版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/83997402
1 用户行为日志介绍
1.1 行为日志生成方法
- Nginx
- Ajax
1.2 日志内容
- 访问的系统属性:操作系统、浏览器
- 访问特征:点击的 url、从哪个url 跳转过来的(referer)、页面停留时间
- 访问信息: session_id, 访问ip,
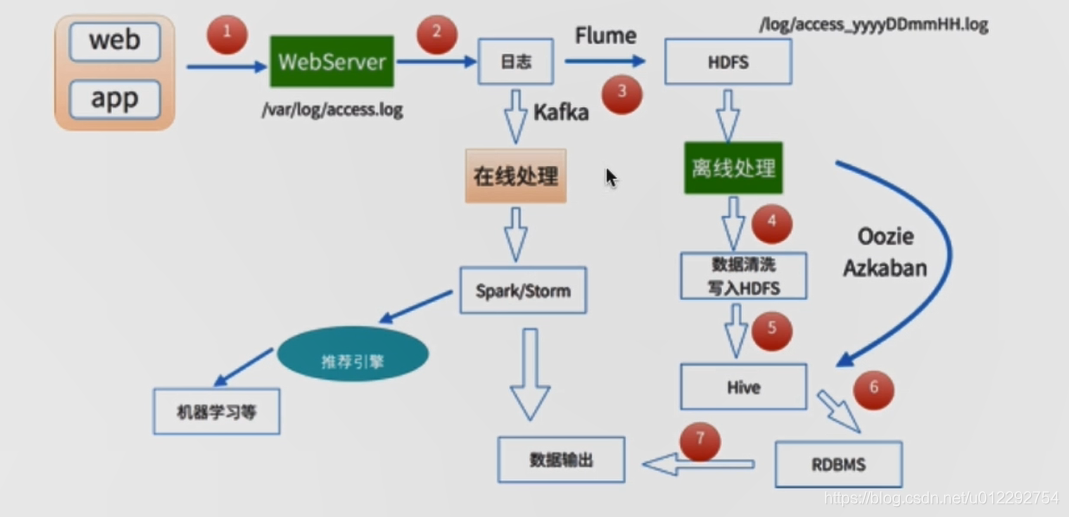
2 离线数据处理架构
- 数据采集: Flume: web日志写入到 HDFS
- 数据清洗:Spark,hive,mapreduce,清洗后可以存放到HDFS
- 数据处理:按照需求进行相应的业务统计分析
- 处理结果入库:存放到 RDBMS,NoSQL
- 数据可视化:Echarts,HUE, Zeppelin
3 需求
- 主站最受欢迎的课程/手记 Top N访问次数;
- 按照地市统计最受欢迎的 Top N 课程;
- 根据IP地址提取出城市信息;
- 窗口函数在 Spark SQL 中的使用;
- 按照流量统计最受欢迎的 Top N;
4 原始日志清洗
原始记录案例
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.imooc.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
截取前 20000 条数据
$ head -20000 access.20161111.log >> access_20000.log
4.1 第一次清洗
打断点


4.2 源码
DateUtils.scala
package com.weblog.cn
import java.util.{Date, Locale}
import org.apache.commons.lang3.time.FastDateFormat
/*
* 日期时间解析类
* */
object DateUtils {
/*
* SimpleDateFormat 是线程不安全的
* */
//输入文件时间格式 [10/Nov/2016:00:01:02 +0800]
val YYYYMMDDHHMM_TIME_FORMAT = FastDateFormat.getInstance("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
//输出时间格式
val TARGET_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
// 获取时间 yyyy-MM-dd HH:mm:ss
def parse(time: String) = {
TARGET_FORMAT.format(new Date(getTime(time)))
}
//获取驶入日志时间 : long 类型
//time : [10/Nov/2016:00:01:02 +0800]
def getTime(time: String) = {
try{
YYYYMMDDHHMM_TIME_FORMAT.parse(time.substring(time.indexOf("[")+1,
time.lastIndexOf("]"))).getTime
}catch {
case e:Exception => {
0l
}
}
}
/* def main(args: Array[String]): Unit = {
println(parse("[10/Nov/2016:00:01:02 +0800]"))
}
*/
}
SparkStatFormatJob.scala
package com.weblog.cn
import org.apache.spark.sql.SparkSession
/*
*
* */
object SparkStatFormatJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName(" SparkStatFormatJobApp")
.master("local[2]").getOrCreate()
val access = spark.sparkContext.textFile("file:///d://access_20000.log")
//access.take(10).foreach(println)
/*access.map(line =>{
val splits = line.split(" ")
val ip = splits(0)
ip
}).take(10).foreach(println)*/
/*access.map(line =>{
val splits = line.split(" ")
val ip = splits(0)
//[10/Nov/2016:00:01:02 +0800]
val time = splits(3)+" "+splits(4)
val url = splits(11).replaceAll("\"","")
//流量
val traffic = splits(9)
(ip,DateUtils.parse(time),url,traffic)
}).take(10).foreach(println)*/
access.map(line => {
val splits = line.split(" ")
val ip = splits(0)
//[10/Nov/2016:00:01:02 +0800]
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"", "")
//流量
val traffic = splits(9)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).saveAsTextFile("file:///d://weblog")
}
}
结果
2016-11-10 00:01:02 - 813 183.162.52.7
2016-11-10 00:01:02 - 0 10.100.0.1
2016-11-10 00:01:02 http://www.imooc.com/code/1852 2345 117.35.88.11
2016-11-10 00:01:02 - 94 182.106.215.93
2016-11-10 00:01:02 - 0 10.100.0.1
2016-11-10 00:01:02 - 19501 183.162.52.7
2016-11-10 00:01:02 - 0 10.100.0.1
2016-11-10 00:01:02 - 2510 114.248.161.26
2016-11-10 00:01:02 - 633 120.52.94.105
2016-11-10 00:01:02 - 0 10.100.0.1
2016-11-10 00:01:02 - 94 112.10.136.45
2016-11-10 00:01:02 http://www.imooc.com/code/2053 331 211.162.33.31
2016-11-10 00:01:02 http://www.imooc.com/code/3500 54 116.22.196.70
2016-11-10 00:01:02 - 0 10.100.0.1
2016-11-10 00:01:02 - 125 113.47.86.12
2016-11-10 00:01:02 http://www.imooc.com/code/547 54 119.130.229.90
4.2 第二次清洗
- 使用 Spark SQL 解析访问日志
- 解析出课程编号、类型
- 根据IP解析出城市信息
https://github.com/wzhe06/ipdatabase - 使用 Spark SQL 将访问时间按天进行分区输出
第一次清洗的结果
2017-05-11 14:09:14 http://www.imooc.com/video/4500 304 218.75.35.226
2017-05-11 15:25:05 http://www.imooc.com/video/14623 69 202.96.134.133
2017-05-11 07:50:01 http://www.imooc.com/article/17894 115 202.96.134.133
2017-05-11 02:46:43 http://www.imooc.com/article/17896 804 218.75.35.226
2017-05-11 09:30:25 http://www.imooc.com/article/17893 893 222.129.235.182
2017-05-11 08:07:35 http://www.imooc.com/article/17891 407 218.75.35.226
2017-05-11 19:08:13 http://www.imooc.com/article/17897 78 202.96.134.133
4.3 使用 github 开源项目获取城市
https://github.com/wzhe06/ipdatabase
4.3.1 下载后解压,然后编译
4.3.2 安装 jar 包到自己的Maven仓库
mvn install:install-file -Dfile=d://ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar

4.3.3 修改 pom 文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tzb.demo2</groupId>
<artifactId>SQLContext</artifactId>
<version>1.0</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.0</spark.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.ggstar</groupId>
<artifactId>ipdatabase</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
4.3.4 测试ip地址解析
package com.weblog.cn
import com.ggstar.util.ip.IpHelper
/*
* ip 解析工具类
* */
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}
def main(args: Array[String]): Unit = {
println(getCity("58.30.15.255"))
}
}
4.3.5 修改 AccessConvertUtil.scala
val city = IpUtils.getCity(ip)
4.4 数据清洗结果存储到目标文件
调优点,控制文件输出的大小 coalesce
SparkStatCleanJob.scala
object SparkStatCleanJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkStatCleanJobApp")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("file:///d://access.log")
//accessRDD.take(10).foreach(println)
//RDD -> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("d://weblog_clean")
spark.stop()
}
}
