《Python深度学习中文版》部分内容+自己总结
概述
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。
为什么不是两个集合:一个训练集和一个测试集?
为什么不是两个集合:一个训练集和一个测试集?在训练集上训练模型,然后在测试集上评估模型。这样简单得多!
原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。
因此,如果基于模型在测试集上的性能来调节模型配置,会很快导致模型在测试集上过拟合,即使你并没有在测试集上直接训练模型也会如此。
这样会导致你的模型好像是专门为测试集所设的,该模型在测试集上的准确率特别高,损失特别少。但是这样是没有任何意义的,你无法评估出该模型在除训练集和测试集以外的性能。
而原本测试集是来测试我们的模型是否能在训练集以外的数据上能有很好的性能。要求是你的模型一定不能读取与测试集有关的任何信息,既使间接读取也不行。如果基于测试集性能来调节模型,那么对泛化能力的衡量是不准确的。
机器学习的目的是得到可以泛化(generalize)的模型,即在前所未见的数据上表现很好的模型,而过拟合则是核心难点。
那我们怎么解决?
就是再设一个集合,验证集,与训练集与测试集完全不同
具体方法
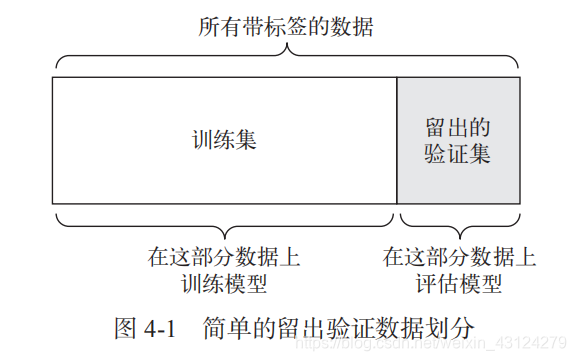
1. 简单的留出验证
“所有带标签的数据” 中的 “数据” 指的是训练集+验证集,即非测试集
num_validation_samples = 10000
np.random.shuffle ( data ) # 通常需要打乱数据
validation_data = data[:num_validation_samples] # 定义验证集
training_data = data[num_validation_samples:] # 定义训练集
# 在训练集上训练数据,并在验证数据上评估模型
model = get_model ()
model.train ( training_data )
validation_score = model.evaluate ( validation_data )
# 现在你可以调节模型、重新训练、评估,然后再次调节……
# 其实就是重复进行上一步
# 调节模型配置:比如选择层数或每层大小
# [这叫作模型的`超参数(hyperparameter)`,以便与模型参数(即权重)区分开]。
# 一旦调节好超参数,通常就在所有非测试数据上从头开始训练最终模型,
# 并在测试集上进行评估
model = get_model ()
# 或者 model.train ( data )
model.train ( np.concatenate ( [validation_data,
training_data] ) )
test_score = model.evaluate ( test_data )
这是最简单的评估方法,但有一个缺点:如果可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据。这个问题很容易发现:如果在划分数据前进行不同的随机打乱,最终得到的模型性能差别很大,那么就存在这个问题。接下来会介绍 K 折验证与重复的 K 折验证,它们是解决这一问题的两种方法。
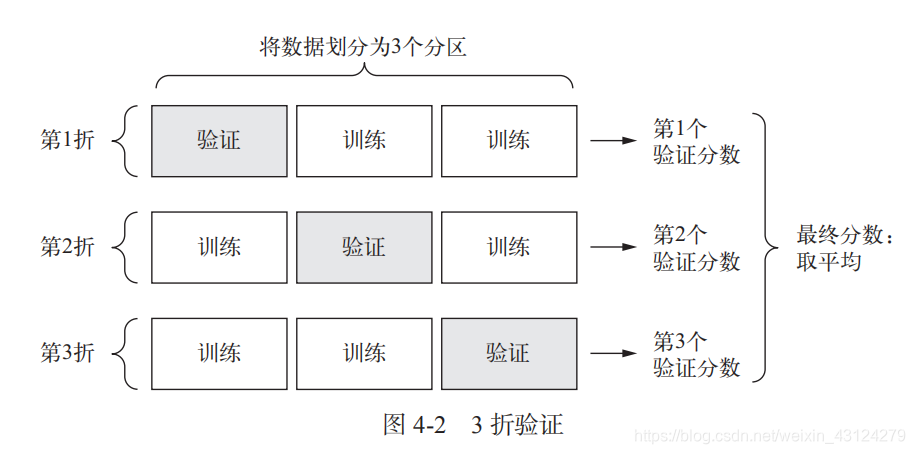
2. K折验证
“将数据划分为3个分区”中的 “数据” 指的是训练集+验证集,即非测试集
k = 3
num_validation_samples = len ( data ) # k
np.random.shuffle ( data )
validation_scores = []
for fold in range ( k ):
# 选择第k折(fold)中的验证数据
validation_data = data[num_validation_samples * fold:
num_validation_samples * (fold + 1)]
# 选择第k折(fold)中的训练数据
training_data = data[:num_validation_samples * fold] + \
data[num_validation_samples * (fold + 1):]
model = get_model () # 创建一个全新的模型实例(未训练)
model.train ( training_data )
validation_score = model.evaluate ( validation_data )
validation_scores.append ( validation_score )
# 最终验证分数:K折验证分数的平均值
validation_score = np.average ( validation_scores )
# 现在你可以调节模型、重新训练、评估,然后再次调节……
# 其实就是重复进行上一步
# 调节模型配置:比如选择层数或每层大小
# [这叫作模型的`超参数(hyperparameter)`,以便与模型参数(即权重)区分开]。
# 一旦调节好超参数,通常就在所有非测试数据上从头开始训练最终模型,
# 并在测试集上进行评估
model = get_model ()
model.train ( data )
test_score = model.evaluate ( test_data )
3. 带有打乱数据的重复 K 折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复 K 折验证(iterated K-fold validation with shuffling)。我发现这种方法在 Kaggle 竞赛中特别有用。具体做法是多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是每次 K 折验证分数的平均值。注意,这种方法一共要练和评估 P×K 个模型(P是重复次数),计算代价很大。
