本文主要参考Battle of the Boosting Algos: LGB, XGB, Catboost,结果与原文有出入。
文章目录
1. 对比标准
1.1 数据集
- 分类:Fashion MNIST(60000条数据784个特征)
- 回归:NYC Taxi fares(60000条数据7个特征)
- 大规模数据集:NYC Taxi fares(2百万条数据7个特征)
PS:本文只进行了分类的对比
1.2 规则
- 使用基准模型
- 使用相同参数训练并利用GridSearchCV调参
- 比较训练和预测耗时、预测分数、可解释性
1.3 版本
xgboost==0.90
lightgbm==2.3.1
catboost==0.21
2. 结果
2.1 准确率
LightGBM>XGBoost>CatBoost
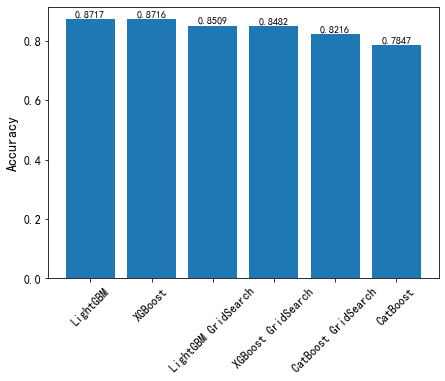
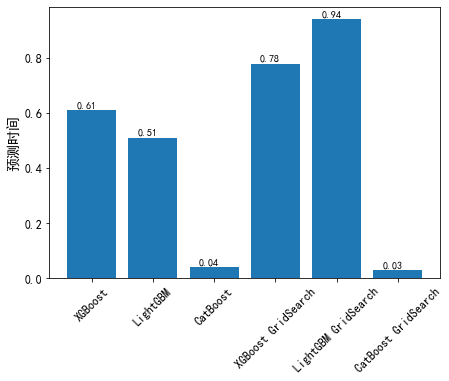
2.2 训练时间和预测时间
CatBoost<LightGBM<XGBoost

2.3 可解释性
XGBoost=LightGBM>Catboost
2.3.1 特征重要性
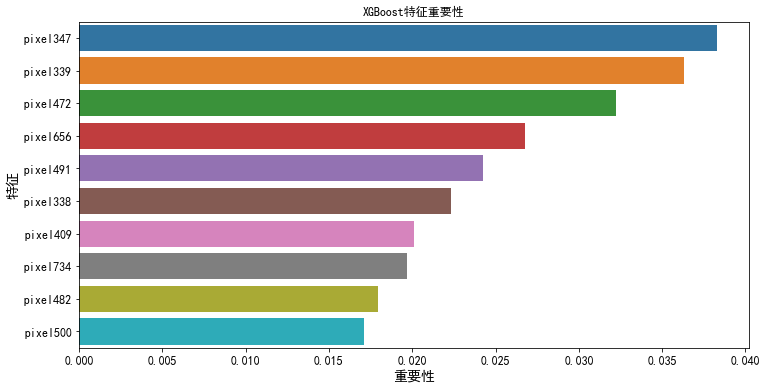
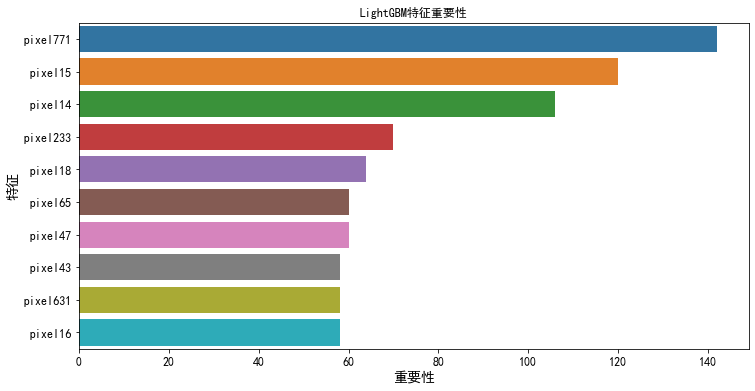
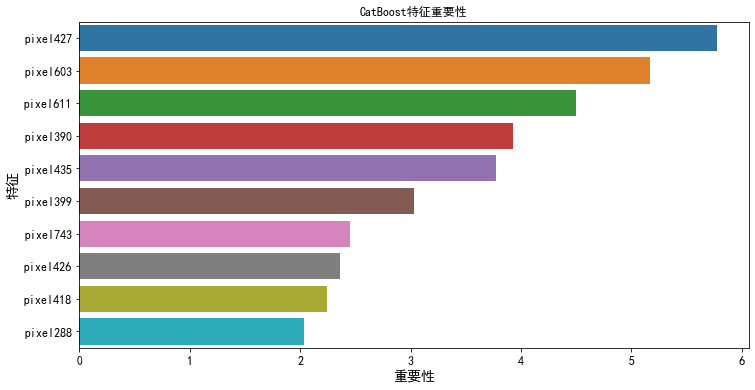
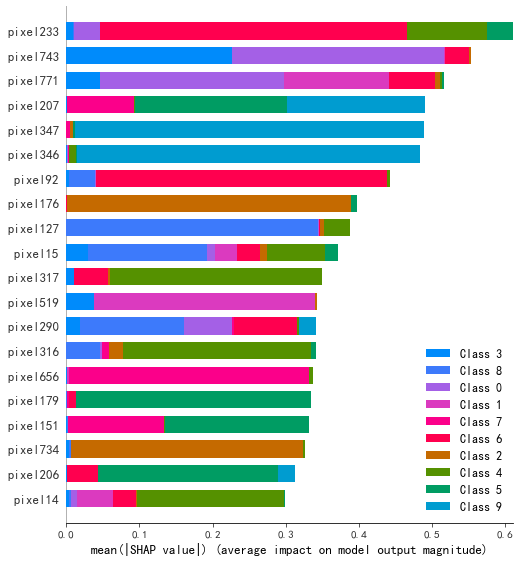
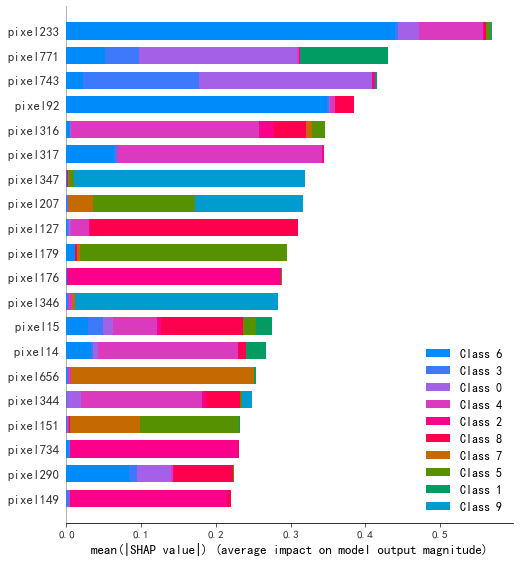
2.3.2 SHAP值
| 类别 | 含义 |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
XGBoost
LightGBM
CatBoost无法开箱即用
2.3.3 可视化二叉树
XGBoost

LightGBM
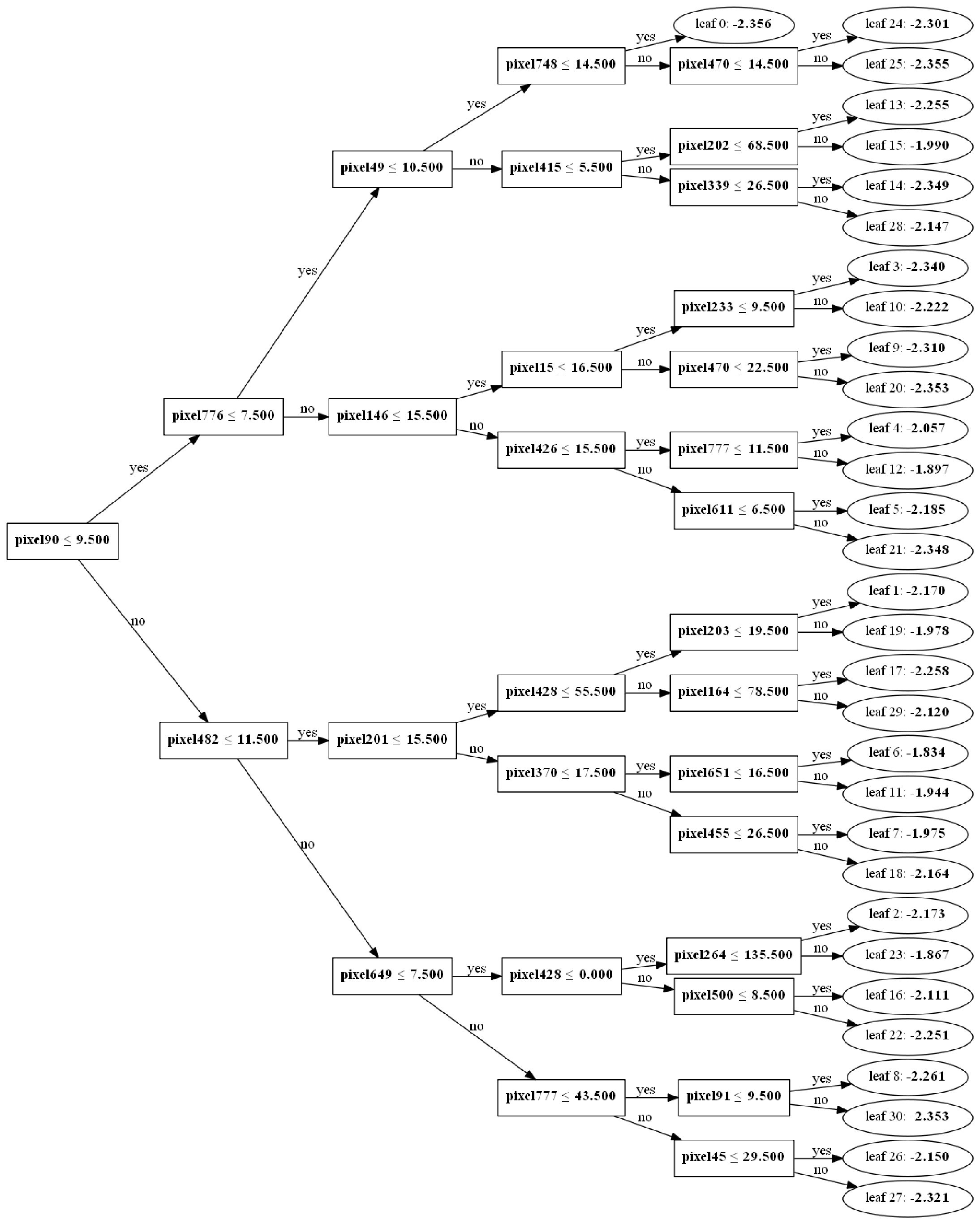
CatBoost绘制树函数
3. 总结
比赛选LightGBM,工业选Catboost
4. 代码
https://download.csdn.net/download/lly1122334/12171980
参考文献
- Battle of the Boosting Algos: LGB, XGB, Catboost
- Battle of the Boosting Algorithms
- mlxtend: A library of extension and helper modules for Python’s data analysis and machine learning libraries
- shap: A game theoretic approach to explain the output of any machine learning model
- http://www.picnet.com.au/blogs/guido/post/2016/09/22/xgboost-windows-x64-binaries-for-download/
- Graphviz - Graph Visualization Software Windows Packages
备份
# Feature Engineering
# this cell was adapted from https://www.kaggle.com/mahtieu/nyc-taxi-fare-prediction-data-expl-xgboost
def feature_engineering(df):
df['pickup_datetime'] = pd.to_datetime(df['pickup_datetime'])
#Drop rows with null values
df = df.dropna(how = 'any', axis = 'rows')
#Free rides, negative fares and passenger count filtering
df = df[df.eval('(fare_amount > 0) & (passenger_count <= 6)')]
# Coordinates filtering - Pickup and dropoff locations should be within the limits of NYC
df = df[(df.pickup_longitude >= -77) &
(df.pickup_longitude <= -70) &
(df.dropoff_longitude >= -77) &
(df.dropoff_longitude <= 70) &
(df.pickup_latitude >= 35) &
(df.pickup_latitude <= 45) &
(df.dropoff_latitude >= 35) &
(df.dropoff_latitude <= 45)]
df.pickup_datetime = df.pickup_datetime.dt.tz_convert('UTC')
df.pickup_datetime = df.pickup_datetime.dt.tz_convert('America/New_York')
# Fares may change every year
df['year'] = df.pickup_datetime.dt.year
# Different fares during weekdays and weekends
df['dayofweek'] = df.pickup_datetime.dt.dayofweek
# Different fares during public holidays
df['dayofyear'] = df.pickup_datetime.dt.dayofyear
# Different fares in peak periods and off-peak periods
df['hourofday'] = df.pickup_datetime.dt.hour
df = df.drop('pickup_datetime', axis=1)
# Computes the distance (in miles) between the pickup and the dropoff locations
df['distance'] = df.apply(
lambda x: distance.distance((x.pickup_latitude, x.pickup_longitude), (x.dropoff_latitude, x.dropoff_longitude)).miles,
axis = 1)
df = df[df.eval('(distance > 0) & (distance < 150)')]
fare_distance_ratio = (df.fare_amount/df.distance)
fare_distance_ratio.describe()
(fare_distance_ratio[fare_distance_ratio < 45]).hist()
# Drop incoherent fares
df = df[fare_distance_ratio < 45]
del fare_distance_ratio
# Coordinates of the 3 airpots of NYC
airports = {'jfk': [40.6441666, -73.7822222],
'laguardia': [40.7747222, -73.8719444],
'newark': [40.6897222, -74.175]}
# Computes the distance between the pickup location and the airport
pickup = df.apply(lambda x: distance.distance((x.pickup_latitude, x.pickup_longitude), (airports.get('jfk'))).miles, axis=1)
# Computes the distance between the dropoff location and the airport
dropoff = df.apply(lambda x: distance.distance((x.dropoff_latitude, x.dropoff_longitude), (airports.get('jfk'))).miles, axis=1)
# Selects the shortest distance
df['to_jfk'] = pd.concat((pickup, dropoff), axis=1).min(axis=1)
pickup = df.apply(lambda x: distance.distance((x.pickup_latitude, x.pickup_longitude), (airports.get('laguardia'))).miles, axis=1)
dropoff = df.apply(lambda x: distance.distance((x.dropoff_latitude, x.dropoff_longitude), (airports.get('laguardia'))).miles, axis=1)
df['to_laguardia'] = pd.concat((pickup, dropoff), axis=1).min(axis=1)
pickup = df.apply(lambda x: distance.distance((x.pickup_latitude, x.pickup_longitude), (airports.get('newark'))).miles, axis=1)
dropoff = df.apply(lambda x: distance.distance((x.dropoff_latitude, x.dropoff_longitude), (airports.get('newark'))).miles, axis=1)
df['to_newark'] = pd.concat((pickup, dropoff), axis=1).min(axis=1)
del pickup, dropoff
return df
