线性回归算法的主要优点是它的简单性,线性回归的损失函数是平方损失。一般处理连续性问题,比如预测房价等,在本文中,使用 TensorFlow 训练一个简单线性回归模型。
线性回归模型 y = wx + b:
-
准备好特征和目标值数据集
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import os # 这里自定义100个数据集 n = 100 data_x = np.arange(n) data_y = 2.0 * data_x + np.random.RandomState(0).randint(-20, 20, size=(n,)) data = np.stack([data_x, data_y], axis=1)实际上,一般都是收集好数据集配置成表文件,然后处理,但是我这里就随机准备好100个数据集data_x, data_y 特征
-
np.random.RandomState(0): 伪随机数生成器
-
randint(-20,20,size=(n,): 生成 -20 到 20 之间,n 个数。
-
-
创建变量 w 和 b
# 创建变量w 和 b w = tf.Variable(0.0, name="weights") b = tf.Variable(0.0, name="bias")这里的w 、b 先创建张量变量为浮点数 0.0 ,但是并没有初始化,后面的运行中,才初始化
-
X 和 Y 占位符
def inputs(): X = tf.placeholder(tf.float32, name="X") Y = tf.placeholder(tf.float32, name="Y") return X,Y注意:在这里X、Y并没有赋值, tf.placeholder : 为张量插入占位符,这个张量总是被赋值的
-
推论,创建预测
def inference(X): return X * w + b线性: y = wx + b
-
计算损失
def loss(X, Y): ''' 通过比较预测值和实际标签来计算损失。 参数 X: 输入值 参数 Y: 标签 返回值 : 返回损失 ''' # 做出预测 Y_predicted = inference(X) return tf.reduce_sum(tf.squared_difference(Y, Y_predicted))/(2*data.shape[0])其中,这里的含义:
-
reduce_sum: 计算一个张量各维度元素的和
-
suqared_difference: 返回(Y - Y_predicted) * (Y - Y_predicted) 的平方差
-
data.shape[0] : 数据集张量的形状,即多少个样本。
-
-
梯度下降去优化损失过程,指定学习率
# 训练 def train(loss): learning_rate = 0.0001 return tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
- learning_rate: 学习率
- minimize(loss): 最小优化损失。
- return : 最小梯度下降op
-
运行测试模型
with tf.Session() as sess: # 初始化变量w 和 b. sess.run(tf.global_variables_initializer()) # 得到 X,Y X, Y = inputs() # 返回训练损失和训练最小梯度下降op. train_loss = loss(X, Y) train_op = train(train_loss) # 打印出训练步数和损失,100步 for epoch_num in range(100): loss_value, _ = sess.run([train_loss,train_op], feed_dict={X: data[:,0], Y: data[:,1]}) # 打印出训练步数和损失 print('epoch %d, loss=%f' %(epoch_num+1, loss_value)) # 保存 w 和 b 的值 wcoeff, bias = sess.run([w, b])运行测试结果,可以从测试结果看出损失是越来越低的。 测试结果:
步数 1, 损失:6564.060059 步数 2, 损失:3004.490479 步数 3, 损失:1399.077148 步数 4, 损失:675.013550 步数 5, 损失:348.451233 步数 6, 损失:201.167343 步数 7, 损失:134.740158 步数 8, 损失:104.780640 步数 9, 损失:91.268486 步数 10, 损失:85.174332 步数 11, 损失:82.425758 步数 12, 损失:81.186127 步数 13, 损失:80.627007 步数 14, 损失:80.374840 步数 15, 损失:80.261086 步数 16, 损失:80.209785 步数 17, 损失:80.186630 步数 18, 损失:80.176178 步数 19, 损失:80.171463 步数 20, 损失:80.169312 步数 21, 损失:80.168335 步数 22, 损失:80.167892 步数 23, 损失:80.167671 步数 24, 损失:80.167580 步数 25, 损失:80.167511 步数 26, 损失:80.167473 步数 27, 损失:80.167450 步数 28, 损失:80.167442 步数 29, 损失:80.167412 步数 30, 损失:80.167397 步数 31, 损失:80.167374 步数 32, 损失:80.167366 步数 33, 损失:80.167336 步数 34, 损失:80.167336 步数 35, 损失:80.167313 步数 36, 损失:80.167290 步数 37, 损失:80.167274 步数 38, 损失:80.167252 步数 39, 损失:80.167236 步数 40, 损失:80.167221 步数 41, 损失:80.167198 步数 42, 损失:80.167183 步数 43, 损失:80.167175 步数 44, 损失:80.167152 步数 45, 损失:80.167130 步数 46, 损失:80.167130 步数 47, 损失:80.167107 步数 48, 损失:80.167084 步数 49, 损失:80.167061 步数 50, 损失:80.167046 步数 51, 损失:80.167030 步数 52, 损失:80.167007 步数 53, 损失:80.166985 步数 54, 损失:80.166977 步数 55, 损失:80.166962 步数 56, 损失:80.166939 步数 57, 损失:80.166916 步数 58, 损失:80.166916 步数 59, 损失:80.166893 步数 60, 损失:80.166870 步数 61, 损失:80.166847 步数 62, 损失:80.166832 步数 63, 损失:80.166817 步数 64, 损失:80.166801 步数 65, 损失:80.166779 步数 66, 损失:80.166763 步数 67, 损失:80.166748 步数 68, 损失:80.166725 步数 69, 损失:80.166710 步数 70, 损失:80.166687 步数 71, 损失:80.166672 步数 72, 损失:80.166649 步数 73, 损失:80.166641 步数 74, 损失:80.166618 步数 75, 损失:80.166611 步数 76, 损失:80.166573 步数 77, 损失:80.166573 步数 78, 损失:80.166550 步数 79, 损失:80.166534 步数 80, 损失:80.166512 步数 81, 损失:80.166512 步数 82, 损失:80.166489 步数 83, 损失:80.166473 步数 84, 损失:80.166451 步数 85, 损失:80.166435 步数 86, 损失:80.166412 步数 87, 损失:80.166405 步数 88, 损失:80.166374 步数 89, 损失:80.166374 步数 90, 损失:80.166344 步数 91, 损失:80.166328 步数 92, 损失:80.166313 步数 93, 损失:80.166298 步数 94, 损失:80.166290 步数 95, 损失:80.166260 步数 96, 损失:80.166237 步数 97, 损失:80.166229 步数 98, 损失:80.166206 步数 99, 损失:80.166191 步数 100, 损失:80.166176 -
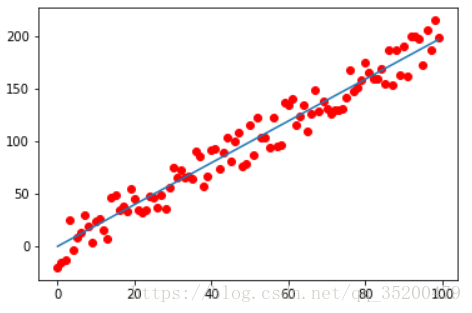
最后可以画出模型,形象地描述
Input_values = data[:,0] Labels = data[:,1] Prediction_values = data[:,0] * wcoeff + bias plt.plot(Input_values, Labels, 'ro', label='main') plt.plot(Input_values, Prediction_values, label='Predicted') plt.show()如下图:
-