JDBC&爬虫入门
一、JDBC
1、什么是JDBC?
Java DataBase Connectivity,一种用于执行SQL语句的Java API
这次培训只演示Java执行mysql语句
2、首先了解一些mysql指令
(1)创建数据库
create database esta;//esta是数据库名
(2)删除数据库
drop database esta;
(3)使用该数据库
use esta;
(4)显示数据库中的表
show tables;
(5)删除表
drop table student;//student是表名
(6)创建表
create table student(
id int auto_increment primary key,//自动加编号的主键
name varchar(50), //varchar表示可变长度,存入数据是几个字节大小就占用几个字节大小,但超过设置的值时会被截断
sex char(20), //char(T)表示不可变长度,每个值都占用T个字节,如果长度小于T,mysql就会在它的右边以空格字符补足.
birthday varchar(50)
)default charset=utf8; //设置默认编码为utf-8
(7)插入数据
insert into student values(null,‘esta’,‘女’,’2000-10-2’);
(8)查询表中的数据
select * from student;//*表示选择所有
select id,name from student;//表示只选取id、name两列
(9)修改某一条数据
update student set sex='男' where id=1;//将主键为1的数据中的sex改为'男'
(10)删除数据
delete from student where id=1;//删除主键为1的这条记录
3、尝试使用命令行执行mysql指令
(1)打开上次培训时安装的xampp
(2)开启mysql服务(点击mysql对应的start)
(3)点击shell打开命令行
(4)输入命令:mysql -u root -p回车之后会让你输入密码,如果没有密码的话直接回车即可
(5)现在就可以开始运行2中的mysql命令了,实践一波。
4、用Java代码来替代命令行中对mysql的操作
(1)、开启数据库
先进行3中的(1)与(2)步,将数据库服务打开。
(2)、下载并解压jar包
官方下载链接:https://dev.mysql.com/downloads/connector/j/

(3)、导入jar包

(4)、编写代码
package ESTA;
import java.sql.*;
import com.mysql.jdbc.PreparedStatement;
public class esta_conncet {
public static void main(String[] args){
//连接对象
Connection conn;
//驱动
String driver = "com.mysql.jdbc.Driver";
//jdbc:mysql://localhost:3306/esta 为数据库eata的地址
//?useUnicode=true&characterEncoding=utf8加上这个防止汉字乱码
String addr = "jdbc:mysql://localhost:3306/esta?useUnicode=true&characterEncoding=utf8";
//用户名
String username ="root";
//密码
String password = "";
try{
//加载驱动
Class.forName(driver);
//建立连接
conn = DriverManager.getConnection(addr, username, password);
//判断是否连接
if(!conn.isClosed()){
System.out.println("连接成功");
}
Statement state = conn.createStatement();
//创建表,sql为在数据库中创建表的命令语句,与2中的语句完全相同,不过因为字符串过长,用+连接
String sql = "create table student("
+"id int auto_increment primary key,"
+"name varchar(50),"
+"sex varchar(20),"
+"birthday varchar(30)"
+")default charset=utf8;";
//state.executeLargeUpdate()方法用于运行mysql命令,如果成功即返回0
if(state.executeLargeUpdate(sql)==0){
System.out.println("创建成功");
}
//到这里为止,就已经在名为esta的数据库中创建了一个名为student的表
//上面创建表时使用Statement对象来操作数据库,但Statement实现传参较为麻烦
//并且速度效率和安全方面也不及Preparedstatement,
//初学测试的时候可以用statement,但是以后使用尽量用PrepareStatement
//Preparedstatement利用?(占位符)传参,下面插入数据使用Preparedstatement演示
//PreparedStatement.setString(int arg0, String arg1)用于将占位符补齐,从而实现传参
//arg0表示占位符的索引,表示要将占位符替换掉的参数
String name = "esta";
String sex = "male";
String birthday = "2000";
PreparedStatement pst = (PreparedStatement) conn.prepareStatement("insert into student values(null,?,?,?);");//获得一个PreparedStatement对象,并传入sql语句
pst.setString(1, name);//占位符索引从1开始,用name替换第一个占位符
pst.setString(2, sex);//用sex替换第二个占位符
pst.setString(3, birthday);//用birthday替换第三个占位符
pst.executeUpdate();//执行语句
//到这里为止,就在student表中插入了一组数据(记录),尝试从从表中将这组数据提取出来
//下面这个语句也与2中的插入语句一样
//相信你们看到这里,已经知道jdbc事实上就是用Java来执行sql的命令,命令一模一样
String sql_1 = "select * from student";//这条命令表示获取student表中的所有记录
ResultSet rs = state.executeQuery(sql_1);//执行上面的命令,并将结果存入一个结果集中
while(rs.next()){ //遍历所有记录
System.out.print(rs.getInt("id")+" ");
System.out.print(rs.getString("name")+" ");
System.out.print(rs.getString("sex")+" ");
System.out.println(rs.getString("birthday"));
}
pst.close();//使用完数据库一定要记得关闭连接
state.close();
conn.close();
} catch (Exception e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
二、爬虫入门
1、安装python及pycharm
python下载地址:https://www.python.org/ftp/python/3.6.5/python-3.6.5.exe
安装时勾选 Add Python 3.6 to PATH

Pycharm下载地址:https://www.jetbrains.com/pycharm/download/#section=windows
2、打开pycharm新建工程
3、导入相关库
requests库用于爬取 beautifulsoup用于解析
可以开启cmd,输入pip install [名称]下载导入 如:pip install requests
也可以在pycharm中点击File -> Setting ->Project:[工程名] -> Project Interpreter -> +号
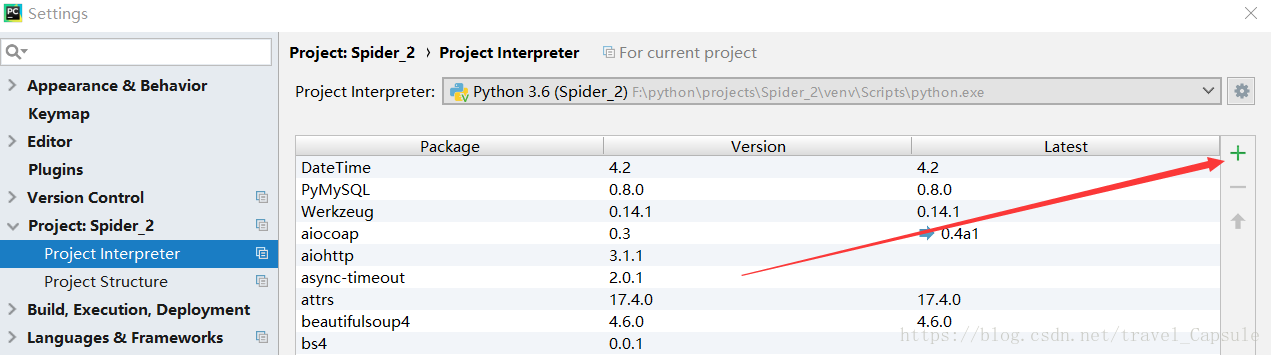
搜索需要的库

点击 Install Package

4、获取必要的一些东西
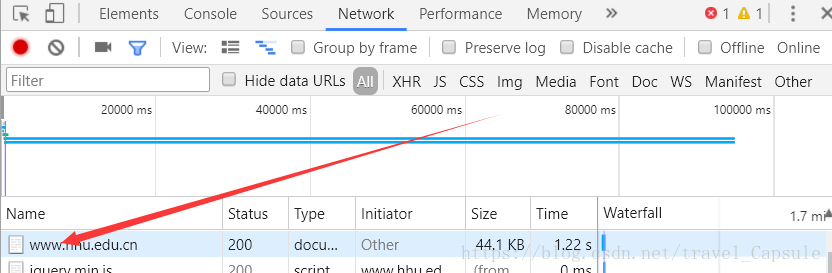
尝试爬取河海大学官网主页面源代码,在写代码前,应该先观察一下要爬取网站的结构,打开要爬取的网站,快捷键Fn+F12(或win+F12)打开查看审查元素工具,点击Network

按F5刷新页面
点击Name这一列的第一个
在这里可以看到浏览器对网站进行访问时的headers,也就是浏览器的头,有了这个,网站服务器会在一定程度上把你的爬虫当成是浏览器。
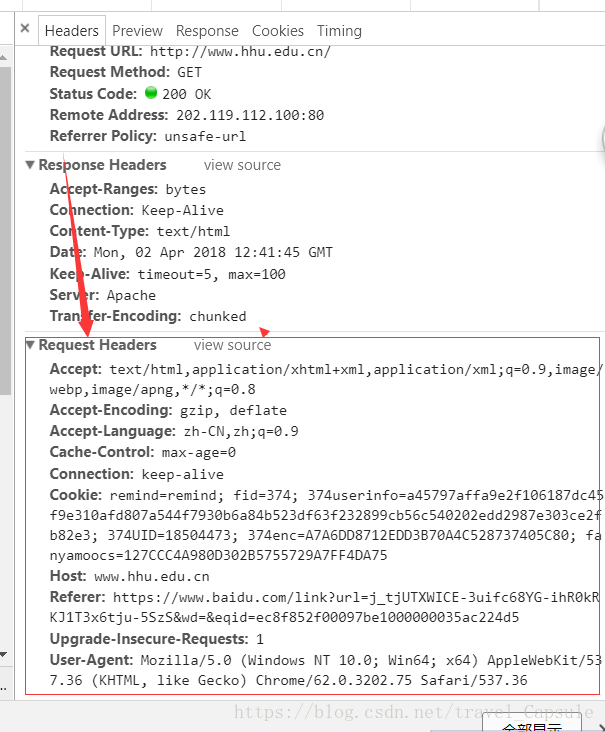
拷贝Request Headers。
5、编写代码
右击pycharm中已建立的工程的Scripts文件夹,点击New ——> Python File ——>输入文件名,确定
import requests
from bs4 import BeautifulSoup
class spider(object):#创建一个spider类
def __init__(self):#相当于Java中的构造函数
self.headers = { #浏览器头,就是刚刚拷贝下来的,以键值对形式规范好,与Java中的map相似,在python中成为字典
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host":"www.hhu.edu.cn",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36"
}
def get_html(self,url):#创建一个爬起函数
html = requests.get(url,headers=self.headers).text#爬取
print(html)
if __name__ == '__main__':
spider = spider().get_html("http://www.hhu.edu.cn/")因为时间关系,只是将获取到的html源代码输出了,没有演示BeautifulSoup的解析效果,ppt中提到的利用selenium实现自动登录的代码也没有演示,大家如果有兴趣的话可以随时找我们交流 [email protected]