模型训练
- 模型选择
对于特定任务最优建模方法的选择或者对特定模型最佳参数的选择
- 交叉验证
在训练数据集上运行模型(算法)并且在测试数据集上测试效果,迭代 更新数据模型的修改,这种方式被称为“交叉验证”(将数据分为训练集 和 测试集),使用训练集构建模型,并使用测试集评估模型提供修改建议。
模型的选择会尽可能多的选择算法进行执行,并比较每个算法的执行结果
模型测试
模型的测试一般从以下几个方面来进行比较:准确率、召回率、精确率、F值、ROC、AUC
- 混淆矩阵
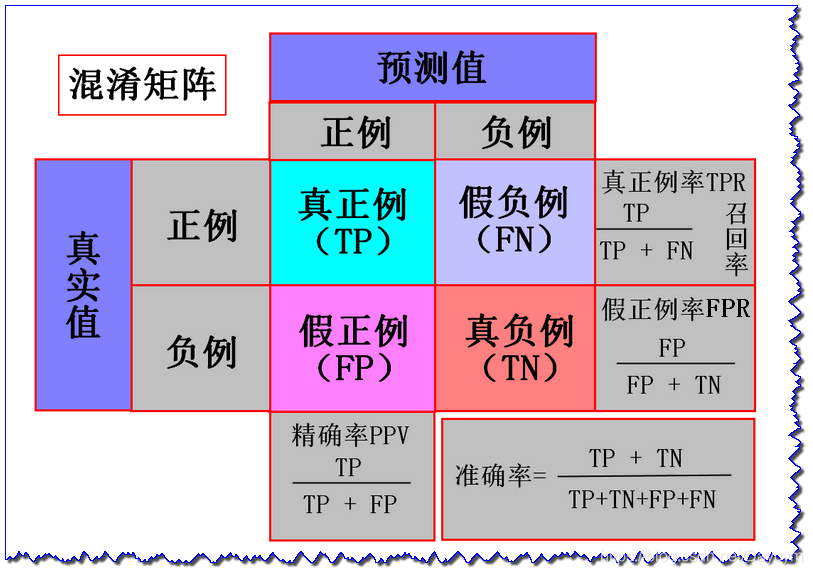
- 准确率
准确率(Accuracy) = 提取出的正确样本数/总样本数
- 召回率
召回率(Recall) = 正确的正例样本数/样本中正例样本数 ——覆盖率
- 精确率
精确率(Precision) = 正确的正例样本数/预测为正例的样本数
- F值
F值 = Precision * Recall * 2 / (Precision + Recall)
即正确率和召回率的调和平均值
- ROC
ROC描述的是分类混淆矩阵中FPR-TPR两个量之间的相对变化情况,ROC曲线的纵轴是“真正例率(TPR)”,横轴是“假正例率(FPR)”。
如果二元分类输出的是对正样本的一个分类概率值,当去不同阀值时会得到不同的混淆矩阵,对应于ROC曲线上的一个点。那么ROC曲线就反映了FPR和TPR之间权衡的情况,通俗地来说,即在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题。
TPR增长得越快,曲线越往上屈,AUC就越大,反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。
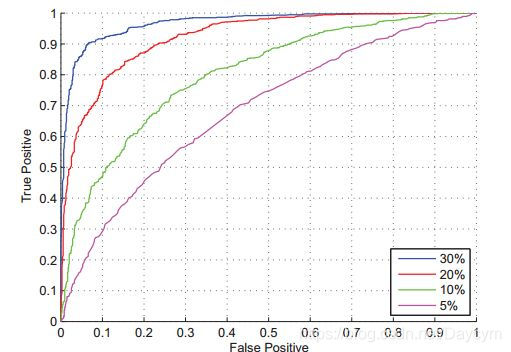
- AUC
AUC的值越大表示模型越好
AUC被定义为ROC曲线下的面积,显然这个面积的数值不会大于1,又由于ROC曲线一般都处于 这条直线的上方,所以AUC取值范围在0.5和1之间。
使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阀值都能得出完美预测。绝大数预测的场合,不存在完美分类器;
AUC = 0.5,跟随机猜测一样,模型没有预测价值;
0.5 < AUC < 1,由于随机猜测,妥善设定阀值,有预测价值;
AUC < 0.5,比随机猜测还差,但只要总是反预测而行,比随机猜测好。
模型评估
- 回归算法评估方式
| 指标 | 描述 | scikit-learn函数 |
|---|---|---|
| Mean Square Error(MSE, RMSE) | 平均误差 | from sklearn.metrics import mean_squared_error |
| Absolute Error(MAE, RAE) | 绝对误差 | from sklearn.metrics import mean_absolute_error,median_absolute_error |
| R-Squared | R平方值 | from sklearn.metrics import r2_score |
- 分类算法评估方式
| 指标 | 描述 | scikit-learn函数 |
|---|---|---|
| Precision | 精确度 | from sklearn.metrics import precision_score |
| Recall | 召回率 | from sklearn.metrics import recall_score |
| F1 | F1值 | from sklearn.metrics import f1_score |
| Confusion Matrix | 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| ROC | ROC曲线 | from sklearn.metrics import roc |
| AUC | ROC曲线下的面积 | from sklearn.metrics import auc |