回归问题可以分为两种情况,一是我们可以列出一个表达式,输入和输出通过这个表达式建立对应关系,那么我们求出表达式里面的参数即可;二是我们可能无法列出表达式,这时我们可以使用神经网络代替这个表达式,输入和输出通过神经网络建立对应关系,那么我们求出神经网络里面的权重和偏置即可。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 原始数据
# x_data.shape=[200,1]
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
# 定义两个placeholder,行数待定,列数为1
x=tf.placeholder(tf.float32,[None,1])
y=tf.placeholder(tf.float32,[None,1])
# 设计全连接神经网络中间层
weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10]))
out_L1=tf.matmul(x,weights_L1)+biases_L1
L1=tf.nn.tanh(out_L1)
# 设计全连接神经网络输出层
weights_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1]))
out_L2=tf.matmul(L1,weights_L2)+biases_L2
prediction=tf.nn.tanh(out_L2)
# 定义损失函数
loss=tf.reduce_mean(tf.square(prediction-y))
# 定义优化器
optimizer=tf.train.GradientDescentOptimizer(0.1)
# 定义模型,优化器通过调整loss函数里的参数使loss不断减小
train=optimizer.minimize(loss)
# 在图里运行
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1000):
sess.run(train,feed_dict={
x:x_data,y:y_data})
if step%50==0:
print(sess.run(loss,feed_dict={
x:x_data,y:y_data}))
# 获取预测值
prediction_value=sess.run(prediction,feed_dict={
x:x_data})
# 绘图
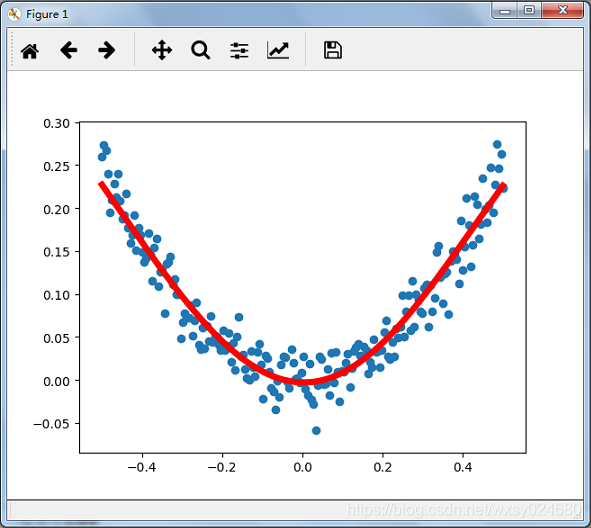
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
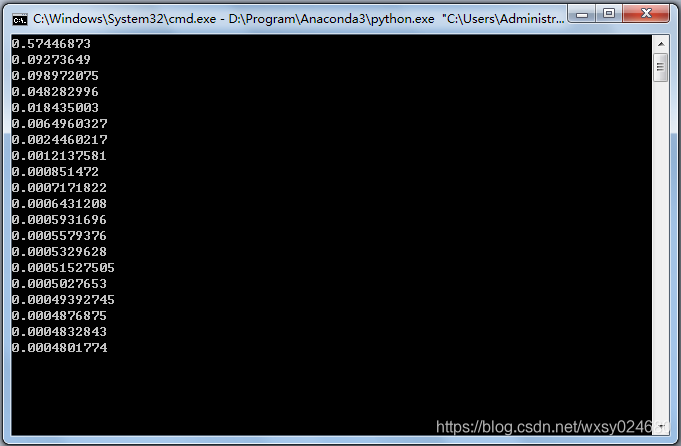
运行结果: