机器学习和统计学习
目录

一、机器学习定义
-“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。
-“机器学习是对能通过经验自动改进的计算机算法的研究”。
-“机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。”
-英文定义:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
二、机器学习和数据挖掘的关系
机器学习是数据挖掘的重要工具。
数据挖掘不仅仅要研究、拓展、应用一些机器学习方法,还要通过许多非机器学习技术解决数据仓储、大规模数据、数据噪音等等更为实际的问题。
机器学习的涉及面更宽,常用在数据挖掘上的方法通常只是“从数据学习”,然则机器学习不仅仅可以用在数据挖掘上,一些机器学习的子领域甚至与数据挖掘关系不大,例如增强学习与自动控制等等。
数据挖掘试图从海量数据中找出有用的知识。
大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。

三、机器学习和统计学习
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习和统计推断学联系尤为密切,也被称为统计学习理论。
| Glossary(Robert Tibshiriani) |
|
| Machine learning |
Statistics |
| network, graphs |
model |
| weights |
parameters |
| learning |
fitting |
| generalization |
test set performance |
| supervised learning |
regression/classification |
| unsupervised learning |
density estimation, clustering |
| large grant = $1,000,000 |
large grant = $50,000 |
| nice place to have a meeting: |
nice place to have a meeting: |
统计学 机器学习
———————————–————–
Estimation(估计) Learning(学习)
Classifier(分类器) Hypothesis(假设)
Data point(数据点) Example/Instance(示例/实例)
Regression(回归) Supervised Learning(监督学习)
Classification(分类) Supervised Learning(监督学习)
Covariate(协变量) Featur(特征)
Response(响应) Label(标注)
四、统计学习
1、监督学习
•问题的形式化

2、无监督学习
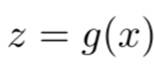

3、强化学习


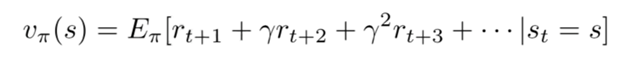
4、半监督学习
5、主动学习
- 机器主动给出实例,教师进行标注
- 利用标注数据学习预测模型
五、统计学习方法
1、按算法分类
- 在线学习(online learning)
- 批量学习(batch learning)
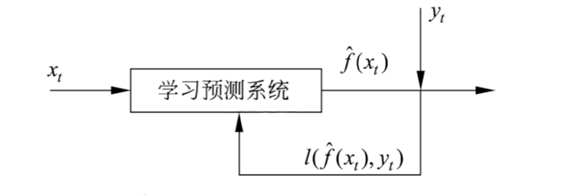
2、按技巧分类


核方法在输入空间中定义核函数 K(x1, x2),使其满足 K(x1, x2) = < φ(x1), φ(x2)>
3、统计学习三要素
方法=模型+策略+算法





4、模型评估与模型选择




5、正则化与交叉验证
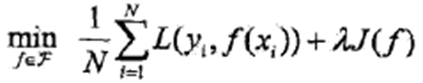


6、泛化能力 generalization ability
![]()
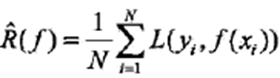
•经验风险最小化函数:

•泛化能力
![]()
•定理:泛化误差上界,二分类问题,
当假设空间是有限个函数的结合 ,
对任意一个函数f, 至少以概率1-δ,以下不等式成立:
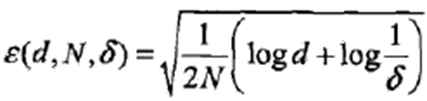
7、生成模型与判别模型
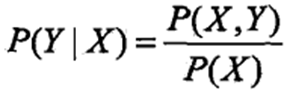
•判别方法:直接学习到条件概率或决策函数,直接进行预测,往往学习的准确率更高;由于直接学习Y=f(X)或P(Y|X),可对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习过程。
8、分类问题


9、标注问题

10、回归问题
