机器学习有两个非常重要的问题:
1.How well is my model doing?
如果我们已经训练好了模型,该模型效果如何,用什么方式来检为测?
2.How do we improve the model based on these metrics?
如何根据这些检测指标改善模型。
如何合理,科学,有效的评估和改善模型,是所有机器学习算法通用问题,因此单独总结以下
1.分离数据:
将数据分为训练集和测试集
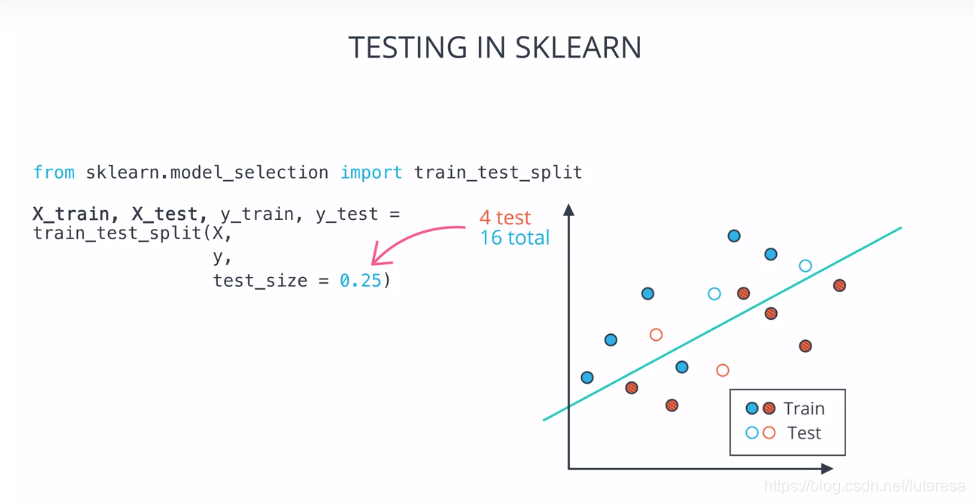
注意: ;
# Import statements
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
# Import the train test split
# http://scikit-learn.org/0.16/modules/generated/sklearn.cross_validation.train_test_split.html
# USE from sklearn.model_selection import train_test_split to avoid seeing deprecation warning.
from sklearn.model_selection import train_test_split
#from sklearn.cross_validation import train_test_split
# Read in the data.
data = np.asarray(pd.read_csv('data.csv', header=None))
# Assign the features to the variable X, and the labels to the variable y.
X = data[:,0:2]
y = data[:,2]
# Use train test split to split your data
# Use a test size of 25% and a random state of 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# Instantiate your decision tree model
model = DecisionTreeClassifier()
# TODO: Fit the model to the training data.
model.fit(X_train, y_train)
# TODO: Make predictions on the test data
y_pred = model.predict(X_test)
# TODO: Calculate the accuracy and assign it to the variable acc on the test data.
acc = accuracy_score(y_test, y_pred)
print(acc)
0.9583333333333334
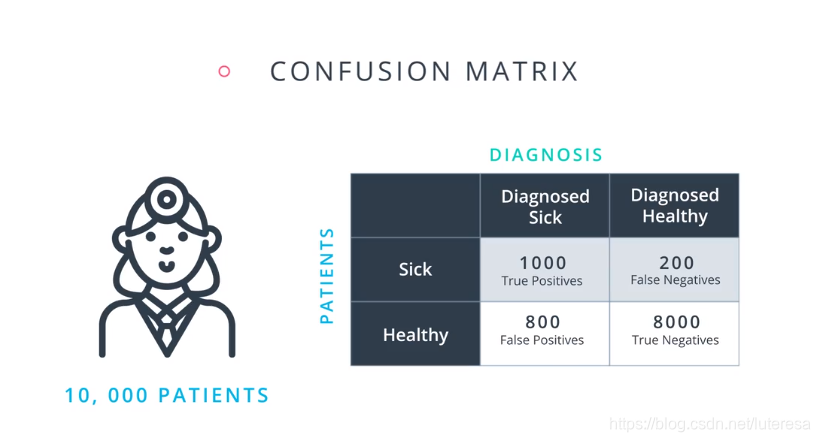
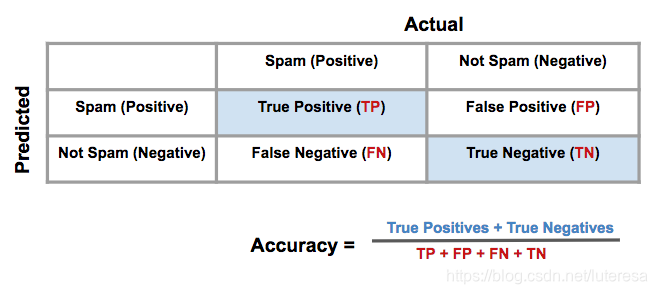
2.混淆矩阵(evaluation matrix)
比如医疗模型,检测结果可以分为四种境况;
真阳性:就诊者患病,模型检测为阳性,认为患病需要进一步检测或治疗;
真阴性:就诊者未患病,模型检测为阴性,认为患者健康,可以直接回家;
假阳性:就诊者未患病,模型检测为阳性,认为患病需要进一步检测或治疗;
注意此情况属于误诊,进一步检测会浪费医疗资源,但是可确保病人得到医治;
假阴性:就诊者患病,模型检测为阴性,认为患者健康,可以直接回家;此情况属于误诊,并且会让患者失去治疗机会;
类型1和类型2错误
有时在一些文档中,你会看到把假阳性和假阴性称为类型1和类型2错误。这是定义:
类型1错误(第一类错误或假阳性):在医学诊断例子中,这是我们误诊一个健康人为病人
类型2错误(第二类错误或假阴性):在医学诊断例子中,这是我们漏诊一个病人为健康人
画成矩阵图如下:
而对于垃圾邮件分类模型:

3.分类模型评估
3.1 准确率(accuracy)
评估模型效果的第一个指标,是准确率
比如上述医疗模型:

垃圾邮件分类模型:

用sklearn库的模型可方便计算:
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
准确率不适用的情形
假设一个检测信用卡欺诈模型,有大量真实交易数据,
有284335笔正常交易,472笔欺诈交易,现在尝试设计一个准确率超过99%的模型。
假设所有交易都是正常的,其准确率:

这个模型准确率非常高,但实际上没有检测出一例欺诈交易。而模型设计主要目标就是检测出欺诈交易。
所以,不同类别的样本比例非常不均衡时,占比大的类别往往称为影响准确率的最主要因素。
对于以上误检的两种情况,假阳性和假阴性,哪种更糟糕呢:
医疗模型:
假阳性,即将健康人误诊为病人,进一步检测或治疗,会浪费医疗资源;
假阴性,将病人误诊为健康,这让病人直接回家,错过了治疗机会;
这个模型的目标是找到所有病人,可以容忍部分将健康人误诊为病人。相比,假阴性更严重。
垃圾邮件分类模型:
假阳性,将正常邮件误检为垃圾邮件,会漏过一些重要邮件;
假阴性,即垃圾邮件误检为正常邮件,这会浪费一定资源;
这个模型的目标是,删除掉垃圾邮件,但是不能容忍误删,假阴性只会浪费点时间,但假阳性可能会错过很重要邮件。
相比,假阳性更严重。
从医疗模型和垃圾邮件分类模型,可以看到不同模型,设计目标不同,对误检的容忍也不一样。
3.2 精确率和召回率
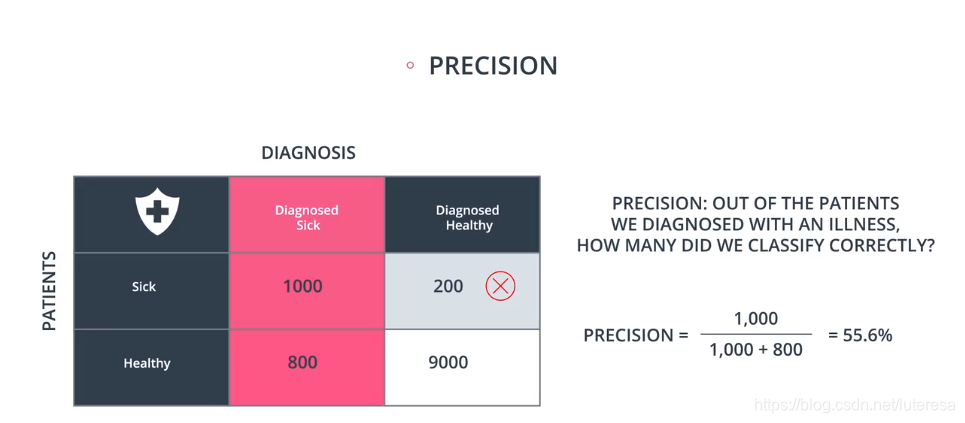
精确率定义:
按以上定义,医疗模型准确率:
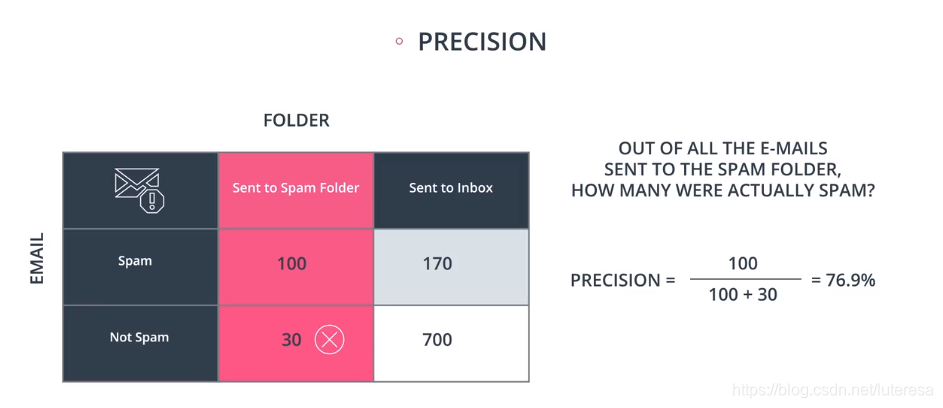
垃圾邮件检测模型:
对于医疗模型,我们可以忽略假阴性,追求更高的精度:
召回率定义:
按以上定义,医疗模型召回率:
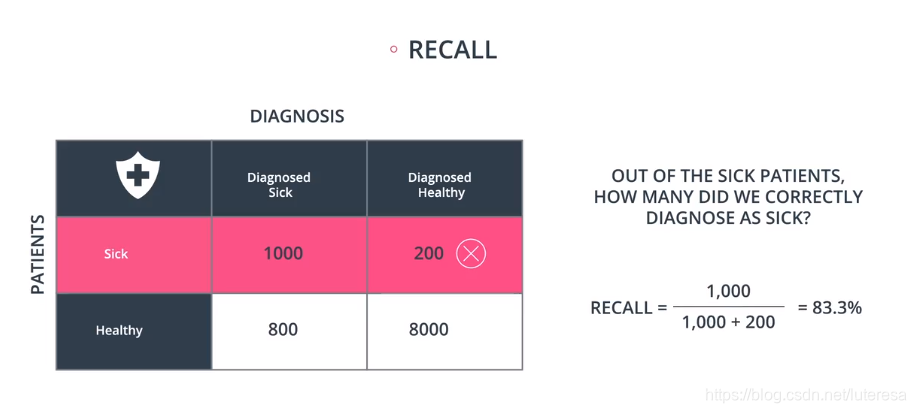
垃圾邮件检测模型:

医疗模型,要尽量排除假阴性,需要更高的召回率,尽可能多的检测出所有病人。
垃圾邮件模型,更在意的是避免假阳性,即删除正常的邮件,需要更高的精确率。
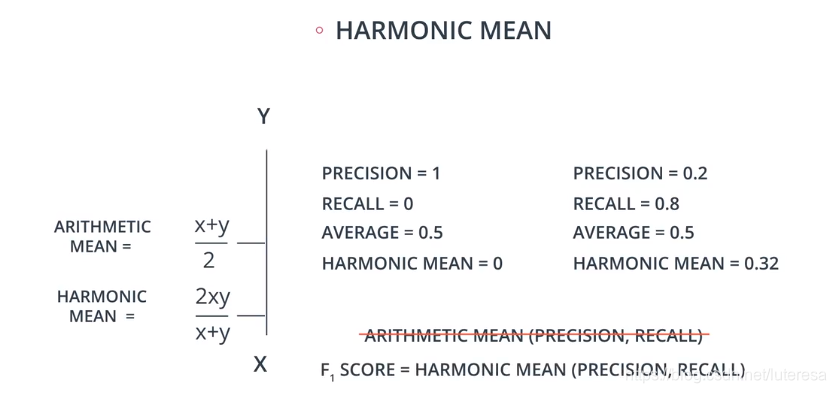
3.3 F1得分
综合精确率和召回率,统一成一个指标来表述模型效率,精确率的和召回率的调和平均值

也叫F1 scroe
调和平均值,总是处于Precision,Recall之间,偏向较小值,
3.4 F-Beta得分
F1分数是将精确率和召回率取相同权重,假如需求要偏向某一方,精确率或召回率,可以用F-Beta得分

F-β 得分的界限
越小,越偏重于精确率,反之偏向召回率, =1, 权重相同,也就是F1 分数。
当
=0
如果
非常大,
随着 变成无穷大,可以看出$ \frac{1}{1+\beta^2}$ 变成 0,并且 变成1.
取极限,
因此,测出结论: 界限是0和∞之间。
如果 ,得到精确率;
如果 ,得出召回率;
如果 ,则得出精确率和召回率的调和平均值。
3.5 ROC曲线
受试者工作特性曲线(receiver operating characteristic),简称ROC曲线。
ROC曲线的横坐标为假阳性率(False Positive Rate, FPR);纵轴为真阳性率(True Positive Rate, TPR),FPR和TPR的计算方法为
上式中,P是真实正样本数量,N是真实负样本数量,TP是P个样本中分类器预测正样本数量,FP是N个负样本中,分类器预测为负样本个数。
如何绘制ROC曲线
通过不断移动分类器的"截断点"来生成曲线上的一组关键点。
所谓截断点,就是设置一个阈值,每个样本预测为阳性的概率,超过这个阈值,即判为阳性,否则为阴性。
每个截断点,求相对应的FPR和TPR,以FPR为横轴,TPR为纵轴,描出所有点,连成曲线。
如何计算AUC
AUC就是ROC曲线下的面积大小,该值可以量化的反映基于ROC曲线衡量出的模型性能。计算AUC,沿着横轴求ROC曲线积分即可。
AUC越大,说明分类器可能把真正的正阳本排在前面,分类性能越好。
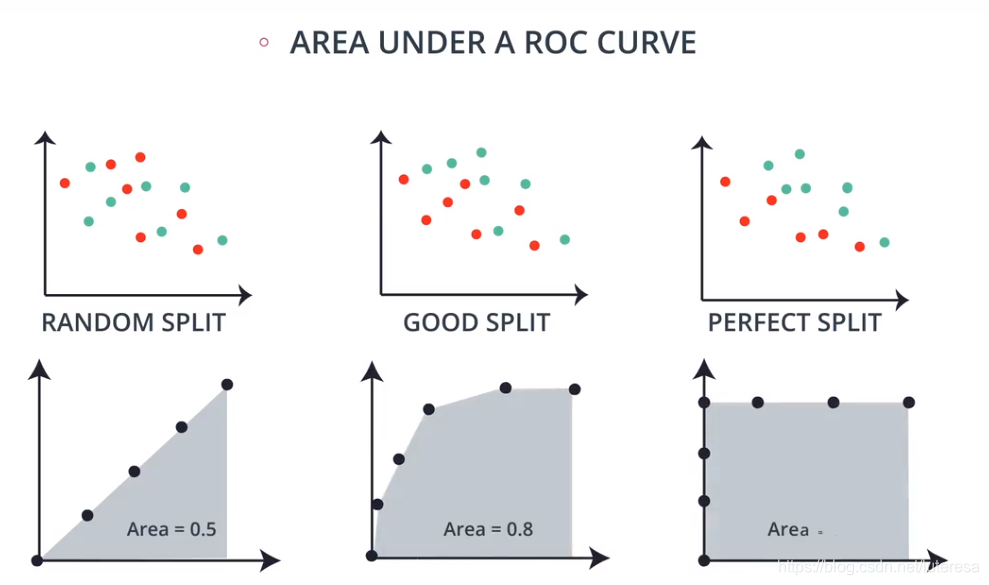
AUC一般在0.5~1之间,如果小于0.5,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器。
ROC曲线相比P-R曲线有什么特点
P-R曲线,是以召回率为横轴,精确率为纵轴的曲线。
当正负样本比例出现较大改变时,P-R曲线变化较大,而ROC曲线形状基本不变。
t201.png(图片在手机,后面补上)
这个特点让ROC曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。
绘制roc代码实现
def build_roc_auc(model, X_train, X_test, y_train, y_test):
'''
INPUT:
model - an sklearn instantiated model
X_train - the training data
y_train - the training response values (must be categorical)
X_test - the test data
y_test - the test response values (must be categorical)
OUTPUT:
auc - returns auc as a float
prints the roc curve
'''
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn.metrics import roc_curve, auc, roc_auc_score
from scipy import interp
y_preds = model.fit(X_train, y_train).predict_proba(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(len(y_test)):
fpr[i], tpr[i], _ = roc_curve(y_test, y_preds[:, 1])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_preds[:, 1].ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=2, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.show()
return roc_auc_score(y_test, np.round(y_preds[:, 1]))
# Finding roc and auc for the random forest model
build_roc_auc(rf_mod, training_data, testing_data, y_train, y_test)
4 回归模型评估
4.1平均绝对误差
就是将样本点到直线的距离绝对值的和;

平均绝对误差有个问题,绝对值函数是不可微分的,这不利于使用如梯度下降等方法。
为解决这个问题,一般用均方误差。
4.2均方误差
在sklearn也很容易实现

4.3 R2分数
通过将模型与最简单的可能模型相比得出

在sklearn的实现:

5 小结
训练和测试数据
首先, 每次都要把你的数据划分为训练集和测试集,这很重要。先把模型在训练集数据上拟合好,然后你就可以用测试集数据来评估模型性能。
评估分类
如果你正在训练模型来预测分类(是否是垃圾邮件),比起预测具体数值(例如房价),有很多不同的评估方法来评估你的模型的性能。
当我们看分类指标时,这个主题的维基百科页面非常精彩,但也有点难度。我经常用它来记忆各个指标做什么。
具体来说,你看到了如何计算:
准确度
准确度通常用来比较模型,因为它告诉我们正确分类的比例。
通常准确度不应是你要优化的唯一指标。尤其是当你的数据存在类别不平衡情况时,只优化准确度可能会误导你对模型真实性能的评估。考虑到这一点,我们介绍了一些其他指标。
精度
精度主要关注的是数据集中预测 为“阳性”的数据。通过基于精度的优化,你将能确定与误报假阳性相比,你是否在预测正例的工作上做的很好(减少误报假阳性)。

召回率
召回率主要关注数据集中的实际 “阳性”的数据。通过基于召回率的优化,你将能确定你是否在预测正例的工作上做的很好(减少漏报假阴性),而不必太考虑误报假阳性。如果你想在实际 ‘负例’上执行类似召回率的计算,这叫做特异性(specificity)。

F-Beta 分数
为同时考察两个指标(精度和召回率)的组合,有一些常用技术,如 F-Beta 分数(其中经常使用 F1 分数),以及 ROC 和 AUC。你可以看到 \betaβ 参数控制了精度在 F 分数中的权重,它允许同时考虑精度和召回率。最常见的 beta 值是1, 因为这是精度和召回率的调和平均
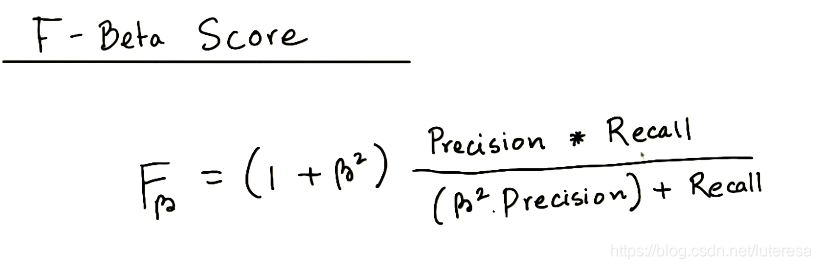
ROC 曲线 和 AUC
通过为我们的分类指标设置不同的阈值,我们可以测量曲线下的面积(曲线称为 ROC 曲线)。与上面的其他指标类似,当 AUC 比较高(接近1)时,这表明我们的模型比指标接近 0 时要好。
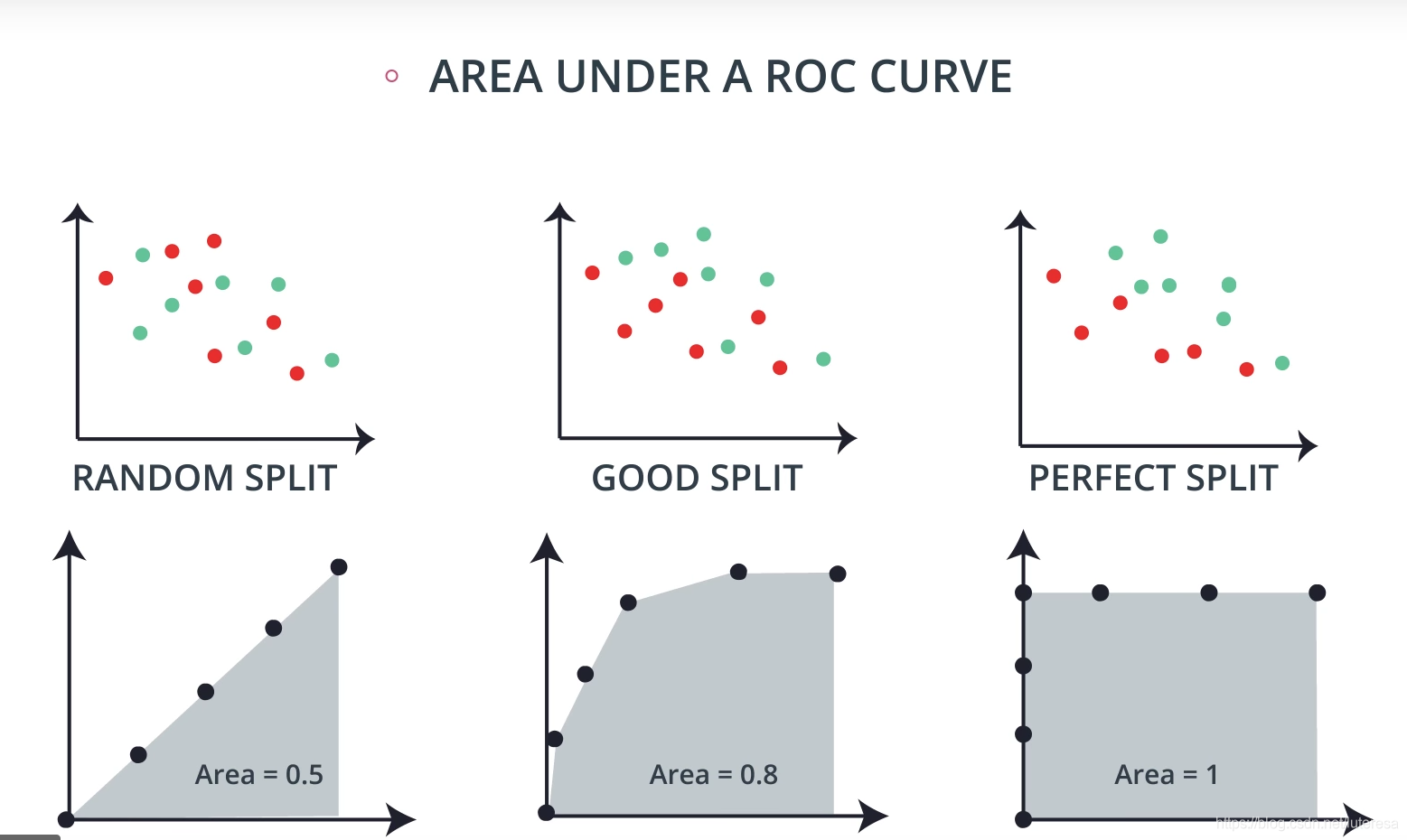
你可能最终会选择基于这些指标中的任何一项进行优化。在实践,我通常中使用 AUC 或 F1 分数。然而,要根据你的具体情况来选择评估方法。
评估回归
你想评估你的模型在预测数值时的性能吗?这种情况下,有三个常用的主要指标:平均绝对误差,均方误差,和 r2 值。
一个重要的注意事项:与优化均方误差相比,优化平均绝对误差可能会导致不同的“最优模型”。然而,与优化 R2 值相同,优化均方误差将总是导致相同的“最优”模型。
同样,如果你选择具有最佳 R2 分数(最高)的模型,它也将是具有最低均方误差(MSE)的模型。具体选择哪个,要根据你觉的在给别人解释时,哪个最方便。
平均绝对误差 (MAE)
你看到的第一个指标是平均绝对误差。当你要预测的数据遵循偏斜分布时,这是一个很有用的指标。在这些情况下,对绝对值做优化特别有用,因为与使用均方误差一样,异常值不会对试图优化这个指标的模型有影响。这个技术的最佳值是中位值。当优化均方误差的 R2 分数时,最佳值实际上是平均数。

均方误差 (MSE)
均方误差是回归问题中最常用的优化指标。与 MAE 类似,你希望找到一个最小化此值的模型。这个指标可能会受到偏斜分布和异常值的极大影响。当一个模型考虑用 MAE 而不是 MSE 做优化时,记住这一点很有用。在很多情况下,在 MSE 上进行优化更容易,因为二次项可微。而绝对值是不可微的。这一因素使得该指标 (MSE) 更适合用于基于梯度的优化算法。

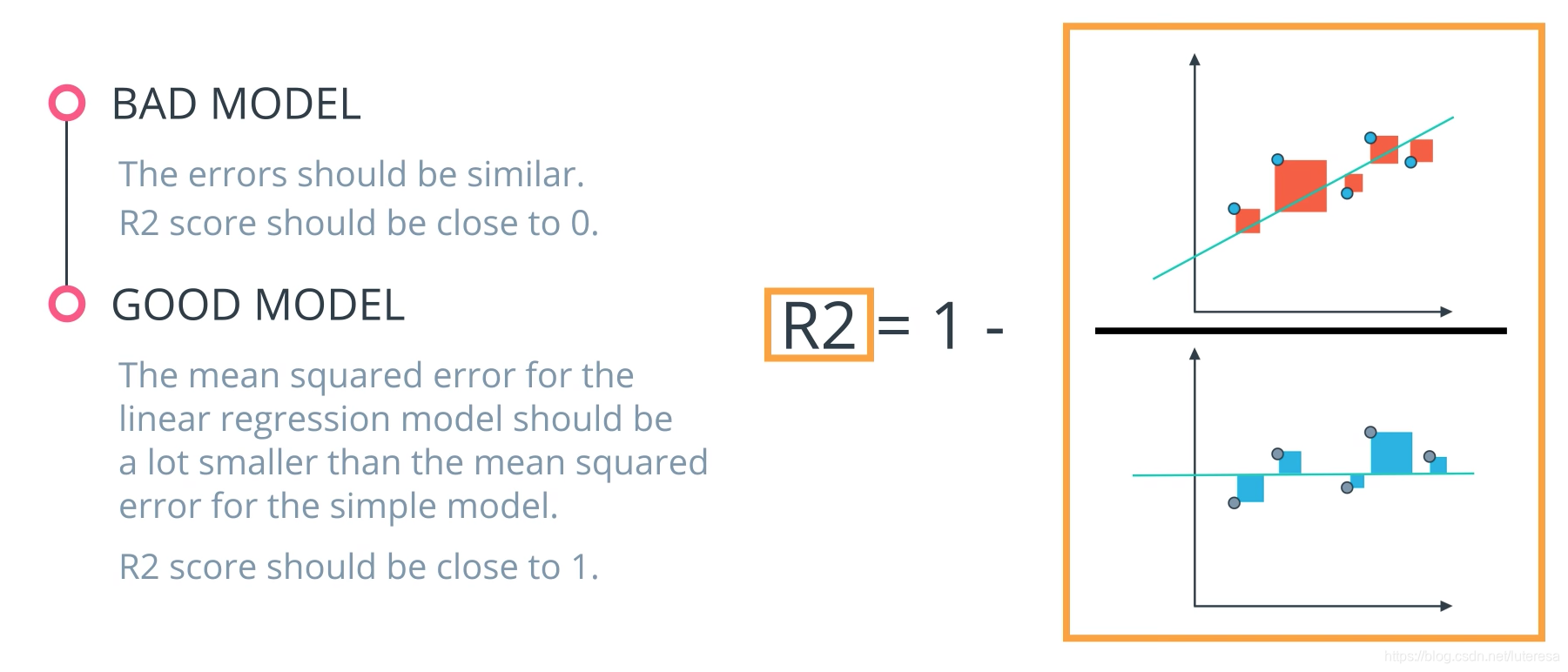
R2 分数
最后,在查看回归值时,R2 分数是另一个常用指标。优化一个模型,最小化 MSE 也将导致最高的 R2 分数。这是这个指标的一个方便特性。R2 分数通常被解释为模型捕获的“变化量”。因此,你可以把 MSE 看作是所有点的平均值,而把 R2 分数看作是用模型捕获的所有点的变化量。
当模型很好时,R2分数接近1;
当模型很差时,R2分数接近0;
from sklearn.metrics import r2_score
y_true = [ 1, 2, 4]
y_pred = [ 1.3, 2.5, 3.7]
r2_score(y_true, y_pred)
看待机器学习问题,类似与解决机器故障,需要一系列检修工具,也需要一系列评估工具,经过评估选择最适合的工具,修好故障车;
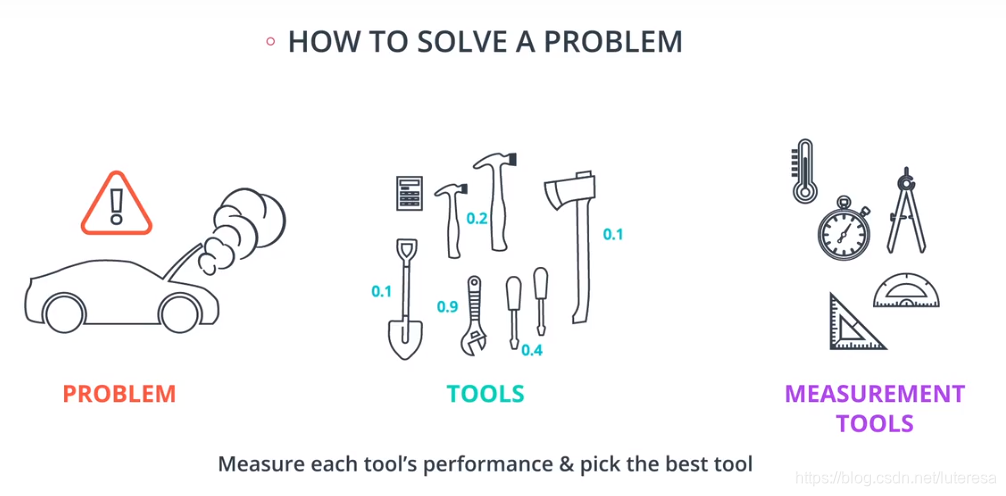
对应到机器学习问题,检修工具是各类算法比如逻辑回归,决策树,神经网络,随机森林等,
评估工具对应模型复杂度、准确率、精确率、召回率、F1分数、学习曲线等。
我们要做的是,用这些指标来测试自己设计的模型,根据表现,选择最优的模型来拟合数据;
