“
一提到房价,就“压力山大”!无论是首套房还是改善性需求,买在低点卖在高点都是一个可遇不可求的事儿,所以如果有位数据大侠能帮助设计一个预测房价的神器,岂不是“人生很值得”!本期DT数据侠与纽约数据科学学院合作的数据线专栏中,四位数据侠通过“数据超能力”试图利用Python通过机器学习方式来预测房价,快来看看他们是如何做得吧!

如果让你全凭直觉来判断,上图里的四个房子哪个最贵?
(也许)大多数人会说是右边的蓝色房子,因为它看起来最大也最新。然而,当你看完今天这篇文章,你可能会有不同的答案,并且发现一种更准确的预测房屋价格的方法。
这个项目的数据集可以在kaggle页面(https://www.kaggle.com/c/house-prices-advanced-regression-techniques)找到:这些数据被分为两类,训练集和测试集。
关注微信公众号:程序员交流互动平台!获取资料学习!
数据列表一共有2600行、79列,包括了不同房屋的描述性数据,比如卧室数、一层的房屋面积等。训练集里还包括了房屋的真实价格数据。
▍因变量
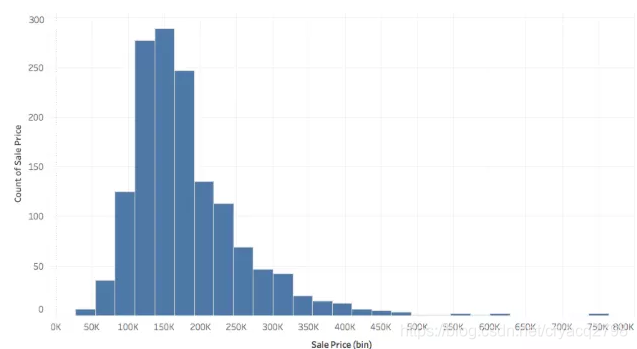
房屋价格总体来看,是一个平均值和中位数在20万美元左右的向右倾斜的分布,最高的价格在55万到75万之间。

▍自变量
类别变量(Categorical Variables )

大多数(79种变量中有51种)是定性变量(categorical),包括房子所在社区、整体质量、房屋类型等。最好预测的变量是与质量相关的变量。比如,整体质量这个变量最终证明是预测价格的最关键因素。房子某一个部分的质量,比如泳池、地下室等,也都与最终价格有很强的相关性。
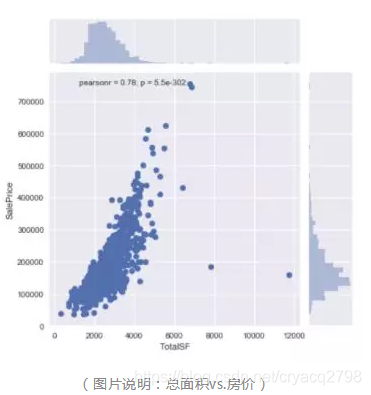
数字变量(numeric variables)
数字变量大多是关于房屋面积。它们也与价格相关。

▍缺失的数据

过程中的一大挑战是那些缺失的数据,对于像泳池质量、泳池面积等数据,如果数据缺失了,则说明这栋房子没有泳池,我们会用0来代替,如果是定性变量,则用“无”来代替。对于那些“意外缺失”的数据,我们则通过其他变量进行估算,补充进去。

▍特征工程
处理一大堆不清晰的特征总是充满挑战。下面我们要创造和抛弃一些变量,并引入一些哑变量等。
抛弃变量
通常人们会删除一些相互高度关联的特征。在我们的分析中,我发现车库建造年份和房屋建造年份关联度很强,关联值达到0.83。而且75.8%以上的情况下,这两个值是相同的。因此,我们决定把有很多缺失的车库年份数据丢掉。
创造新的变量
有时候需要创造新的变量从而提升整个模型的表现,我们设计了两个新变量:
1. 卖掉时的房龄
2. 卖掉时距重新装修过去多少年
▍处理变量
1. 我们找出11个定性变量,它们存在某种排序的可能,可以分别将它们划分为很棒、一般和很差;
2. 对于其他的定性变量,我们使用pandas.get_dummies来得到独热编码(One-Hot Encoding);
关注微信公众号:程序员交流互动平台!获取资料学习!
3. 我们找到24个连续数据变量,它们的斜率大于0.75(向右倾斜),我们使用对数变换来去掉本身的偏态。

▍正则化(regularization)
因为我们需要处理很多变量,所以我们引入了正则化的操作,来处理在过程中发现的那些多重共线性关系,以及使用多元线性回归模型可能带来的过度拟合问题。
正则化最棒的地方在于它能减少模型的复杂性,因为它能自动地为你完成特征挑选的任务。所有正则化模型都会惩罚多余的特征。
正则化的模型包括 Lasso、Ridge 模型和弹性网络(Elastic Net)。Lasso 算法(最小绝对值收敛和选择算法)会将系数设为0,而ridge回归模型会最小化系数,使其中的一些非常接近0。弹性网络模型是Lasso和Ridge的混合。它将彼此相关的变量分到同一组,如果里面有一个变量是个很强的预测变量(predictor),那么整个组都会被纳入这个模型。
下一步是将每个模型的超参数进行交叉验证。
我们将Lasso模型的阿尔法定为 = .0005,Ridge的阿尔法为2.8 。弹性网络模型的阿尔法为 .0005 , L1_Ratio = 0.9。因为当 L1_Ratio = 0.9 时,弹性网络模型十分接近 Lasso模型,后者有默认的 L1_Ratio = 1 。

▍特征选择

Lasso模型
对房屋价格的正算子系数:地上生活空间、整体房子状况以及Stone Bridge、North Ridge 和 Crawford社区。
负算子系数:MS Zoing、Edwards 社区和地上厨房。
Ridge模型
对房屋价格的正算子系数:整体住宅面积、房顶材料(木瓦)、整体状况。
负算子系数:一般的分区需求、离主干道或铁路的距离,以及游泳池状况良好。
▍训练数据中模型预测的价格和真实价格的对比
下面两图展示了我们的模型的精确度。离红线近的以及在红线上面的是我们预测准确的,那些偏离的比价多的需要我们进一步研究。

▍梯度提升回归(Gradient boosting regression)
梯度提升回归是我们表现最好的一个算法。我们最初使用全部特征(基准模型)来训练梯度提升机。我使用 scikit-learn这个Python包提供的 GridSearchCV 功能来进行参数调整的交叉验证。我们最好的模型参数是:学习值0.05,估计量2000,最大深度3。
我们制作了一个相对重要性表格,将梯度提升特征的重要性用可视化的方式呈现。特征重要性分数代表每个特征在构建这个加强版的决策树里是否有用。地上生活空间面积、厨房质量、地下室面积以及车库大小是最重要的特征。

▍PCA(主成分分析 )+ 梯度提升回归
我们接下来尝试通过减少特征的维度来提高我们基准模型的表现。高维度的数据可能很分散,就会让使用某种算法来训练有用的模型变得更难。总的来说,最优的、非多余的特征子集会对预测性的算法有好处,能够提高训练率以及加强它的可解释性和一般性。
我们使用 scikit-learn 的 Pipelines 来管理我们的机器学习模型,它允许我们通过应用一个估计量来完成一系列数据的转化工作。
在这里我还是要推荐下我自己建的大数据学习交流裙:805127855, 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。
我们设计了不同的pipeline,每一个有不同的估计量。对于梯度提升回归,我们的pipelin包括:
1. 特征缩放,使用了scikit-learn 的python包
2. 降维,使用PCA(留下了150个主要的成分)
我们完成了特征工程后,得到200个特征和大约1500行训练数据集。在看过累积方差的百分比的表格后,我们决定留下150个核心元素。

并不是所有调整都能优化结果。在我们用PCA操作后,交叉验证的分数并没有提高,甚至恶化了(从0.91降到了0.87)。我们相信是降维时,也去掉了一些关键信息。PCA 不仅去掉了随机出现的噪音,也去掉了有价值的信息。
▍PCA + 多元线性回归
对于多元线性回归,我们的pipeline 包括:
1. 特征缩放,使用了scikit-learn 的python包
2. 降维,使用PCA(留下了150个主要的成分)
使用多元线性回归的PCA 也没有带来好的结果。交叉验证的分数并没有提高,甚至恶化了。
▍模型比较
XG Boost 是表现最好的模型,多元线性回归表现最差,其他模型的结果差不多。

使用单独某一个模型都能让我们得到不错的结果。但是,通常来说,真实生活中的问题并没有一种线性或者非线性的关系,可以让我们用一个单独的模型来重现。把保守和激进、线性和非线性的模型结合起来,才能最好地呈现房价预测这个问题。
▍融合(stacking 和 ensembling)
我们先尝试了一个简单的合模型(ensembling),以50-50的比例将 XGBoost(非线性)和ENet(线性)组合在一起。
接下来,我们按照模型融合(stacking)的基本方法,又尝试了多个不同模型,来看哪个效果最好。下图记录了这些不同模型的表现情况。

▍结论
下面的相关性热点图展示了我们不同模型的预测价格。可以看到,弹性网络、Lasso和Ridge本质上很相似,而两种融合方式也彼此很像。与其他都明显不同的是 XGBoost 模型

▍未来可研究方向
1. 研究自变量之间的相关性
2. 尝试更多的特征工程
3. 使用聚类分析来创造更多新的特征
4. 对不同模型使用不同的特征选择方法:在线性模型中抛弃掉特定的特征,而在树形模型中保持大多数的特征。
在这里我还是要推荐下我自己建的大数据学习交流裙:805127855, 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。