联邦学习(FL)+差分隐私(DP)
文章首发在我的博客!在这里在这里在这里在这里在这里!!!!!!
防止梯度信息被泄露的方法有很多,目前主要有两种:
1.基于安全多方计算的
这个里面包含的方法很多,包括对梯度进行安全聚合算法进行聚合,或者进行同态加密运算,等等,文章以及方法很多。
2.基于差分隐私的
差分隐私能被用于抵抗成员推理攻击。这个里面主要就是对梯度信息添加噪音,添加的噪音种类可能不同,但是目前主要就是拉普拉斯噪声和高斯噪声这两种。
基于差分隐私的联邦学习主要是对梯度信息添加噪声,不会有很高的通信或者计算代价,但是由于我们对于梯度进行进行了加噪,所以会影响模型收敛的速度,可能会需要更多的round才能达到我们想要的精度。
差分隐私能抵御成员推理攻击
Differential Privacy for Deep and Federated Learning: A Survey【IEEE ACCESS 2022】
本文贡献:
1.给数据集加噪的隐私保护技术,如k-匿名性、l-多样性和t-贴近度
2.训练前给数据集加噪,训练时给梯度加噪,部署训练完成的模型给模型加噪。
数据集隐私保护技术
k−anonymity(k-匿名)、l−diversity(l-多样性)和t−closeness(t-贴近)
训练过程中的隐私保护技术
1)Secure multi party computing (SMC)安全多方计算
是密码学的一个子领域,它允许创建方法来使用来自不同方的输入联合计算函数,而无需向彼此也不向中央服务器显示这些输入。不需要可信第三方。SMC在计算复杂性和通信开销方面代价高昂。因此,SMC不适合在涉及许多客户的大数据集上训练复杂模型。
2)同态加密
允许在加密数据集上训练模型。他获得了与在数据集的未加密版本(即原始数据集)上执行培训相同的准确性。然而,由于其计算复杂性,在DL中使用HE在实践中效率很低,尤其是当训练数据集太大而无法放入计算机内存时,
差分隐私DP
虽然DP的第一个定义是在2006年,但仅在最近几年才在实际使用中得到重视。
1. Central differential privacy (CDP)中央差分隐私
用户向数据库管理者发送原始数据,信任数据库管理员,将随机噪声添加到原始数据集或原始数据集上启动的查询的结果中。数据管理员在响应第三方的统计查询进行分析之前,使用DP扰动原始数据集。
2. Local differential privacy (LDP) 本地差分隐私
不需要可信第三方,在向服务器发送梯度之前添加噪声。
H. Ren, J. Deng, and X. Xie, ‘‘GRNN: Generative regression neural network—A data leakage attack for federated learning,’’ CoRR, New York, NY, USA, Tech. Rep. 2105.00529, 2021.
上文成功的在当向梯度添加较小噪声时恢复了原始数据集
[41] T. Ha, T. K. Dang, T. T. Dang, T. A. Truong, and M. T. Nguyen, ‘‘Differential privacy in deep learning: An overview,’’ in Proc. Int. Conf. Adv. Comput. Appl. (ACOMP), Nov. 2019, pp. 97–102.
1)梯度级方法,包括向梯度添加噪声;2)函数级方法,包括向损失函数添加噪声;3)标签级方法,包括在训练期间向标签集添加噪声。
[42] A. Boulemtafes, A. Derhab, and Y. Challal, ‘‘A review of privacy preserving techniques for deep learning,’’ Neurocomputing, vol. 384, pp. 21–45, Apr. 2020
差分隐私及变体
1. ϵ \epsilon ϵ-DP,拉普拉斯噪声
DP包括向统计查询或原始数据集添加噪声,以便对手无法知道特定个人是否包含在数据集中。
ϵ \epsilon ϵ代表了隐私损失,
敏感度:
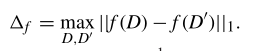
ϵ \epsilon ϵ-DP:
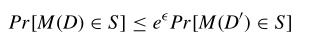
将隐私保护机制M应用于D和将M应用于D’时的输出相似, ϵ \epsilon ϵ越小,相似程度越高。
值得一提的是,两种DP机制联合可以累加,可以应用于联邦学习: M 1 M_1 M1是 ϵ 1 \epsilon_1 ϵ1-DP, M 2 M_2 M2是 ϵ 2 \epsilon_2 ϵ2-DP,则 M 1 , 2 M_{1,2} M1,2是 ( ϵ 1 + ϵ 2 ) (\epsilon_1+\epsilon_2) (ϵ1+ϵ2)-DP
对于联邦学习,如果一个客户端在把梯度发给服务器之前,将自己的梯度添加了一个 ϵ \epsilon ϵ-DP机制,在k-epochs之后,变为了 ( k ∗ ϵ ) (k*\epsilon) (k∗ϵ)-DP。
2. ( ϵ , δ ) (\epsilon,\delta) (ϵ,δ)-DP,高斯噪声
添加 δ \delta δ是为了实现高斯噪声的差分隐私
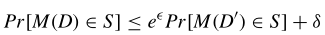
两种噪声比较:
与高斯分布相比,拉普拉斯分布保证了强大的隐私保护,但以牺牲准确性为代价。
高斯分布比拉普拉斯分布具有更高的精度;这种差异随着 ϵ \epsilon ϵ的减小而增大。
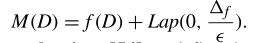
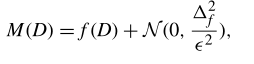

几何机制是拉普拉斯机制的离散化版本
适合随机应答机制
DP机制最具挑战性的问题是,在FL中,由于噪声叠加, ϵ \epsilon ϵ增加(见定理1)。随着训练轮数的增加,隐私泄漏会增加。隐私泄漏会随着k(epochs)的增加而增加。C. Dwork, G. N. Rothblum, and S. Vadhan, ‘‘Boosting and differential privacy,’’ in Proc. IEEE 51st Annu. Symp. Found. Comput. Sci., Oct. 2010, pp. 51–60提出了一种bound住K次叠加后的隐私预算 ϵ \epsilon ϵ。
提出了RDP,定义了一个更加严格的隐私预算界限,可以在K轮迭代后bound住 ϵ \epsilon ϵ
RDP基于Rényi散度,f-DP基于假设检验(通过权衡函数f参数化)
关于几种差分隐私变体的比较,参考[65] S. Asoodeh, J. Liao, F. P. Calmon, O. Kosut, and L. Sankar, ‘‘Three variants of differential privacy: Lossless conversion and applications,’’ IEEE J. Sel. Areas Inf. Theory, vol. 2, no. 1, pp. 208–222, Mar. 2021.
中心差分隐私CDP
相信服务器。将原始梯度发给服务器,服务器加噪
本地差分隐私LDP
- DP+同态加密HE/安全多方计算
- 基于DP+FL的用户隐私保护
- DP+FL减少通信资源消耗
Google,Microsoft,Apple将随机应答RR差分隐私技术实际应用到了产品中
Apple:
Differential Privacy Team. (Dec. 2017). Learning With Privacy at Scale. [Online]. Available: https://machinelearning.apple.com/research/ learning-with-privacy-at-scale
Microsoft:
X. Ding, C. Wang, K.-K. Raymond Choo, and H. Jin, ‘‘A novel privacy preserving framework for large scale graph data publishing,’’ IEEE Trans. Knowl. Data Eng., vol. 33, no. 2, pp. 331–343, Feb. 2021
Google:
Ú. Erlingsson, V. Pihur, and A. Korolova, ‘‘RAPPOR: Randomized aggregatable privacy-preserving ordinal response,’’ in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., Nov. 2014, pp. 1054–1067, doi: 10.1145/2660267.2660348.
RR(Randomized Response 随机应答:
RR技术包括以一定的概率翻转用户的真实答案,然后再将其发送给数据管理器。例如,一位社会科学家希望在保持隐私的同时,从吸毒者那里收集有关吸毒成瘾的统计数据;在回答问题之前,用户投掷一枚硬币:1)如果硬币正面朝上,则他/她会如实回答,否则2)用户投掷另一枚硬币,如果硬币正面朝上,则用户会如实回答,否则,用户会翻转他/她的回答。

FL + RR + computation/communication cost
可以研究的问题:
- FL + Laplace/Gauss/RR + communication/computation
- 最有可能部署到实际应用的是跨设备联邦学习,移动端手机,由于手机的算力和存储空间有限,必须要考虑本地CPU计算的资源消耗和无线通信消耗。
- 多轮迭代后,隐私预算呈倍数增长,需要差分隐私变体bound住隐私预算,看已经复现的FL+DP代码,因为无法bound住 ϵ \epsilon ϵ,在本地只进行了一轮迭代?
- 差分隐私因为对梯度加了噪声,影响全局模型收敛
- LDP、CDP
- 和GAN结合,目前找到一篇文章提出了用FL+DP来训练GAN: PRIVATE FL-GAN: DIFFERENTIAL PRIVACY SYNTHETIC DATA GENERATION BASED ON FEDERATED LEARNING【2020 IEEE INTERNATIONAL CONFERENCE 】
Federated Learning With Differential Privacy: Algorithms and Performance Analysis【IEEE 2020】
本文贡献:
1.在安全聚合前给模型参数添加高斯噪声
2.对训练好的FL模型的损失函数给出了一个收敛界:
1)更好的收敛性能导致更低的保护水平
2)给定固定隐私保护级别的情况下,增加参与FL的总客户端数N可以提高收敛性能
3)对于给定的保护级别,就收敛性能而言,存在一个最佳的最大聚合次数
3.提出了一种K客户机随机调度策略,从N个总体客户端中随机选择K个参与每轮聚合。得到了损失函数的收敛界。存在一个最佳K值,该值在固定的隐私级别下达到了最佳的收敛性能。