |
| spark.shuffle.service.port | 7337 | 外部shuffle服务的端口号,具体解释同上 |
| spark.shuffle.sort.bypassMergeThreshold | 200 | 对于sort-based ShuffleManager,如果没有进行map side聚合,而且reduce task数量少于这个值,那么就不会进行排序,如果你使用sort ShuffleManager,而且不需要排序,那么可以考虑将这个值加大,直到比你指定的所有task数量都打,以避免进行额外的sort,从而提升性能 |
| spark.shuffle.spill | true | 当reduce side的聚合内存使用量超过了spark.shuffle.memoryFraction指定的比例时,就进行磁盘的溢写操作 |
| spark.shuffle.spill.compress | true | 同上,进行磁盘溢写时,是否进行文件压缩,使用spark.io.compression.codec属性指定的压缩器,默认是snappy,速度优先 |
三、DAG
DAG简介
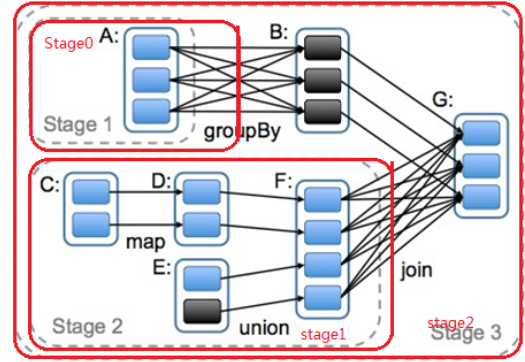
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
DAG的stage划分
从最后一个RDD往前,当遇到一个宽依赖时,进行切分,继续往前同上操作,直到进行到首个RDD终止。此时从头开始划分,每遇到一个宽依赖的切分,就可以划分为一个stage,直到最后,将整个过程需要划分为一个stage。
-
案例一:简单的wordCount的stage划分
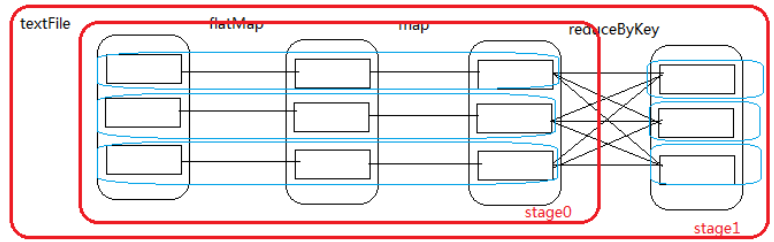
-
案例二:
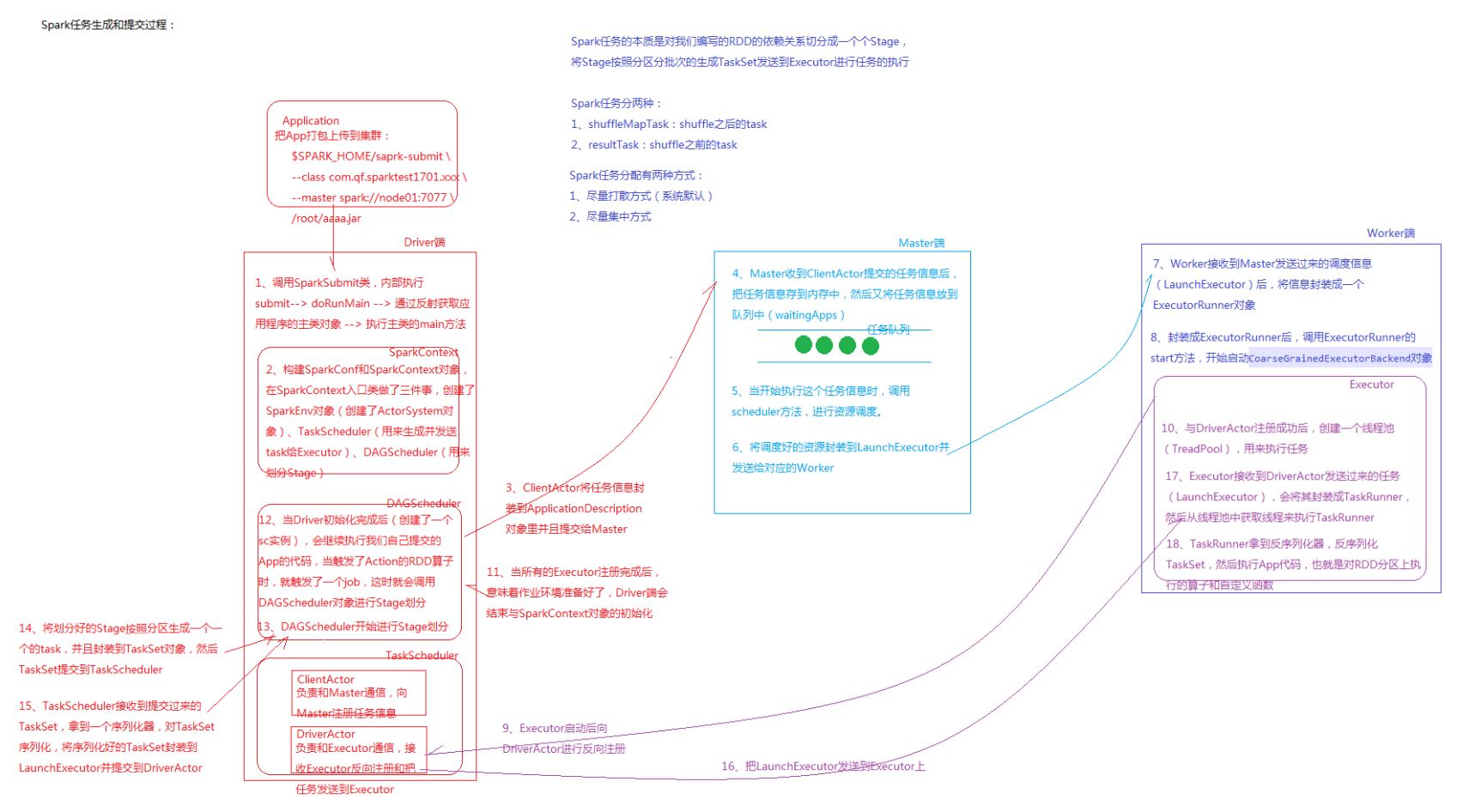
四、Spark任务生成和提交过程详解
五、广播变量
应用背景
在Executor进行计算的过程中,有些变量的值会在Executor多次使用,每次使用时,就要从driver端拿取一次,会产生大量的网络IO,影响计算效率,此时可以使用广播变量的方式,在计算之前先把数据从driver端广播到相应的Executor端的缓存里,后期在使用的时候,就可以直接从缓存里拿取进行计算
注意:广播变量的过程,必须是把driver端的某个变量的值广播到Executor端,广播变量的值不宜过大,否则会占用大量内存
案例:根据ip统计区域访问量
数据:点击下载
需求:按照用户ip统计区域访问量
实现思路:
- 将用户访问的log日志中的ip拿到并转换为Long类型的ip
- 把ip基础数据获取并放到Array中
- 通过用户ip从ip基础数据中找到ip对应的索引以及对应的省份
- 统计每个省份的访问量
import java.sql.{Connection, Date, DriverManager, PreparedStatement}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:按照用户ip统计区域访问量
* 实现思路:
* 1.将用户访问的log日志中的ip拿到并转换为Long类型的ip
* 2.把ip基础数据获取并放到Array中
* 3.通过用户ip从ip基础数据中找到ip对应的索引以及对应的省份
* 4.统计每个省份的访问量
*/
object IPSearche {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ipsearch").setMaster("local[2]")
val sc = new SparkContext(conf)
// 获取ip基础数据并进行切分
val ipInfo: RDD[(String, String, String)] = sc.textFile("F:/scaladata/data/ipsearch/ip.txt").map(line => {
val fields = line.split("\\|")
val startIP = fields(2) // 起始ip
val endIP = fields(3) // 结束ip
val province = fields(6) // 省份
(startIP, endIP, province)
})
// 将ip基础数据拿到driver端并放在一个数据里
val arrIPInfo: Array[(String, String, String)] = ipInfo.collect()
// 将ip基础数据进行广播
val broadcastIPInfo: Broadcast[Array[(String, String, String)]] = sc.broadcast(arrIPInfo)
// 获取用户访问日志并切分,统计出ip所属省份
val provinceInfo: RDD[(String, Int)] = sc.textFile("F:/scaladata/data/ipsearch/http.log").map(line => {
val fields = line.split("\\|")
val ip = fields(1) // 用户ip
val ipToLong = ip2Long(ip) // 得到long类型的ip
// 获取广播过来的ip基础数据
val arrIpInfo = broadcastIPInfo.value
// 通过二分查找找到用户ip属于arrIPInfo的索引
val index = binarySearch(arrIpInfo, ipToLong)
// 根据索引查找对应的省份
val province = arrIpInfo(index)._3
(province, 1)
})
// 聚合得到省份访问量
val sumedProvinceInfo: RDD[(String, Int)] = provinceInfo.reduceByKey(_+_)
//println(sumedProvinceInfo.collect.toBuffer)
// 此时调用foreachPartition,目的是一个数据库的连接对应一个分区,这样可以减少创建数据库的连接数
sumedProvinceInfo.foreachPartition(data2MySql)
sc.stop()
}
/**
* 将ip地址转换为Long类型
* @param str
*/
def ip2Long(ip: String): Long ={
val fragments: Array[String] = ip.split("[.]")
var ipNum = 0L
for(i <- 0 until fragments.length){
ipNum = fragments(i).toLong | ipNum << 8L
}
ipNum
}
/**
* 二分查找
* @param arr
* @param ip
* @return
*/
def binarySearch(arr: Array[(String, String, String)], ip: Long): Int ={
var start = 0
var end = arr.length - 1
while (start <= end){
val middle = (start + end) / 2
if((ip >= arr(middle)._1.toLong) && (ip <= arr(middle)._2.toLong)){
return middle
} else if (ip < arr(middle)._1.toLong){
end = middle - 1
} else {
start = middle + 1
}
}
-1
}
/**
* 把结果存储到mysql函数
*/
val data2MySql = (it: Iterator[(String, Int)]) => {
var conn:Connection = null
var ps: PreparedStatement = null
val sql = "insert into location_info (location, counts, access_date) values(?,?,?)"
val jdbcUrl = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf8"
val user = "root"
val password = "root"
try {
conn = DriverManager.getConnection(jdbcUrl, user, password)
it.foreach(line => {
ps = conn.prepareStatement(sql)
ps.setString(1, line._1)
ps.setInt(2, line._2)
ps.setDate(3, new Date(System.currentTimeMillis()))
ps.executeUpdate()
})
} catch {
case e:Exception => println(e.printStackTrace())
} finally {
if (ps != null) ps.close()
if (conn != null) conn.close()
}
}
}
六、自定义排序(二次排序)
应用场景
比如定义了一个对象,该对象有多个字段,需要对多个字段进行排序,如果直接调用sortyBy排序,会无法得到想要的结果,因为sortBy不知道具体的排序规则。此时可以使用Spark提供的自定义排序进行操作,可以自定义具体的排序规则。
案例:根据颜值和年龄排序
CustomSort.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CustomSort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ipsearch").setMaster("local[2]")
val sc = new SparkContext(conf)
val girlInfo = sc.parallelize(Array(("mimi", 90, 34), ("yuanyuan", 85, 32), ("bingbing", 90, 35)))
// 第一种排序方式
/*val res: RDD[(String, Int, Int)] = girlInfo.sortBy(_._2,false)
println(res.collect.toBuffer)*/
/*import MyPredef.girlOrdering
val res: RDD[(String, Int, Int)] = girlInfo.sortBy(girl => Girl(girl._2, girl._3),false)
println(res.collect.toBuffer)*/
// 第二种排序方式
val res: RDD[(String, Int, Int)] = girlInfo.sortBy(girl => Girl(girl._2, girl._3),false)
println(res.collect.toBuffer)
}
}
// 第一种排序方式
//case class Girl(fv:Int, age:Int)
// 第二种排序方式
// 根据fv,fv大的排前面,如果相同根据age,age小的在前
case class Girl(fv:Int, age:Int) extends Ordered[Girl] {
override def compare(that: Girl): Int = {
if (this.fv == that.fv) {
that.age - this.age
} else {
this.fv - that.fv
}
}
}
MyPredef.scala
// 第一种排序方式
// 根据fv,fv大的排前面,如果相同根据age,age小的在前
object MyPredef {
implicit val girlOrdering = new Ordering[Girl]{
override def compare(x: Girl, y: Girl): Int = {
if (x.fv == y.fv){
y.age - x.age
} else {
x.fv - y.fv
}
}
}
}
七、Spark提供的JdbcRDD
Spark提供了JdbcRDD,用来连接关系型数据库,不过只能读取数据,无法完成增删改操作。
import java.sql.{Date, DriverManager}
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
object JDBCRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ipsearch").setMaster("local[2]")
val sc = new SparkContext(conf)
val jdbcUrl = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf8"
val user = "root"
val password = "root"
//由于jdbcRDD的参数需求,需要给定一个查找范围,所以sql语句中需要加查询的范围条件
val sql = "select id, location, counts, access_date from location_info where id >= ? and id <= ?"
val conn = () => {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection(jdbcUrl,user,password)
}
val jdbcRDD: JdbcRDD[(Int, String, Int, Date)] = new JdbcRDD(
sc, //SparkContext
conn, //jdbc连接
sql, //sql语句
0, //下界,对应sql语句中的id >= ?
500, //下界,对应sql语句中的id <= ?
1, //分区数
res => { //返回结果
val id = res.getInt("id")
val location = res.getString("location")
val counts = res.getInt("counts")
val access_date = res.getDate("access_date")
(id, location, counts, access_date)
}
)
jdbcRDD.foreach(f => println(f))
sc.stop()
}
}