笔记目录:
目录
一、用户行为日志
1.日志介绍
用户每次访问网站时所有行为数据(访问、浏览、点击、搜索....)用户行为轨迹、流量日志
2.日志数据内容
1)访问的系统属性:操作系统、浏览器等等
2)访问特征:点击url、从哪个url跳转过来的(referer)、页面上停留的时间等....
3)访问信息:session_id、访问ip(访问城市)等
二、数据处理流程
1、数据采集
- Flume:web日志写入到HDFS
2、数据清洗
- 脏数据处理
- 可以使用Spark、Hive、MapReduce
- 清洗完之后数据可以放在HDFS
3、数据处理
- 按照需求进行业务统计和分析
- 使用Spark、Hive、MapReduce或者其他分布式计算框架
4、处理结果入库
- 结果存放在RDBMS、NoSQL
5、数据可视化
- 通过图形化展示的方式展现出来:饼图、折线图等
- 使用ECharts、HUE等
【离线数据处理架构流程图】 
三、项目需求
- 需求一:统计慕课网最受欢迎的课程/手记的Top N访问次数
- 需求二:按地市统计慕课网最受欢迎的的Top N课程
- 根据ip地址提取城市信息
- 窗口函数在Spark SQL的使用
- 需求三:按流量统计慕课网最受欢迎的的Top N课程
四、数据清洗
- 使用Spark SQL解析日志
- 解析出课程编号、类型
- 根据ip解析出城市信息
- 使用Spark SQL将访问时间按天进行分区输出
- 一般处的日志处理方式,我们需要分区的
- 安装日志中的访问时间进行相应的的分区,比如:d(天),h(小时),m5(每五分钟一个分区)
- 输入:访问时间、访问URL、耗费的流量、访问ip地址信息
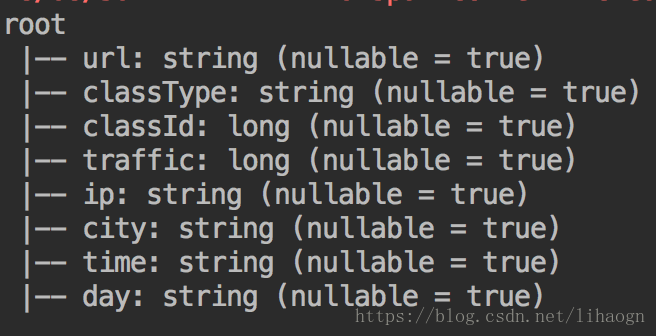
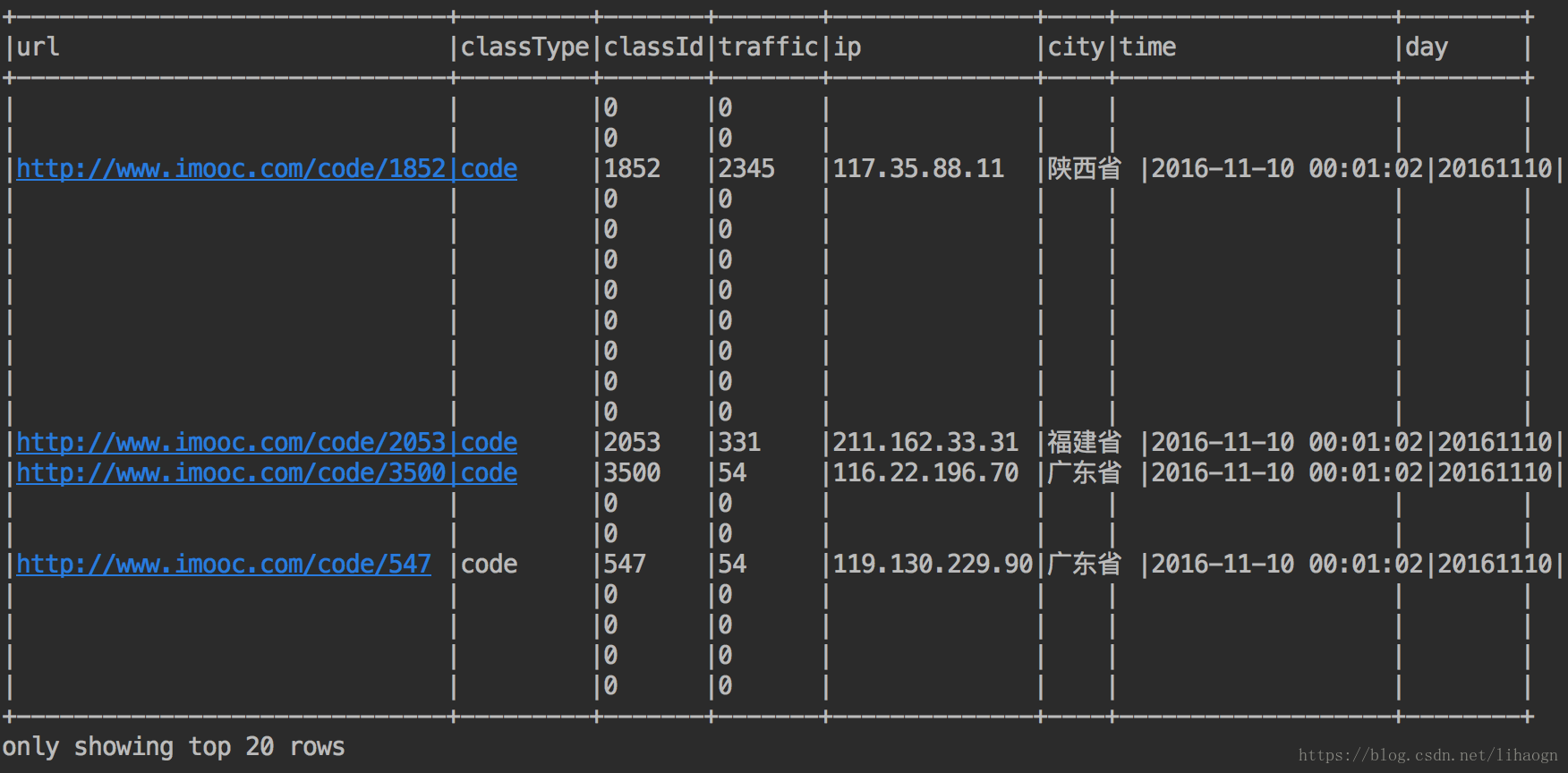
- 输出:URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
五、数据清洗代码实现
原始日志:
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.imooc.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000
117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] "GET /article/ajaxcourserecommends?id=124 HTTP/1.1" 200 2345 "www.imooc.com" "http://www.imooc.com/code/1852" - "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36" "-" 10.100.136.65:80 200 0.616 0.616
182.106.215.93 - - [10/Nov/2016:00:01:02 +0800] "POST /socket.io/1/ HTTP/1.1" 200 94 "chat.mukewang.com" "-" - "android-websockets-2.0" "-" 10.100.15.239:80 200 0.004 0.004
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/userdynamic HTTP/1.1" 200 19501 "www.imooc.com" "-" cid=0×tamp=1478707261847&uid=2871142&touid=2871142&page=1&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=3837a5bf27ea718fe18bda6c53fbbc14 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.136.65:80 200 0.195 0.195
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000
114.248.161.26 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getcourseintro HTTP/1.1" 200 2510 "www.imooc.com" "-" cid=283&secrect=86b720f312c2b25da3b20e59e7c89780×tamp=1478707261951&token=4c144b3f4314178b9527d1e91ecc0fac&uid=3372975 "mukewang/5.0.2 (iPhone; iOS 8.4.1; Scale/2.00)" "-" 10.100.136.65:80 200 0.007 0.0081、第一次清洗:格式化原始日志数据
SparkStatFormatJob.scala
package log
import org.apache.spark.sql.SparkSession
/**
* 第一步数据清洗:抽取需要的指定列的数据
*/
object SparkStatFormatJob {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("SparkStatFormatJob").master("local[2]").getOrCreate()
// 获取文件
val access=spark.sparkContext.textFile("/Users/Mac/testdata/10000_access.log")
access.map(line=>{
val splits=line.split(" ")
val ip=splits(0)
/**
* 获取日志中完整的访问时间
* 并转换日期格式
*/
val time=splits(3)+" "+splits(4)
val url=splits(11).replaceAll("\"","")
val traffic=splits(9)
DateUtils.parse(time)+"\t"+url+"\t"+traffic+"\t"+ip
}).saveAsTextFile("/Users/Mac/testdata/spark-output/")
spark.stop()
}
}
读取文件的debug效果图:

DateUtils.scala
package log
import java.util.{Date, Locale}
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期时间解析工具类
*/
object DateUtils {
// 输入文件日期时间格式
val SOURCE_TIME_FORMAT = FastDateFormat.getInstance("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
// 目标日期格式
val TARGET_TIME_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
/**
* 获取时间
*/
def parse(time: String) = {
TARGET_TIME_FORMAT.format(new Date(getTime(time)))
}
/**
* 获取输入日志时间
*/
def getTime(time: String) = {
try {
SOURCE_TIME_FORMAT.parse(time.substring(time.indexOf("[") + 1, time.lastIndexOf("]"))).getTime
} catch {
case e: Exception => {
0l
}
}
}
def main(args: Array[String]): Unit = {
println(parse("[10/Nov/2016:00:01:02 +0800]"))
}
}
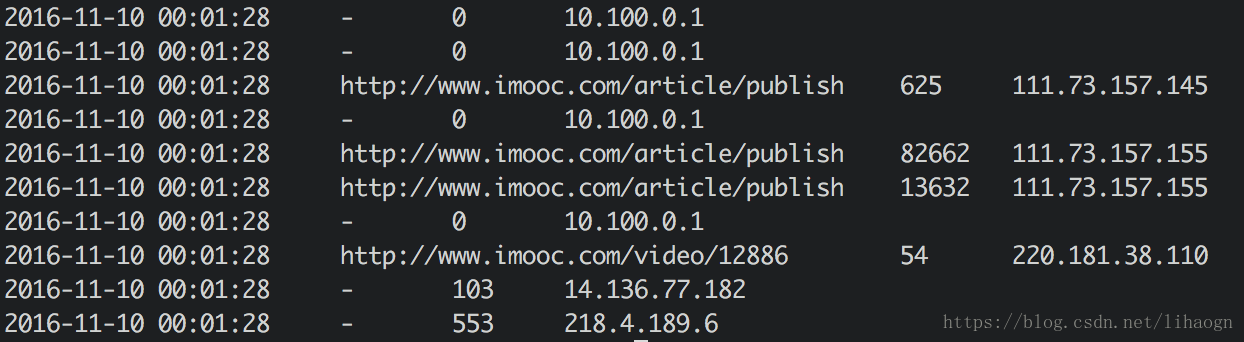
清洗完的部分数据:
2、二次清洗:日志解析
输入:访问时间、访问URL、耗费的流量、访问的IP地址信息
输出:URL,课程类型,课程编号,流量,IP,城市信息,访问时间,天
需要使用第三方包:ipdatabase
安装ipdatabase介绍:IP地址解析之github中ipdatabase项目的使用
IpUtils.scala
package log
import com.ggstar.util.ip.IpHelper
/**
* ip解析工具类
*/
object IpUtils {
def getCity(ip:String)={
IpHelper.findRegionByIp(ip)
}
def main(args: Array[String]): Unit = {
println(getCity("218.75.35.226"))
}
}
AccessConvertUtil.scala
package log
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
/**
* 日志数据转换(输入==>输出)工具类
*/
object AccessConvertUtil {
// 定义输出字段
val struct = StructType(
Array(
StructField("url", StringType),
StructField("classType", StringType),
StructField("classId", LongType),
StructField("traffic", LongType),
StructField("ip", StringType),
StructField("city", StringType),
StructField("time", StringType),
StructField("day", StringType)
)
)
/**
* 根据输入的每一行信息转换成输出的格式
*/
def parseLog(log: String) = {
try {
val splits = log.split("\t")
val url = splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/"
val className = url.substring(url.indexOf(domain) + domain.length)
val classTypeId = className.split("/")
var classType = ""
var classId = 0l
if (classTypeId.length > 1) {
classType = classTypeId(0)
if (classId.isInstanceOf[Long]){
classId = classTypeId(1).toLong
}else{
classId=0l
}
}
val city = IpUtils.getCity(ip)
val time = splits(0)
val day = time.substring(0, 10).replaceAll("-", "")
// row要和struct对应上
Row(url, classType, classId, traffic, ip, city, time, day)
} catch {
case e: Exception => Row("","",0l,0l,"","","","")
}
}
}
SparkStatCleanJob.scala
package log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用spark完成数据清洗
*/
object SparkStatCleanJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkStatCleanJob").master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("/Users/Mac/testdata/access.log")
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
// coalesce:设置输出文件的个数,默认3个
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/Users/Mac/testdata/log_clean/")
}
}