差分隐私综述_李效光
面向数据发布和分析的差分隐私保护 张啸剑
差分隐私保护及其应用 熊平
提出
隐私保护整体分成9个部分,包括隐私信息产生、隐私感知、隐私保护、隐私发布、私信息存储, 隐私交换, 隐私分析, 隐私销毁, 隐私接收者。主要研究方向在在隐私保护, 隐私发布/存储/交换, 隐私分析这 3 个部分。
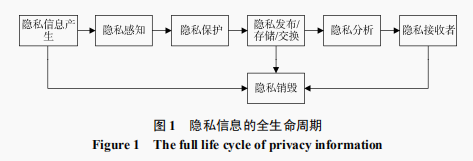
隐私保护的方式分成以下三种包括,数据失真,加密,以及访问控制。目前的很多隐私保护技术往往结合了其中的多种技术。我们熟知的就是k-匿名算法、l-匿名算法、t-匿名算法等等。
但这些匿名算法有两个重要的缺陷,其一是这些模型并不能提供足够的安全保障,它们总是因新型攻击的出现而需要不断完善。例如为了抵制“一致性”攻击,l-匿名算法,t-匿名被相继提出,m-confidentiality模型被用以抵制“最小性”攻击,如今更多种类型的攻击方法对基于分组的隐私包补模型形成挑战,原因在于基于分组的隐私保护模型的安全性与攻击者所掌握的背景知识相关,而所有可能的背景知识很难被充分定义。所以,一个与背景知识无关的隐私保护模型才可能抵抗任何新型的攻击。其二,这些早期的隐私保护模型无法提供一种有效且严格的方法来证明其隐私保护水平,因此当模型参数改变时,无法对隐私保护水平进行定量分析。因此研究人员试图找到一种能够足够好的隐私保护模型,并能够衡量隐私标准的数据保护方法。
进而提出了差分隐私。首先,差分隐私保护模型假设攻击者能够获得除目标记录外所有其它记录的信息,这些信息的总和可以理解为攻击者所能掌握的最大背景知识。在这一最大背景知识假设下,差分隐私保护无需考虑攻击者所拥有的任何可能的背景知识,因为这些背景知识不可能提供比最大背景知识更丰富的信息。其次,它建立在坚实的数学基础之上,对隐私保护进行了严格的定义并提供了量化评估方法,使得不同参数处理下的数据集所提供的隐私保护水平具有可比较性。
基本思想与期望效果
用户项数据提供者提交查询请求是,差分隐私系统从数据库中提炼出一个中间件,利用一个特别设计的随机算法对中间件注入适量的噪声,再通过带噪的中间件推导出带噪的查询结果。返回给用户的就是这个带有噪声的查询结果。攻击者能从带噪的结果推回到带噪的中间件,但不能准确的推断出无噪中间件,也不能对数据库进行推理,从而达到隐私的目的。
基本定义
:隐私保护预算,用户衡量隐私保护程度。当参数 越小时, 作用在一对相邻数据集上的差分隐私算法返回的查询结果的概率分布越相似, 攻击者就越难以区分这一对相邻数据集, 保护程度就越高。当 时, 攻击者无法区分这一对相邻数据集保护程度最高。
敏感度:指删除数据集中任一记录对查询结果照成的改变,是决定加入噪声量大小的关键。分成全局敏感度和局部敏感度。
定义1 对于一个随机算法 , 为算法 可以输出的所有组织的集合,如果对于任意一对相邻的数据集 和 , 的任意自己 算法满足 则称算法 满足 -差分隐私。
图1给出算法 M 通过对输出结果的随机化来提供隐私保护,同时通过参数
来保证在 数据集中删除任一记录时,算法输出同一结果的概率不发生显著变化.
定义2 全局敏感度:对于一个查询函数
,其中
为一个数据集,
为d维实数向量,是查询函数的返回结果。在任意一对相邻数据集
和
上他的全局敏感度定义为
其中,
是
与
之间的曼哈顿距离。
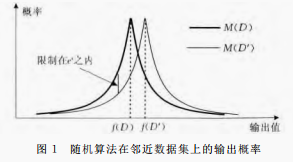
全局敏感度反应了一个查询函数在一对相邻数据集上查询时变化的最大范围。他与数据集无关。只有查询函数本身决定。一些函数的全局敏感度较小,那只需要加入较小量的噪声,以掩盖因一个记录删除对查询结果所产生的影响,实现差分隐私保护。若函数具有较大的全局敏感度(如平均值),必须在函数输出时添加足够大的噪声才能保证隐私安全。
定义3 局部敏感度:对于一个查询函数 ,其中 为一个数据集, 为d维实数向量,是查询函数的返回结果。对于给定的数据集 和他的任意邻近数据集 ,有 在 上的局部敏感函数为
局部敏感度由函数 集合给定的数据集 中的具体数据共同决定,通常比全局敏感度小很多,全局敏感度和局部敏感度的关系为 但局部敏感度在一定程度上会体现数据集的数据分布特征.
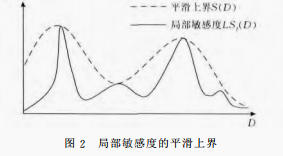
定义4 平滑上界:给定数据集 和其任意临近数据集 ,函数 的局部敏感度为 。对于 ,若函数 满足 且 ,则称 为函数 的局部敏感度的 -平滑上界。
所有满足这一定义的函数都可能被定义为平滑上界,将局部敏感度带入函数中可以得到平滑敏感度,进而计算噪声大小。
定义5 平滑敏感度:给定数据集 和 函数 称为函数 的 -平滑敏感度,其中 。
图2给出一个平滑上界的例子。
性质
性质1:顺序合成:对于任意 个算法,分别满足 -差分隐私, -差分隐私,…, -差分隐私,将他们作用于同于数据集上时,数据集上的差分隐私为他们的和。说明了当有一个算法序列同时作用在一个数据集上时, 最终的当有多个算法序列分别作用在一个数据集上多个不同子集上时, 最终的差分隐私预算等价于算法序列中所有算法预算的最大值。于算法序列中所有算法的预算的和。
性质2:平行合成:把一个数据集 分成k个集合,分别为 ,令 是 个分别满足的 差分隐私算法, 的结果满足max -差分隐私。
说明了如果一个差分隐私保护算法序列中所有算法处理的数据集彼此不相交,那么该算法序列构成的组合算法提供的隐私保护水平取决于算法序列中的保护水平最差者,即预算最大者。
性质3:变换不变性:给定任意一个算法
满足
-差分隐私。对于任意算法
(
不一定满足差分隐私的算法),则有
满足
-差分隐私。

说明了差分隐私对于后处理算法具有免疫性, 如果一个算法的结果满足 -差分隐私, 那么在这个结果上进行的任何处理都不会对隐私保护有所影响。
性质4:中凸性:给定2个算法 和 满足 -差分隐私。对于任意的概率 ,用符号 表示为一种机制,它以 的概率使用 算法,以 的概率使用 算法则 机制满足 -差分隐私。
说明了如果有2 个不同的差分隐私算法, 都提供了足够的不确定性来保护隐私, 那么可以通过选择任意的算法来应用到数据上实现对数据的隐私保护, 只要选择的算法和数据是独立的。
应用
实现机制
差分隐私针对不同的算法有不同的实现机制,两种最常用的为Laplace机制和指数机制。Laplace机制常用于数值型结果的保护,指数机制则适用于非数值型结果。
Laplace机制
定义6 给定数据集
,设有函数
,其敏感度为
,那么随机算法
提供
-差分隐私保护,其中
为随机噪声,服从尺度函数为
的Laplace分布。
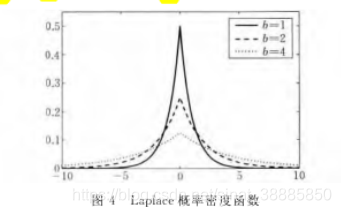
由下图可观察到,不同参数的Laplace分布均有
越小,引入的噪声越大。
指数机制
设查询函数的输出域为Range,域中的每个值
为一实体对象,在指数机制下,函数
成为输出值
的可用性函数,用来评估输出值
的优劣程度。
定义7 设随机算法
输入为数据集
,输出为一实体对象
,
为可用性函数,
为函数
的敏感度,若算法
一正比于
的概率从Range中选择并输出
,那么算法
提供
-差分隐私保护。