第一章 统计学习方法概论
1、统计学习的定义、研究对象与方法
统计学习(statistical learning)是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。
统计学习的对象是数据。从数据出发,提取数据的特征,抽象出数据的模型,发现数据中的知识,又回到对数据的分析与预测中去。以变量和变量组表示数据,数据分为由连续变量和离散变量表示的 类型。
统计学习的方法是基于数据构建统计模型从而对数据进行预测与分析。统计学习由监督学习(supervised leaning)、非监督学习(unsupervised learning)、半监督学习(semi-supervised learning)和强化学习(reinforcement learning)等组成。
实现统计学习方法的步骤如下:
(1)得到一个有限的训练数据集合;
(2)确定包含所有可能的模型的假设空间,即学习模型的集合;
(3)确定模型选择的准则,即学习的策略;
(4)实现求解最优模型的算法,即学习的算法;
(5)通过学习方法选择最优模型;
(6)利用学习得最优模型对新数据进行预测或分析。
输入输出变量的不同类型,预测任务的名称也不同。

2、监督学习
区分监督学习、半监督学习、无监督学习及强化学习
⒈ 监督学习
已知训练数据和训练数据分类后的结果(数据具有的标签)。有监督学习的结果可分为两类:分类或回归。
2. 无监督学习
只有训练数据,没有训练数据分类后的结果
3. 半监督学习
训练数据的一部分分类结果已知,一部分分类结果未知。
4. 强化学习
使用未标记的数据,但是可以通过某种方法知道你是离正确答案越来越近还是越来越远(即奖惩函数)。
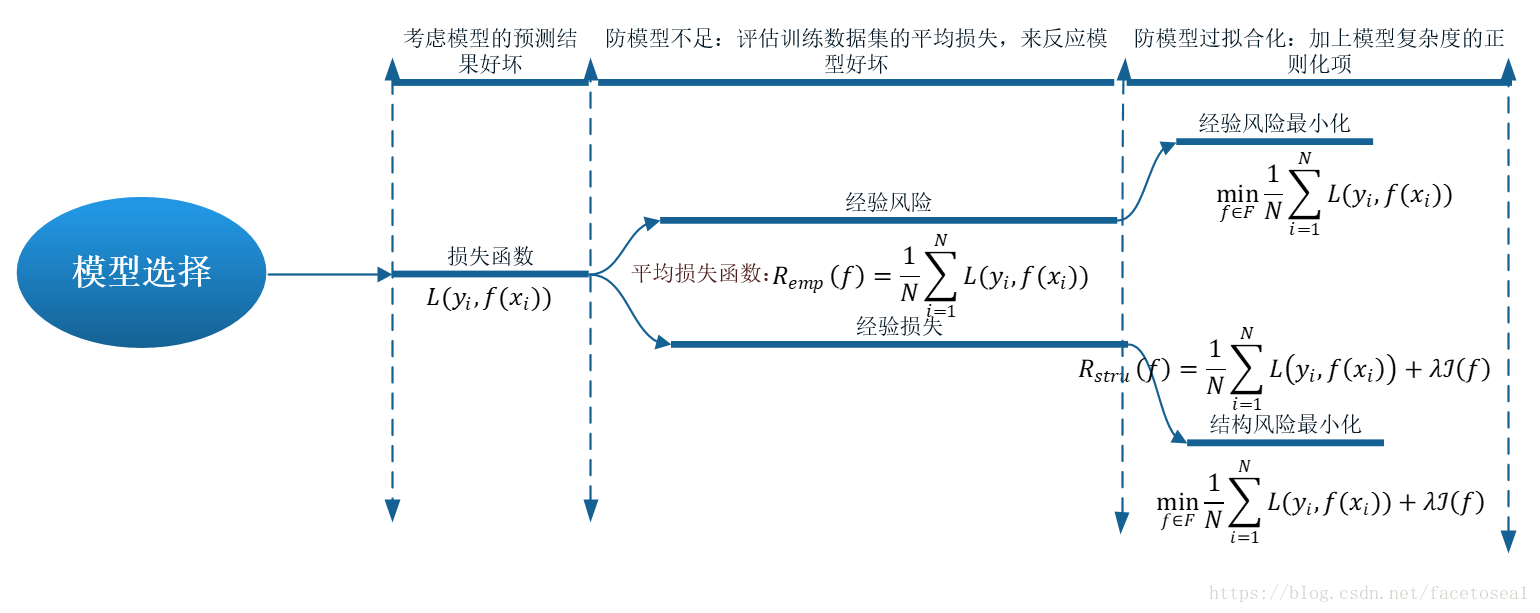
3、统计学习方法三要素
方法 = 模型 + 策略 + 算法
模型:学习什么样的模型? ——确定假设模型空间
策略:按照什么样的准则学习或选择最优的模型 ——有了模型的假设空间,确定依据准则
算法:实现学习模型的具体计算方法