物联网技术部第二次软件培训总结
文章目录
一、结构体
1.定义结构
为了定义结构,您必须使用 struct 语句。struct 语句定义了一个包含多个成员的新的数据类型, struct 语句的格式如下:
struct tag {
member-list
member-list
member-list
...
} variable-list ;
tag 是结构体标签。
member-list 是标准的变量定义,比如 int i ; 或者 float f ; 或者其他有效的变量定义。
variable-list 结构变量,定义在结构的末尾,最后一个分号之前,您可以指定一个或多个结构变量。下面是声明 Book 结构的方式:
struct Books{
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。以下为实例:

• 在上面的声明中,第一个和第二声明被编译器当作两个完全不同的类型,即使他们的成员列表是一样的,如果令 t3=&s1,则是非法的。
• 结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。

2.结构体变量的初始化
和其它类型变量一样,对结构体变量可以在定义时指定初始值


3.访问结构成员
为了访问结构的成员,我们使用成员访问运算符(.)。成员访问运算符是结构变量名称和我们要访问的结构成员之间的一个句号。您可以使用 struct 关键字来定义结构类型的变量。下面的实例演示了结构的用法:


4.结构作为函数参数
您可以把结构作为函数参数,传参方式与其他类型的变量或指针类似。您可以使用上面实例中的方式来访问结构变量:




5.指向结构的指针
您可以定义指向结构的指针,方式与定义指向其他类型的指针相似,如下所示:
struct Books *struct_pointer ;
现在,您可以在上述定义的指针变量中存储结构变量的地址,请把 & 运算符放在结构名称的前面,如下所示:
struct_pointer = &Book1 ;
为了使用指向该结构的指针访问结构的成员,您必须使用 -> 运算符,如下所示:
struct_pointer -> title ;



二、时间复杂度
1.定义
什么是时间复杂度,算法中某个函数有n次基本操作重复执行,用T(n)表示,现在有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。通俗一点讲,其实所谓的时间复杂度,就是找了一个同样曲线类型的函数f(n)来表示
这个算法的在n不断变大时的趋势 。当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂性”。
2.简单的时间复杂度举例
列举一些简单例子的时间复杂度。
O(1)的算法是一些运算次数为常数的算法。例如:
temp=a;a=b;b=temp;
上面语句共三条操作,单条操作的频度为1,即使他有成千上万条操作,也只是个较大常数,这一类的时间复杂度为O(1)。
O(n)的算法是一些线性算法。例如:
sum=0;
for(i=0;i<n;i++)
sum++;
上面代码中第一行频度1,第二行频度为n,第三行频度为n,所以f(n)=n+n+1=2n+1。所以时间复杂度O(n)。这一类算法中操作次数和n正比线性增长。
O(logn) 一个算法如果能在每个步骤去掉一半数据元素,如二分检索,通常它就取 O(logn)时间。举个栗子:
int i=1;
while (i<=n)
i=i*2;
上面代码设第三行的频度是f(n), 则:2的f(n)次方<=n;f(n)<=log₂n,取最大值f(n)= log₂n,所以T(n)=O(log₂n ) 。
O(n²)(n的k次方的情况)最常见的就是平时的对数组进行排序的各种简单算法都是O(n²),例如直接插入排序的算法。
而像矩阵相乘算法运算则是O(n³)。
举个简单栗子:
sum=0;
for(i=0;i<n;i++)
for(j=0;j<n;j++)
sum++;
第一行频度1,第二行n,第三行n²,第四行n²,T(n)=2n²+n+1 =O(n²)
三、分治法(Divide and Conquer)
1.分治法的精髓:
①分–将问题分解为规模更小的子问题;
②治–将这些规模更小的子问题逐个击破;
③合–将已解决的子问题合并,最终得出“母”问题的解;**
分治法的作用,自然是让程序更加快速地处理问题。比如一个n的问题分解成两个n/2的问题,并由两个人来完成,效率就会快一些。当然单线程的程序的分治法,就是把n的问题剔除掉可以省略的步骤,从而提高程序运行的速度。
1.找数字
假设我们需要在1-10000里面找一个数200,使用逐个搜索的方法,我们会消耗200步。如果计入小数的画,恐怕就大大超过200这个消耗了。
假如使用二分法:
• 第一步我们找到1-10000中间的那个数:5000。它大于200,所以200应该在1-4999这个区间内,这样我们就丢掉了后5000个数。
• 第二步我们找到2500,也比200要大,200在1-2500这个区间内。
• 第三步找到1250这个数,也比200大。
• 第四步找到750。
• 第五步找到375。
• 第六步找到167,它比200要小了,说明200在167-375之间。
• 第七步找到271,它在167-271之间。
• 第八步找到219,它在167-219之间。
• 第九步找到193,它在193-219之间。
• 第十步找到206,它在193-206之间。
• 第十一步找到199,它在199-206之间。
• 第十二步找到202,它在199-202之间。
• 第十三步找到200。
2.快速排序介绍
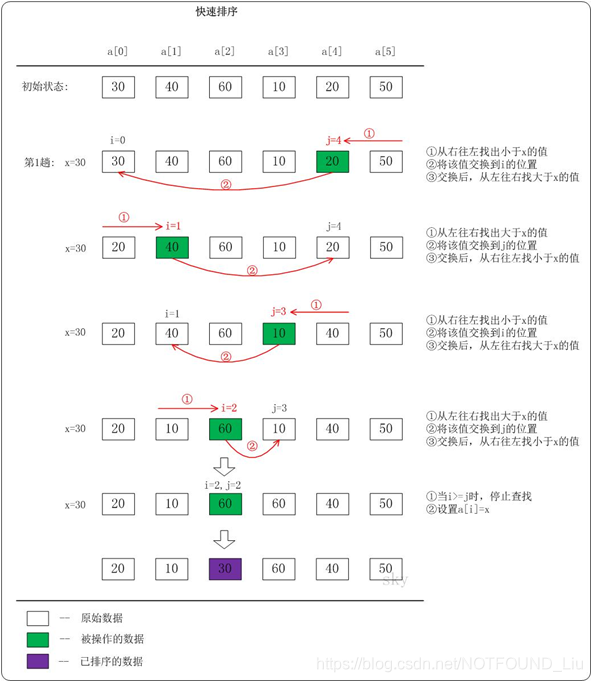
快速排序(Quick Sort)使用分治法策略。
它的基本思想是:选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序流程:
(1) 从数列中挑出一个基准值。
(2) 将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
(3) 递归地把"基准值前面的子数列"和"基准值后面的子数列"进行排序。

3.归并排序介绍
将两个的有序数列合并成一个有序数列,我们称之为"归并"。
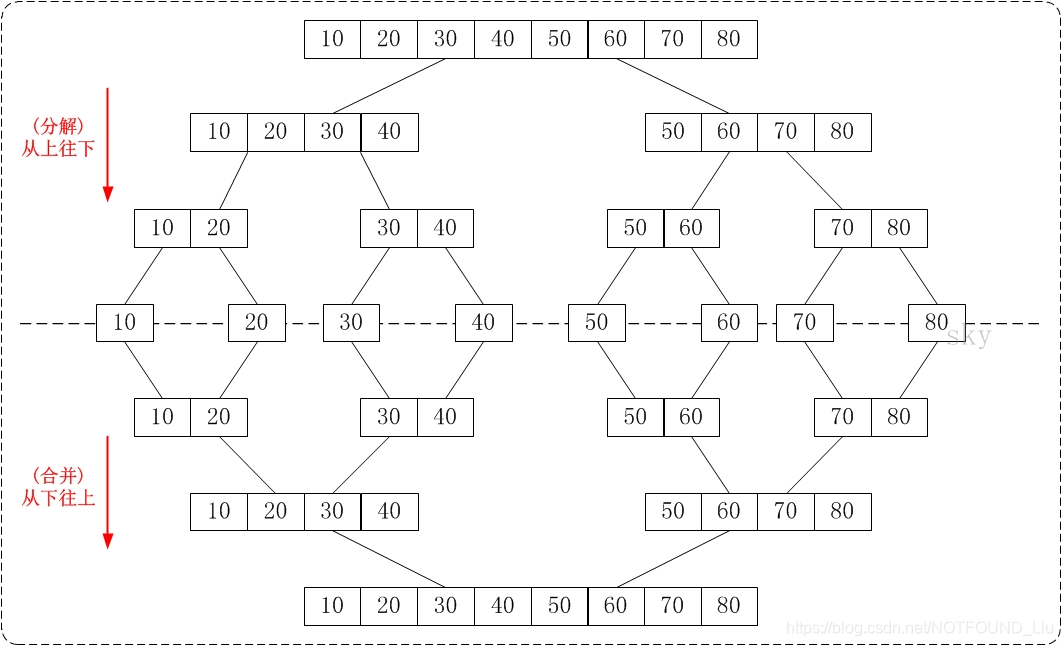
归并排序(Merge Sort)就是利用归并思想对数列进行排序。根据具体的实现,归并排序包括"从上往下"和"从下往上"2种方式:
- 从下往上的归并排序:将待排序的数列分成若干个长度为1的子数列,然后将这些数列两两合并;得到若干个长度为2的有序数列,再将这些数列两两合并;得到若干个长度为4的有序数列,再将它们两两合并;直接合并成一个数列为止。这样就得到了我们想要的排序结果。(参考下面的图片)
- 从上往下的归并排序:它与"从下往上"在排序上是反方向的。它基本包括3步:
① 分解 – 将当前区间一分为二,即求分裂点 mid = (low + high)/2;
② 求解 – 递归地对两个子区间a[low…mid] 和 a[mid+1…high]进行归并排序。递归的终结条件是子区间长度为1。
③ 合并 – 将已排序的两个子区间a[low…mid]和 a[mid+1…high]归并为一个有序的区间a[low…high]。
归并排序(从上往下)代码:


从上往下的归并排序采用了递归的方式实现。它的原理非常简单,如下图:
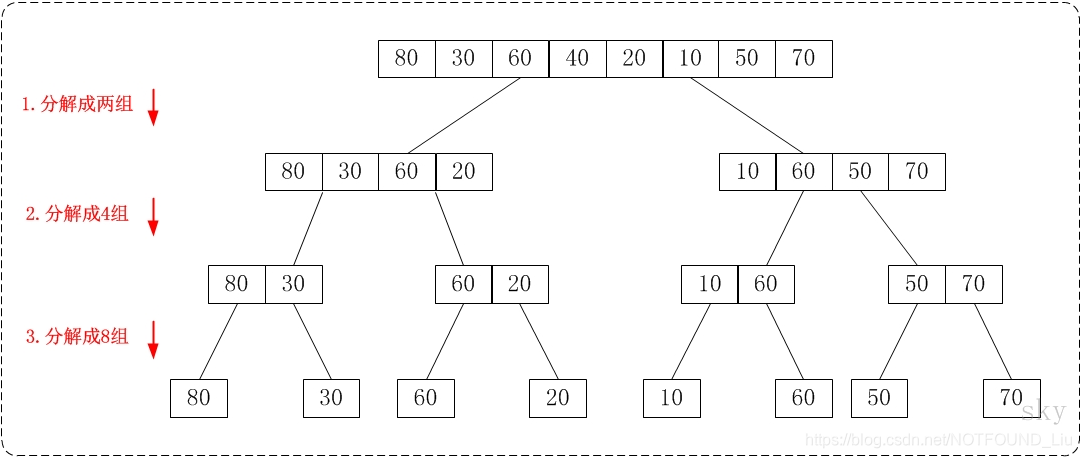
通过"从上往下的归并排序"来对数组{80,30,60,40,20,10,50,70}进行排序时:
① 将数组{80,30,60,40,20,10,50,70}看作由两个有序的子数组{80,30,60,40}和 {20,10,50,70}组成。对两个有序子树组进行排序即可。
②将子数组{80,30,60,40}看作由两个有序的子数组{80,30}和{60,40}组成。
将子数组{20,10,50,70}看作由两个有序的子数组{20,10}和{50,70}组成。
③将子数组{80,30}看作由两个有序的子数组{80}和{30}组成。
将子数组{60,40}看作由两个有序的子数组{60}和{40}组成。
将子数组{20,10}看作由两个有序的子数组{20}和{10}组成。
将子数组{50,70}看作由两个有序的子数组{50}和{70}组成。
归并排序(从下往上)代码:


从下往上的归并排序的思想正好与"从下往上的归并排序"相反。如下图:
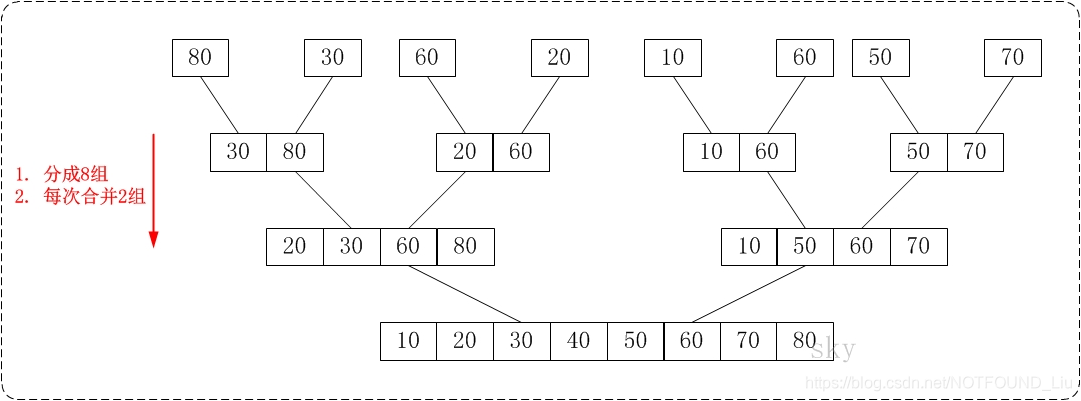
通过"从下往上的归并排序"来对数
组{80,30,60,40,20,10,50,70}进行排序时:
- 将数组{80,30,60,40,20,10,50,70}看作由8
个有序的子数
组{80},{30},{60},{40},{20},{10},{50}和{70}组成。 - 将这8个有序的子数列两两合并。得到4
个有序的子树列{30,80},{40,60},{10,20}和{50,70}。 - 将这4个有序的子数列两两合并。得到2
个有序的子树列{30,40,60,80}和{10,20,50,70}。 - 将这2个有序的子数列两两合并。得到1个有
序的子树列{10,20,30,40,50,60,70,80}。
4.桶排序介绍
桶排序(Bucket Sort)的原理很简单,它是将数组分到有限数量的桶子里。
假设待排序的数组a中共有N个整数,并且已知数组a中数据的范围[0, MAX)。在桶排时,创建容量为MAX的桶数组r,并将桶数组元素都初始化为0;将容量为MAX的桶数组中的每一个单元都看作一个"桶"。
在排序时,逐个遍历数组a,将数组a的值,作为"桶数组r"的下标。当a中数据被读取时,就将桶的值加1。例如,读取到数组a[3]=5,则将r[5]的值+1。

bucketSort(a, n, max)是作用是对数组a进行桶排序,n是数组a的长度,max是数组中最大元素所属的范围[0,max)。
假设a={8,2,3,4,3,6,6,3,9}, max=10。此时,将数组a的所有数据都放到需要为0-9的桶中。如下图:
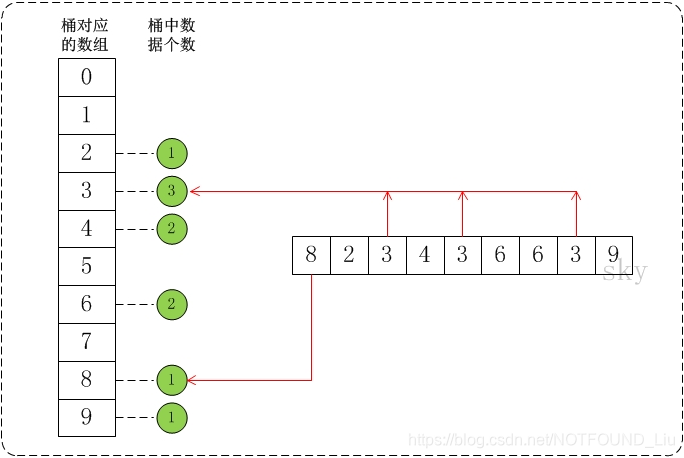
在将数据放到桶中之后,再通过一定的算法,将桶中的数据提出出来并转换成有序数组。就得到我们想要的结果了。
5.基数排序介绍
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序图文说明
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:
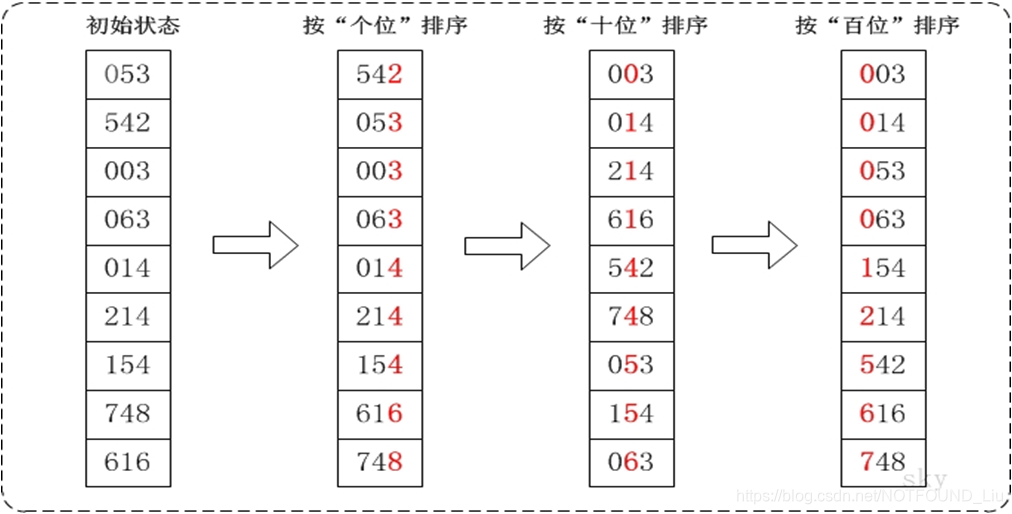



radix_sort(a, n)的作用是对数组a进行排序。
- 首先通过get_max(a)获取数组a中的最大值。获取最大值的目的是计算出数组a的最大指数。
- 获取到数组a中的最大指数之后,再从指数1开始,根据位数对数组a中的元素进行排序。排序的时候采用了桶排序。
- count_sort(a, n, exp)的作用是对数组a按照指数exp进行排序。
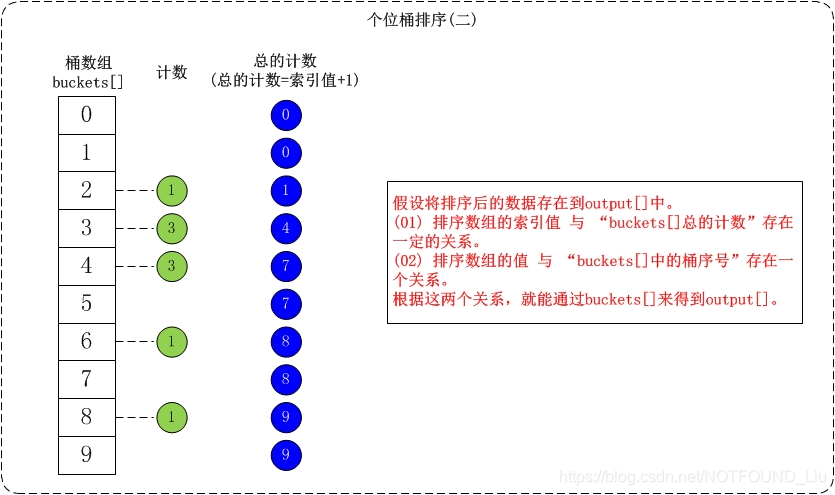
下面简单介绍一下对数组{53, 3, 542, 748, 14, 214, 154, 63, 616}按个位数进行排序的流程。
(01) 个位的数值范围是[0,10)。因此,参见桶数组buckets[],将数组按照个位数值添加到桶中。
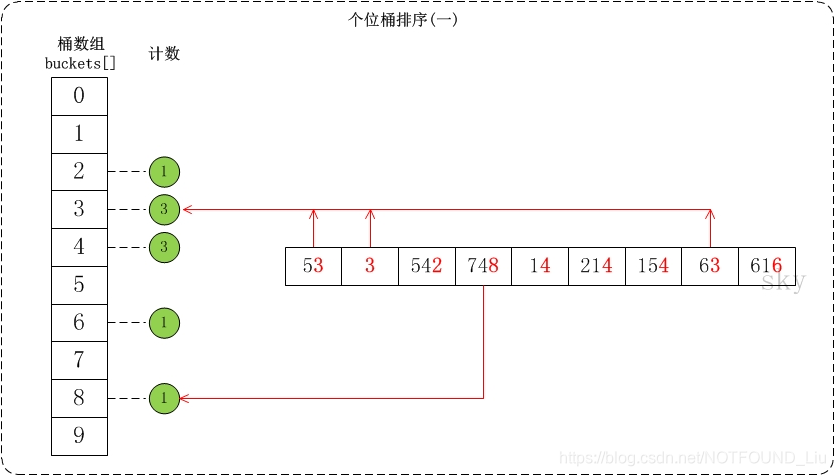
• (02) 接着是根据桶数组buckets[]来进行排序。假设将排序后的数组存在output[]中;找出output[]和buckets[]之间的联系就可以对数据进行排序了。