一,Spark专业术语的解析
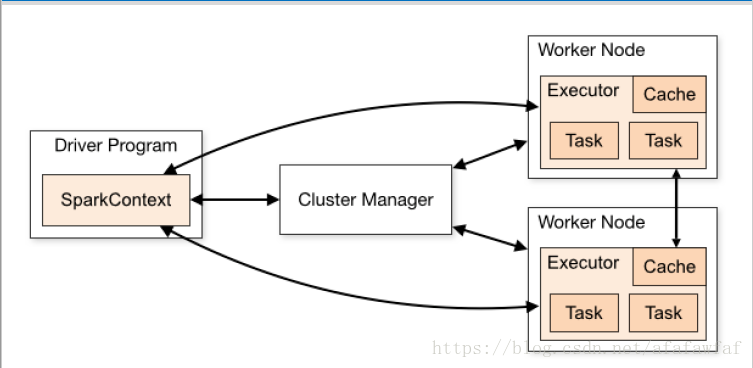
1,Application基于Spark的用户程序,包含了driver程序和集群上的executor
2,Driver Program运行main函数并且新建SparkContext的程序
3,Cluster Manager在集群上获取资源的外部服务(例如standalone,Mesos,Yarn)
4,Worker Node是集群中任何可以运行用代码的节点
5,Executor是在一个worker node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用都有各自独立的executors
6,Task是被送到某个executor上的工作单元
7,Job包含很多任务的并行计算,可以看做和Spark的action对应
8,Stage一个Job会被拆分很多组任务,每组任务被称为Stage(就像Mapreduce分map任务和reduce任务一样)
二,Spark窄依赖和宽依赖的慨念

如上图表示方框表示RDD,实心矩形表示分区(partitions)
1,窄依赖表示的是子RDD的分区只是到父RDD的分区(一对一)
2,宽依赖表示的是子RDD的分区到父RDD的多个分区(多对多),就会产生shuffer操作
三,SparkDAG的慨念

1,DAG表示的有方向没有回路的线路图
2,Application会划分Job,Job划分Stage,Statge会划分为task,从而这样会构建DAG
3,Stage的划分是根据窄依赖和宽依赖,如果是遇到一个宽依赖,前面的所有RDD就会划分为Stage
4,task是Spark里面的最小计算单元,它会封装你的逻辑计算,而task的划分是根据你第一个RDD到最后生成的RDD的连线来划分
四,SparkDAG的优化

1,从图中一个Stage内的窄依赖进行pipeline操作,这样就Spark就会找到它的最佳计算位置,一次性进行计算完毕,减少不必要的网络IO
2,Spark的DAG本质的优化主要程序员如何设计DAG,如何划分Stage,尽量多一点的窄依赖,这样就会大大加快了Spark计算速率