前言(自己整理的)

![]() 输入数据
输入数据

戴帽子的f 和 戴帽子的P 是从假设空间(各种模型集合)中选择最好的模型。
统计学习的方法概括如下:
- 从给定的、有限的、用于学习的训练数据集合出发,假设数据是独立同分布产生的;
- 并且假设要学习的模型属于某个函数的集合,成为假设空间(上图的学习系统);
- 应用某个评价准则,从假设空间中选取一个最优的模型,使它对已知训练数据及未知测试数据 在给定的评价准则下,有最优测预测;
- 最优模型(上图的模型)的选取由算法实现。
本章内容,共10小节,取自《统计学习方法》---第一版 李航。
1 统计学习
1. 统计学习特点
- (1)统计学习,以计算机及网络为平台,是建立在计算机及网络之上的;
- (2)统计学习,以数据位研究对象,是数据驱动的学科;
- (3)统计学习,目的是对数据进行预测和分析;
- (4)统计学习,以方法为中心,统计--学习方法,构建--模型,应用--模型进行预测与分析;
- (5)统计学习,是概率论、统计学、信息论、计算机理论、最优化理论及计算机科学等多个领域的交叉学科,并在发展中逐步形成独自的理论体系与方法论。
2. 统计学习对象
数据。数据包括:勋在与计算机及网络上的各种数字、文字、图像、视频、音频数据,以及它们的组合。
3. 统计学习的目的
用于对数据进行预测与分析,特别是对未知新数据进行预测与分析。
4. 统计学习的方法
监督学习、非监督学习,半监督学习,强化学习等。以下主要讨论监督学习。
5. 统计学三要素:模型、策略、算法。
6. 监督学习(统计学习方法)的实现步骤:
- (1)得到一个有限的训练数据集合;
- (2)确定包含所有可能的模型的假设空间,即学习模型的集合;
- (3)确定模型选择的准则,即学习的策略;
- (4)实现求解最优模型的算法,即学习的算法;
- (5)通过学习方法选择最优模型;
- (6)利用学习的最优模型,对新数据进行预测或分析。
备注:2/3/4步骤,包含在学习系统中;5步骤,包含在模型系统中,f^ P^ 是从学习系统中选定的模型;6步骤是预测系统。
2 监督学习
学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。
1. 基本概念
输入空间:所有可能取值的输入集合(与下面的输出要对应)。
输出空间:所有可能取值的输出集合(与上面的输入要对应)。
特征空间:每个具体的输入是一个实例,通常由特征向量表示,所有特征向量存在的空间,称为特征空间。
输入实例x的特征向量记作:
![]()
训练集:![]()
联合概率分布:监督学习假设输入与输出的随机变量X和Y遵循联合概率分布P(X,Y). P(X, Y) 表示分布函数,或分布密度函数。
假设空间:输入到输出是一个映射,映射用模型来表示,模型属于由输入控件到输出空间的映射的集合,这个集合就是假设空间。俗话说:好多种模型放到一起,这个就叫假设空间。假设空间中,有各种备选模型。
模型:
1>决策函数
2>条件概率分布
3 统计学习三要素
方法 = 模型+策略+算法
1. 模型的假设空间包含:决策函数 or 条件概率分布
2. 策略:首先引入损失函数和风险函数。损失函数度量模型一次预测的好坏,度量预测错误的程度。损失函数(共列举4个,前3个针对决策函数,后1个针对条件概率分布). 风险函数度量平均意义下模型预测的好坏。
常用的损失函数有如下几种:


(4)对数损失函数或对数似然损失函数:![]()
损失函数值越小,模型越好。由于模型的输入、输出(X, Y)是随机变量,遵循联合分布 P(X, Y),所以损失函数的期望:

风险函数:
(1)经验风险最小化策略认为:经验风险最小的模型,是最优的模型:
(2)结构风险最小化是为了防止过拟合而提出来的策略:
后者相比于前者,多了一个模型复杂度。监督学习问题,转变为了检验风险或结构风险函数的最优化问题。
3. 算法 是指学习模型的具体计算方法。
4 模型评估与模型选择
当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差,就成为了学习方法评估的标准。
训练误差
 N个数据,戴帽子的f, 是选择的算法模型。
N个数据,戴帽子的f, 是选择的算法模型。
测试误差
 N' 个数据,戴帽子的f, 是选择的算法模型。
N' 个数据,戴帽子的f, 是选择的算法模型。
过拟合与模型选择:参数少预测不好,参数多,又容易过拟合(数据稍微有不同,预测据结果偏差大),就需要折中考虑。
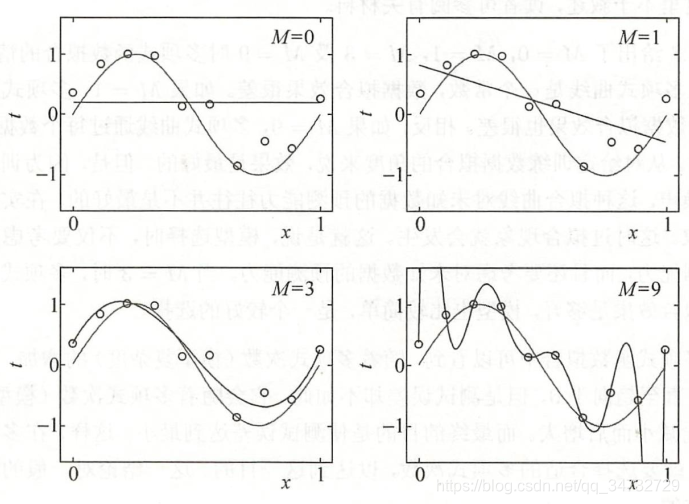
设M次多项式:
如图所示,第一个0次,第二个1次,第三个3次,第四个9次。3次的结果,拟合最好,9次的结果,虽然都连起来,但是稍微有个新点,就会波动非常大。

上图描述了训练误差和测试误差与模型的复杂度之间的关系。当模型的复杂度增大时,训练误差会主键减小并趋向于0;而测试误差会先减小,达到最小值后又增大。当选择的模型复杂度过大时,过拟合现象就会发生。
5 正则化与交叉验证
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
 第一项是经验风险,第二项是正则化项(带系数)。
第一项是经验风险,第二项是正则化项(带系数)。
交叉验证,将数据随机分为三份:训练集、验证集、测试集。训练集:训练出多种模型; 验证集:检验每种模型,确定最好模型;测试集:用于最终的对学习方法的评估。
6 泛化能力
泛化能力:由该方法学习的模型对未知数据的预测能力。
泛化误差:对于学习到的模型f^, 用这个模型对未知数据预测的误差。泛化误差反应学习方法的泛化能力。
泛化误差上界:

7 生成模型与判别模型
模型一般形式为决策函数 Y = f(X)或条件概率分布P(Y|X)。
监督学习方法又可以分为:生成方法 和 判别方法。
学习到的模型分为: 生成模型 和 判别模型。
生成方法由数据学习联合概率分布P(X, Y), 然后求出条件概率分布 P(Y|X) 作为预测的模型,即生成模型:
 , 这样的方法称之为生成方法。
, 这样的方法称之为生成方法。
8 分类问题
将输入分为两类,是2分类问题。将输入分为多个类别,是多分类问题。
分类器在测试数据集的预测上,有4中情况:

![]()
T:True, F:False , P: Positive, N:Negative. 精确率和召回率都高时,F1值也会高。
9 标注问题
输入是一个观测序列,输出是一个标记序列或转态序列。标注问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。比如:一串英文,有了学习模型之后,对这段英文进行预测,对每个词进行标注。

10 回归问题
回归用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生变化。
回归问题的学习等价于函数拟合:选择一条函数曲线,使其很好的拟合已知数据且很好的预测未知数据。
仅个人学习的粗略整理,好多公式细则没有写,可以看《统计学习方法》书籍,去具体查阅。
