#导包
import sklearn
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
import matplotlib
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
#创造数据
import pandas as pd
np.random.seed(40)
x = np.arange(10,110)
# print(x.shape)
x_shift = np.random.normal(size=x.shape) #生成100个正太分布数据
x = x+x_shift
# print(x_shift)
# #直方图展示数据
# data = pd.DataFrame(x_shift)
# data.plot(kind='hist')
error = np.random.normal(size=x.shape)*30 # 噪声/误差
y = 2 * x + 5 + error
# print(y)
# plt.plot(kind='scatter',x,y)
plt.scatter(x,y)
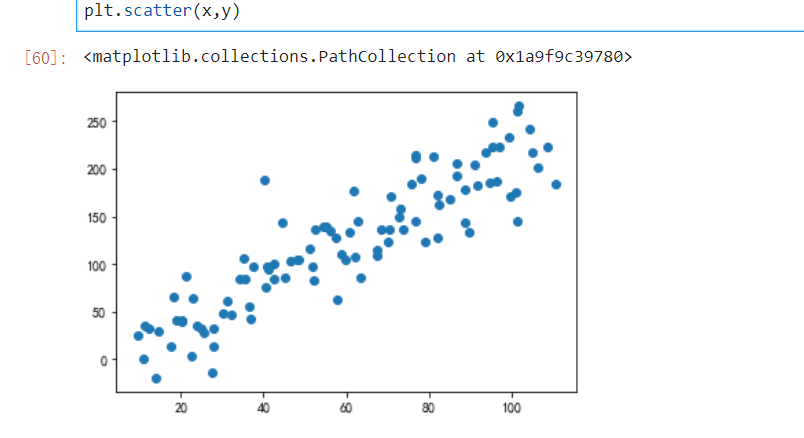
#分割数据集
from sklearn.model_selection import train_test_split
dataset = [(i,j) for i,j in zip(x,y)] #整合x和y
# print(dataset)
train_selt,test_set = train_test_split(dataset,test_size=0.2,random_state=30)
print(len(train_set)) #80
trainX = np.array([i for i,j in train_selt]).reshape(-1,1)
trainY = np.array([j for i,j in train_selt]).reshape(-1,1)
testX = np.array([i for i,j in test_set]).reshape(-1,1)
testY = np.array([j for i,j in test_set]).reshape(-1,1)

#训练模型

from sklearn import linear_model
# 构造线性回归器
linear_regressor = linear_model.LinearRegression()
linear_regressor.fit(trainX,trainY)
# 此处预测trainX
y_predict = linear_regressor.predict(trainX)
# print(y_predict)
plt.scatter(trainX,y_predict,marker='*',label='预测点')
plt.scatter(trainX,trainY,marker='>',label='原始点')
plt.legend()
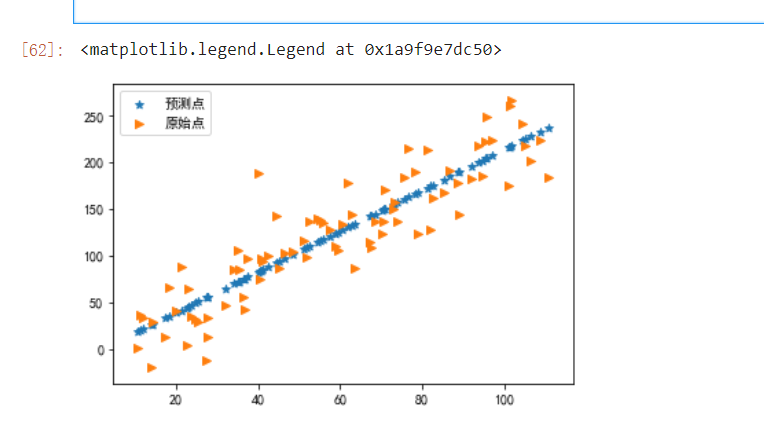
#查看模型得分
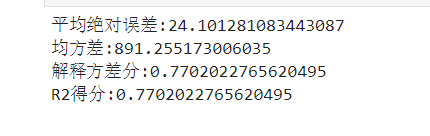
from sklearn import metrics
print('平均绝对误差:{}'.format(metrics.mean_absolute_error(y_predict,trainY)))
print('均方差:{}'.format(metrics.mean_squared_error(y_predict,trainY)))
print('解释方差分:{}'.format(metrics.explained_variance_score(y_predict,trainY)))
print('R2得分:{}'.format(metrics.r2_score(y_predict,trainY)))
#在测试集上验证模型
from sklearn import linear_model
# # 此处预测trainX
y_predict = linear_regressor.predict(testX)
# print(y_predict)
plt.scatter(testX,y_predict,marker='*',label='预测点')
plt.scatter(testX,testY,marker='>',label='原始点')
plt.legend()
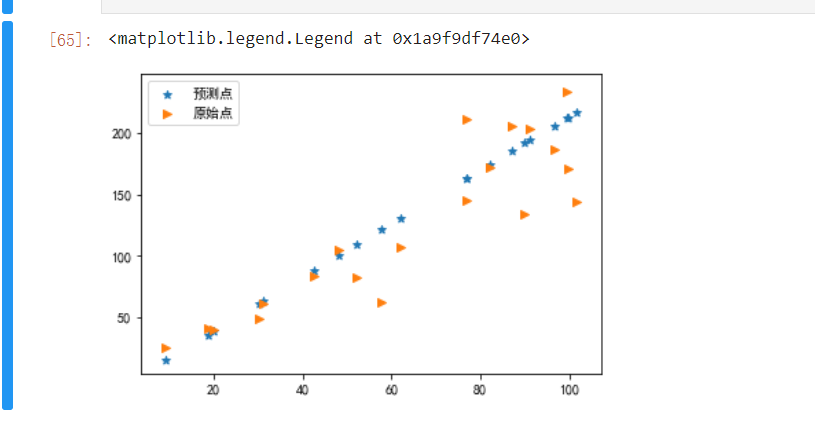
#模型的保存与加载
#保存路径
save_path = './linearmodel.txt'
from sklearn.externals import joblib
#模型的保存
joblib.dump(linear_regressor,save_path)
#模型的加载
mymodel = joblib.load(save_path)
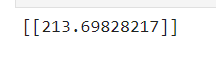
result = mymodel.predict([[100]])
k = mymodel.coef-[0][0]
b = mymodel.intercept_[0]
fy = K*100 + 6
print(result)
#生成txt文件
