目录
前言
数据是人工智能学习的基础,一个表现优异的机器学习或深度学习模型离不开大量的训练数据。然而,这些训练数据的来源是否合规?数据是否会泄露个人隐私?这是一个值得重视的问题。近年来我国数据立法进程不断加快,尤其强调数据应用过程中的数据安全。《中华人民共和国网络安全法》《中华人民共和国数据安全法》和《中华人民共和国个人信息保护法(草案)》逐步完善了国家数据相关立法的顶层设计,着重强调了流通过程中的数据安全和个人信息保护。因此,我们有必要研究隐私保护技术,实现对数据隐私的保护,同时仍然可以使数据的价值得到利用。
一、差分隐私
差分隐私(Differential Privacy,DP)技术是Dwork在2006年针对数据库的隐私泄露问题提出的一种新型密码学手段。该机制是在源数据或计算结果上添加特定分布的噪音,确保各参与方无法通 过得到的数据分析出数据集中是否包含某一特定实体。差分隐私包括本地差分隐私和计算结果差分隐私。本地差分隐私指在汇聚和计算前数据就加入噪声,用于数据收集方不可信的场景;计算结果差分隐私是指最终计算结果发布前对其加噪声。
也就是说,差分隐私旨在提供一种当从统计数据库查询时,对数据整体的有用信息(诸如均值、中位数)查询准确性最大化,同时最大限度减少识别其记录的机会(能够保护群体中某一个具体客户的信息)。即使数据被用于正常研究或分析的同时,尽可能降低数据泄露的风险。在最好的情况下,不同的差分隐私算法可以使被保护数据广泛用于准确的数据分析,而无需借助于其他数据保护机制。尽管如此,数据的有效性最终还是会被消耗掉:信息恢复基本定律指出,对太多问题过于准确的答案将以一种惊人的方式破坏数据隐私。差分隐私算法研究的目标就是尽可能地避免这种对数据隐私的破坏。
例如:“吸烟会致癌”是一件众所周知的事情,这个结论是如何得到的呢?当然得经过大量的数据统计,发现吸烟人群的患癌率高于不吸烟人群的患癌率,从而得出“吸烟致癌”的结论。那么“吸烟致癌”这个结论暴露了吸烟人群的隐私吗?答案是否。对于某个群体的属性,通常是不被看作隐私的。但是如果群体中的具体对象的吸烟记录被泄露,例如从数据库中可以查到某一个人的吸烟记录,然后得出他具有一定患癌风险的结论,这是个人隐私的泄露。因此有必要对个人数据进行加密,保护个人隐私。
对某个数据库中的每一行记录进行加密之后,是否能够完全有效地保护个人隐私呢?答案是否。就算已经将个人数据进行了加密,但对群体数据的分析往往也会泄露个人隐私。例如,如果我们预先知道,张三的信息包含在某个数据库中,且存有他是否吸烟的记录。虽然他的信息被加密了,无法直接查询,但还是可以利用差分攻击的方法得到其信息。比如,我们可以查询:总共有多少人吸烟,以及查询有多少个不叫张三的人吸烟。如果人数相等,那么可以得出张三不吸烟的结论。相反,如果人数不相等,那么张三吸烟(假定数据库中只有一个叫张三的人)。这样经过差分,我们就可以得到某一个具体对象的隐私信息。
除此之外,结合外部信息也可以实现对加密数据中个人隐私信息的获取。例如,2006年10月,Netflix提出一笔100万美元的奖金,作为将其推荐系统改进达10%的奖励。Netflix还发布了一个训练数据集供竞选开发者训练其系统。在发布此数据集时,Netflix提供了免责声明:为保护客户的隐私,可识别单个客户的所有个人信息已被删除,并且所有客户ID已用随机分配的ID替代。然而Netflix不是网络上唯一的电影评级门户网站,其他网站还有很多,包括IMDb网站。所以说,某个人也可以在IMDb上注册和评价电影,并且可以选择匿名化自己的详情。德克萨斯州大学奥斯汀分校的研究员Arvind Narayanan和Vitaly Shmatikov将Netflix匿名化的训练数据库与IMDb数据库(根据用户评价日期)相连,能够部分反匿名化Netflix的训练数据库,从而得到部分用户的身份信息。
那么,差分隐私技术是如何对原始数据库进行个人信息的隐私保护呢?Dwork提出,要满足个体隐私保护的要求,必须要引入随机性。因为如果对数据库的每一次查询都是精确的,那么数据分析者可以通过差分查询,知道未知行中的数据信息。
假设我们需要对某个群体进行是否患有艾滋病的调查,如果让每一个受访者如实回答,必然会导致个人隐私信息的泄露。但是我们只想获取这个群体的统计信息,如整个群体的患病率、患病人数。因此我们可以在调查受访者时引入随机算法:令受访者自己抛一枚硬币,若正面朝上,则如实回答是否患有艾滋病;若背面朝上,则再抛一枚硬币,不管他是否患病,只要硬币正面朝上则都回答患有艾滋病,背面朝上则都回答不患病。如此一来,即使整个群体所有人都不患病,调查结果也会统计得到有1/4的人回答患有艾滋病,因此真正患病的个体就可以畅所欲言。而即使你通过攻击数据库得知某个对象患有艾滋病的记录,但你也无法判断他说的是真话还是遵循了抛硬币的规则。
而对于调查者而言,真实的患病概率可以通过简单的计算得到:
其中,表示调查得到患病率,
表示真实的患病率,
表示回答患有艾滋病的总人数,
表示接受调查的总人数。
可以看出,差分隐私就是通过引入噪声扰动达到保护数据隐私的目的。差分隐私要求对于任何查询,其输出都是概率的。在给出差分隐私的精确定义前,我们需要对随机算法进行一些定义。
定义1:(概率单纯形,probability simplex)给定一个数目有限的离散集,我们可以将
看作是有限数量的互斥事件,定义
上的概率单纯形为
,满足:
概率单纯形即事件集上所有可能的概率分布的集合,而每一个元素
就是一种可能的概率分布。基于概率单纯形,我们可以对随机算法进行如下的形式化定义:
定义2:(随机算法,randomized algorithm) 记数据库中所有条目的集合为,则所有可能的子数据库构成的空间为
。随机算法
将一个子数据库
映射到离散集合
的概率单纯形的一个可能分布上,即:
我们也称为随机算法
的值域。其中对于每一个可能作为算法输入的数据库
,随机算法
先将其映射到一个概率分布,即对于任意
,以及任意的
,随机算法
以
的概率输出结果为
。
有了随机算法,我们还需要定义数据库之间的距离。一般用表示数据库之间的距离。对于两个数据库
,我们定义它们的
距离
为两个数据库中不同的记录的个数。如果
,说明这两个数据集只相差一条记录,我们就称
、
为相邻数据集(Neighboring Datasets)。而差分隐私可以直观理解为,对于两个相似的数据库,要求随机算法
在这两个数据库上的表现也相似,它的形式化定义如下:
定义3:(差分隐私,Differentially Private,DP)我们称上的随机算法
满足
,如果对于所有的随机事件
,以及对于所有的相邻数据库
,满足:
其中,如果,我们就称随机算法
满足
。
是差分隐私定义中用来控制隐私度的一个度量,
越小,则隐私度越高,不过相应的,数据可用性就越低。
为0时,表示对于任意临近数据集,算法都将输出两个概率分布完全相同的结果。
在上面的艾滋病患病比例调查例子中,如果令受访者不管实际如何,只依靠抛硬币来回答,只要硬币正面朝上则都回答患有艾滋病,背面朝上则都回答不患病。那么此时,采集到的数据隐私度达到最高,但是这样的数据也毫无意义。如何维持数据的隐私度和可用性的平衡,是近年来广泛研究的问题。
二、差分隐私在机器学习领域的应用
数据分析中常用的是机器学习模型:通过在大量训练样本上进行学习以预测新样本的某些未知特征。没有数据,机器学习模型就如无米之炊。随着研究的发展,机器学习模型的能力变得越来越强,需要的训练数据也大大增加。比如,业界有些训练模型需要使用上百GB的数据来训练数十亿的参数。而在很多专业领域如医疗、金融防欺诈等,数据则因为隐私或者利益被分割成数据孤岛,使得机器学习面临着有效数据不足的问题。因此,如果不能对数据隐私提供保证,那么信息流动和机器学习也无法实现。而且,隐私保护并不会限制机器学习的性能,因为它们从根本上并不冲突——隐私保护个体信息,机器学习对整体信息进行挖掘。因此,在样本集中引入隐私保护技术对机器学习模型的性能影响较小。
训练后的模型会造成隐私训练数据的泄露吗?可能会的。因为机器学习的模型都会在一定程度上过拟合(泛化鸿沟),模型自身会记住部分训练数据,从而导致发布模型会造成隐私训练数据的泄露。一个典型的例子是模型反向工程(model inversion), 即研究从模型推断训练数据。下图就是攻击者只用姓名和人脸识别系统的黑盒访问恢复出的训练集中的数据。

另一个例子是成员推断(membership inference),它推断某个样本是不是在训练集中,较高的成员推断成功率显示模型对训练数据的隐私泄露。

而差分隐私可以衡量和控制模型对训练数据的隐私泄露,实现算法差分隐私的一种通用做法是添加噪音。它会给每次查询的结果添加少量噪声以掩盖单个数据点的影响,然后跟踪并累积查询的隐私损失,直至达到总体隐私预算,之后便不再允许查询。为保证差分隐私所加入的噪声,可能会影响结果的准确性,但如果查询结果的维数较小,则不会有显著影响。
差分隐私可确保计算结果(如训练好的模型)可以被安全地共享或使用。由于其严格的数学原理,差分隐私被公认为是隐私保护的黄金标准。应用差分隐私能够从数据集中计算出有用的信息,同时还可以保证模型无法从计算结果中重新识别数据集中的任何个体。这为金融服务和医疗保健等领域的组织机构使用人工智能技术带来了更大的信心,因为这些领域的数据都高度敏感,隐私保护格外受关注。
在机器学习过程中实现差分隐私的一种通用做法也是加噪声,即用噪声掩盖单个数据点的影响。机器学习的一般流程为:设计目标函数,然后训练过程一般是基于梯度的优化算法,最后输出训练好的模型。对应地,根据加噪声的时机,差分隐私机器学习(Differential Private Machine Learning) 有三种实现方法——目标扰动(Objective Perturbation),即在目标函数上添加噪声;梯度扰动(Gradient Perturbation, GP),即在梯度上添噪声;输出扰动(Output Perturbation),即在最后输出上添加噪声。不过若添加的噪声很大,会带来模型的性能损失,但太小又不能很好地保护隐私。因此,差分隐私机器学习可以研究如何在给定隐私损失的要求下,添加最少的噪声取得最好的性能。
梯度扰动是一种实现差分隐私机器学习的有效算法,梯度的值由训练样本计算而来,梯度包含了样本集上的信息,对梯度进行扰动就能保证后续更新参数值的操作不会泄露用户信息。差分隐私随机梯度下降法 (DP-SGD) 是深度学习中最流行的 DP 训练方法,通过在训练中注入噪声来实现这种对于信息的保护。
三、DP-SGD在手写数字数据集MNIST上的对比实验
MNIST(Mixed National Institute of Standards and Technology database)是一个非常有名的手写体数字识别数据集(手写数字灰度图像数据集),在很多资料中,这个数据集都会被用作深度学习的入门样例。MNIST数据集是由0到9的数字图像构成的,它包含了60000张图片作为训练数据供研究人员训练出合适的模型,以及10000张图片作为测试数据供研究人员测试训练的模型的性能。由250个不同的人手写而成,每一张图片都有对应的标签数字。

1、不使用差分隐私
#导入包
import torch
from torchvision import datasets, transforms
import numpy as np
from tqdm import tqdm #可视化训练过程进展
import torch.nn.functional as F
#加载数据集,使用数据集的平均值 (0.1307) 和标准偏差 (0.3081) 进行归一化
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=True, download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=64, shuffle=True, num_workers=1, pin_memory=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=False,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=1024, shuffle=True, num_workers=1, pin_memory=True)
#创建 PyTorch 神经网络分类模型和优化器,2层卷积,2层全连接
model = torch.nn.Sequential(torch.nn.Conv2d(1, 16, 8, 2, padding=3), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1),
torch.nn.Conv2d(16, 32, 4, 2), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1), torch.nn.Flatten(),
torch.nn.Linear(32 * 4 * 4, 32), torch.nn.ReLU(), torch.nn.Linear(32, 10))
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
#训练
def train(model, train_loader, optimizer, epoch, device, delta):
model.train()
criterion = torch.nn.CrossEntropyLoss()
losses = []
for _batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
for epoch in range(1, 11):
print('epoch '+str(epoch))
train(model, train_loader, optimizer, epoch, device="cpu", delta=1e-5)
#测试
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to("cpu"), target.to("cpu")
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss
pred = torch.max(output, 1)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\n Test_set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test()
输出结果为:
Test_set: Average loss: -17.4087, Accuracy: 9889/10000 (98.89%)2、使用差分隐私进行梯度扰动
!pip install opacus==0.13.0
# Step 1: Importing PyTorch and Opacus
import torch
from torchvision import datasets, transforms
import numpy as np
from opacus import PrivacyEngine
from tqdm import tqdm
import torch.nn.functional as F
# Step 2: 加载数据集
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=True, download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=64, shuffle=True, num_workers=1, pin_memory=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=False,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=1024, shuffle=True, num_workers=1, pin_memory=True)
# Step 3: 创建 PyTorch 神经网络分类模型和优化器
model = torch.nn.Sequential(torch.nn.Conv2d(1, 16, 8, 2, padding=3), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1),
torch.nn.Conv2d(16, 32, 4, 2), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1), torch.nn.Flatten(),
torch.nn.Linear(32 * 4 * 4, 32), torch.nn.ReLU(), torch.nn.Linear(32, 10))
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
# Step 4: 将差分隐私引擎附加到优化器
privacy_engine = PrivacyEngine(model, batch_size=64, sample_size=60000, alphas=range(2,32),
noise_multiplier=1.3, max_grad_norm=1.0,)
privacy_engine.attach(optimizer)
# Step 5: 训练
def train(model, train_loader, optimizer, epoch, device, delta):
model.train()
criterion = torch.nn.CrossEntropyLoss()
losses = []
for _batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
epsilon, best_alpha = optimizer.privacy_engine.get_privacy_spent(delta)
print(
f"Train Epoch: {epoch} \t"
f"Loss: {np.mean(losses):.6f} "
f"(ε = {epsilon:.2f}, δ = {delta}) for α = {best_alpha}")
for epoch in range(1, 11):
train(model, train_loader, optimizer, epoch, device="cpu", delta=1e-5)
#测试
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to("cpu"), target.to("cpu") # cpu or cuda
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss
pred = torch.max(output, 1)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\n Test_set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test()注意:要先安装opacus库(可以训练引入差分隐私的PyTorch模型)。安装版本为0.13.0,若安装版本太高,程序会报以下错误。
__init__() got an unexpected keyword argument 'batch_size'输出结果:
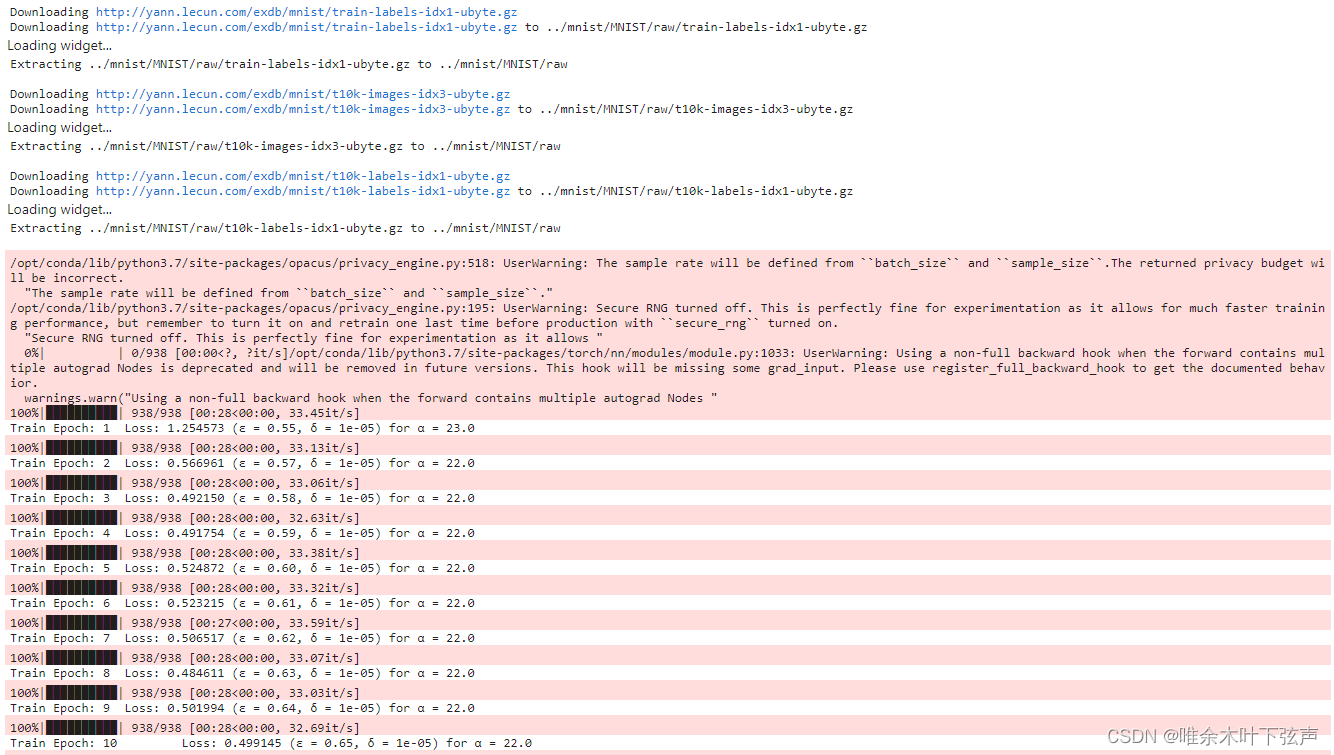
Test_set: Average loss: -27.2745, Accuracy: 9230/10000 (92.30%)可以看到,预测准确率较引入差分隐私技术之前下降了6.59个百分点,还可以接受。
四、总结
虽然opacus开发者在GitHub上提出DP-SGD对模型训练性能几乎没有影响,不过在对比实验中证明还是会有一定的性能下降。这是隐私保护的代价——由于在查询结果中引入随机性,导致数据的可用性下降。
参考文献:
1、隐私计算联盟、中国信通院云大所《隐私计算白皮书》
3、差分隐私系列之一:差分隐私的定义,直观理解与基本性质 - 知乎
4、Dwork C. Differential privacy: A survey of results[C]//International conference on theory and applications of models of computation. Springer, Berlin, Heidelberg, 2008: 1-19.
5、Dwork C, Roth A. The algorithmic foundations of differential privacy[J]. Foundations and Trends® in Theoretical Computer Science, 2014, 9(3–4): 211-407.