学习笔记(四)xgboost和lightgbm的模型建立
数据是金融数据,我们要做的是预测贷款用户是否会逾期,表格中,status是标签:0表示未逾期,1表示逾期。构建xgboost和lightgbm进行预测(在构建部分数据需要进行缺失值处理和数据类型转换,如果不能处理,可以直接暴力删除)
数据需求分析
- 需要直接删除的数据
Unnamed: 0 用户ID
trade_no:不知道是什么
bank_card_no:卡号
id_name:名字
‘source’ 提示xs 先去掉 - 需要离散化处理的数据(此处不涉及)
- reg_preference_for_trad
- 针对日期数据的处理(转换成年月日)(此处不涉及)
- first_transaction_time
- latest_query_time
- loans_latest_time
- 缺失值的填充
- 归一化处理所有数据
数据处理过程
导入包(包括下面的xgboost和lightgbm)
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import*
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
数据分析过程
datanew = pd.read_csv('F:/ziliao/data/data1.csv', encoding='gbk')
"""
1.缺失值处理
"""
datanew=pd.DataFrame(datanew.fillna(0))
# 简单的缺失值处理
# datanew.replace(to_replace='0.', value=np.nan)
# 丢弃带有缺失值的数据
# datanew = datanew.dropna(axis=1, how='any')
data_columns = datanew.columns
"""
1.2 对reg_preference_for_trad 的处理 【映射】
nan=0 境外=1 一线=5 二线=2 三线 =3 其他=4
"""
n = set(datanew['reg_preference_for_trad'])
dic = {}
for i, j in enumerate(n):
dic[j] = i
datanew['reg_preference_for_trad'] = datanew['reg_preference_for_trad'].map(dic)
"""
1.3 数据集的切分
"""
X_train, X_test, y_train, y_test = train_test_split(datanew[data_columns[1:90]], datanew[data_columns[44]],test_size=0.3, random_state=666)
X_train.drop(["status","trade_no","bank_card_no","id_0me","source"],axis=1,inplace=True)
X_test.drop(["status","trade_no","bank_card_no","id_0me", "source"],axis=1,inplace=True)
数据标准归一化
标准化数据,方差为1,均值为零进行数据的归一化
"""
1.4标准化数据,方差为1,均值为零
"""
standardScaler = StandardScaler()
X_train_fit = standardScaler.fit_transform(X_train)
X_test_fit = standardScaler.transform(X_test)
使用xgboost进行预测
安装说明:xgboost安装教程
参考文章:xgboost分类使用说明
分类使用的是 XGBClassifier
回归使用的是 XGBRegression
xgbc_model = XGBClassifier()
xgbc_model.fit(X_train_fit, y_train)
xgbc_model_predict = xgbc_model.predict(X_test_fit)
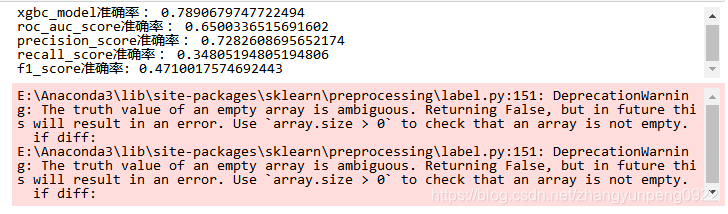
print("xgbc_model准确率:", xgbc_model.score(X_test_fit, y_test))
print("roc_auc_score准确率:", roc_auc_score(y_test, xgbc_model_predict))
print("precision_score准确率:", precision_score(y_test, xgbc_model_predict))
print("recall_score准确率:", recall_score(y_test, xgbc_model_predict))
print("f1_score准确率:",f1_score(y_test, xgbc_model_predict) )
结果如下:
使用lightgbm预测
lightgbm安装说明:lightgbm安装教程,经实践发现好像lightgbm并不支持32位的python。
参考文献:lightgbm分类使用参考1,lightgbm分类使用参考2
分类使用的是 LGBMClassifier
回归使用的是 LGBMRegression
lgbm_model = LGBMClassifier()
lgbm_model.fit(X_train_fit, y_train)
lgbm_model_predict = lgbm_model.predict(X_test_fit)
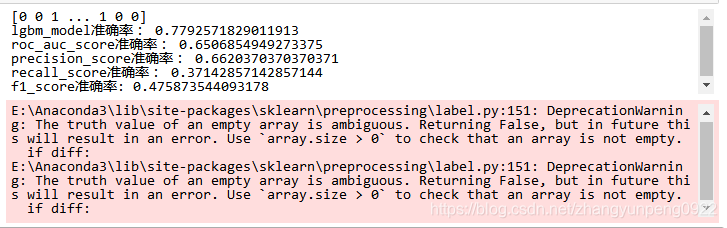
print(lgbm_model_predict)
print("lgbm_model准确率:", lgbm_model.score(X_test_fit, y_test))
print("roc_auc_score准确率:", roc_auc_score(y_test, lgbm_model_predict))
print("precision_score准确率:", precision_score(y_test, lgbm_model_predict))
print("recall_score准确率:", recall_score(y_test, lgbm_model_predict))
print("f1_score准确率:",f1_score(y_test, lgbm_model_predict) )
结果如下:
模型建立问题总结
- lightGBM的安装时,由于不支持32位,一直报错安装不上。因此,重装了64位版本的才安装成功。
- 由于不了解模型, lightGBM刚开始使用了LGBMRegression(),结果得出的预测值是0.0-1.0的回归值,后使用LGBMClassifier才能得到【0,1】的预测值。故明白LGBMRegression是解决线性问题,LGBMClassifier解决的是分类问题。、
- lightGBM和xgboost不熟悉,需要好好读读文档。