统计学习的三要素:
(1)模型:所要学习的条件概率分布或决策函数。
(2)策略:按照什么样的准则学习或选择最优的模型。
(3)算法:学习模型的具体计算方法。
方法 = 模型 + 策略 + 算法
统计学习包括:
监督学习,半监督学习,非监督学习,强化学习
监督学习的方法与应用:
分类问题,标注问题,回归问题
模型的选择方法:
正则化,交叉验证,学习的泛化能力
统计学习的目的:对数据进行预测与分析。
目标:从假设空间中选取最优模型。
对象:数据
回归问题:
输入变量与输出变量均为连续变量的预测问题。
分类问题:
输出变量为有限个离散变量的预测问题。
标注问题:
输入变量与输出变量均为变量序列的预测问题。
联合概率分布:
两个及以上随机变量组成的随机变量的概率分布。表示为:P(X,Y)
条件概率分布:
就是由条件的联合概率分布。描述输入与输出随机变量之间的映射关系。
假设空间:
模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间。
监督学习:
利用训练数据集学习一个模型,再用模型对测试样本集进行预测。
分为两个部分:训练和预测。
风险函数:
度量平均意义下模型预测的好坏。
损失函数:
度量模型一次预测的好坏。记作:L(Y,f(x)).损失函数值越小,模型就越好。

损失函数的期望:
期望风险R(exp)是模型关于联合分布的期望损失。
经验风险或经验损失:模型关于训练数据集的平均损失。记作R(emp):
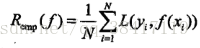
当样本容量N趋于无穷时,经验风险趋于期望风险。
经验风险最小化(ERM)
当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。
结构风险最小化(SRM):为了防止过拟合而提出来的策略。
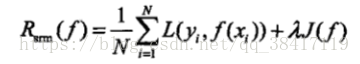
结构风险最小化等价于正则化。
结构风险最小化就等价于最大后验概率估计。
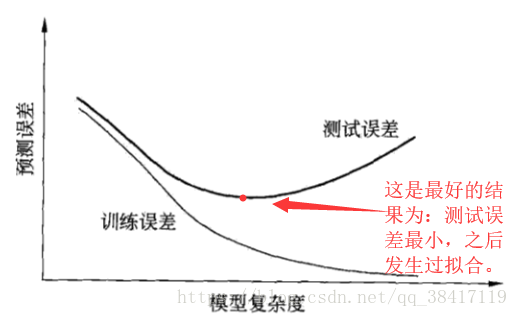
过拟合:
所选模型的复杂度往往会比真模型更高。
这一现象对已知数据预测的很好,但对未知数据预测的很差的现象。
正则化:
一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
一般形式:
第一项是经验风险,第二项是正则化。
正则化项可以是参数向量的L2范数:
L1范数:
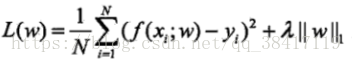
交叉验证:
训练集:训练模型。
验证集:模型的选择。
测试集:最终对学习方法的评估。
基本想法:重复地使用数据。
1.简单的交叉验证
随机地将已给数据分为两部分。
2.S折交叉验证
随机地将已给数据分为S个互不相交的大小想同的子集;
然后利用 S-1 个子集的数据训练模型,利用余下的子集测试模型。
3.留一交叉验证
S折交叉验证的特殊情形是 S = N。
泛化能力:
通过测试误差来评价学习方法的泛化能力。
泛化误差就是所学习得到的模型的期望风险
泛化误差:
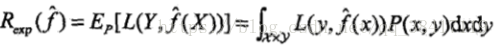
泛化误差上界:

欧式空间:

输出空间远远小于输入空间。