通俗理解神经网络BP反向传播算法
在学习深度学习相关知识,无疑都是从神经网络开始入手,在神经网络对参数的学习算法bp算法,接触了很多次,每一次查找资料学习,都有着似懂非懂的感觉,这次趁着思路比较清楚,也为了能够让一些像我一样疲于各种查找资料,却依然懵懵懂懂的孩子们理解,参考了梁斌老师的博客BP算法浅谈(Error Back-propagation)(为了验证梁老师的结果和自己是否正确,自己python实现的初始数据和梁老师定义为一样!),进行了梳理和python代码实现,一步一步的帮助大家理解bp算法!
为了方便起见,这里我定义了三层网络,输入层(第0层),隐藏层(第1层),输出层(第二层)。并且每个结点没有偏置(有偏置原理完全一样),激活函数为sigmod函数(不同的激活函数,求导不同),符号说明如下:

对应网络如下:

其中对应的矩阵表示如下:

首先我们先走一遍正向传播,公式与相应的数据对应如下:

那么:

同理可以得到

那么最终的损失为

我们当然是希望这个值越小越好。这也是我们为什么要进行训练,调节参数,使得最终的损失最小。这就用到了我们的反向传播算法,实际上反向传播就是梯度下降法中(为什么需要用到梯度下降法,也就是为什么梯度的反方向一定是下降最快的方向,我会再写一篇文章解释,这里假设是对的,关注bp算法)链式法则的使用。
下面我们看如何反向传播
根据公式,我们有:

这个时候我们需要求出C对w的偏导,则根据链式法则有
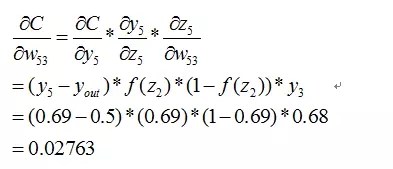
上面插入sigmod函数求导公式:

(在这里我们可以看到不同激活函数求导是不同的,所谓的梯度消失,梯度爆炸如果了解bp算法的原理,也是非常容易理解的!)
同理有
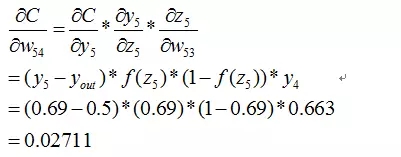
到此我们已经算出了最后一层的参数偏导了.我们继续往前面链式推导:
我们现在还需要求
![]() 下面给出其中的一个推到,其它完全类似
下面给出其中的一个推到,其它完全类似

同理可得到其它几个式子:
则最终的结果为:

再按照这个权重参数进行一遍正向传播得出来的Error为0.165
而这个值比原来的0.19要小,则继续迭代,不断修正权值,使得代价函数越来越小,预测值不断逼近0.5.我迭代了100次的结果,Error为5.92944818e-07(已经很小了,说明预测值与真实值非常接近了),最后的权值为:

好了,bp过程可能差不多就是这样了,可能此文需要你以前接触过bp算法,只是还有疑惑,一步步推导后,会有较深的理解。
分享链接:
中文版资料:链接:http://pan.baidu.com/s/1mi8YVri 密码:e7do
下面给出我学习bp时候的好的博客
Backpropagation (里面的插图非常棒,不过好像有点错误,欢迎讨论~)
A Neural Network in 11 lines of Python (Part 1)(非常赞的博客,每个代码一行一行解释)
Neural networks and deep learning (很好的深度学习入门书籍,实验室力推!我有中文翻译版,欢迎留言)
上面实现的python代码如下:

源文件下载链接如下:http://pan.baidu.com/s/1slpmYPR
我也是在学习过程中,欢迎大家提出错误问题。真心希望加深大家对bp算法的理解。
参考自梁斌老师博客.