版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/84142787
1 Spark 的4种运行模式
不管使用寿命模式,Spark 应用程序的代码是不变的,只需要在提交的时候通过 --master参数来指定
- Local,开发时使用
- Standalone,Spark自带的,如果一个集群是 Standalone ,那么就需要在多台机器同时部署Spark环境;
- YARN:建议在生产中使用;
- Mesos
1.1 概述
- Spark 支持可插拔的集群管理模式;
- 对于YARN,Spark Application 仅仅是一个客户端;
1.2 Spark on YARN 的模式
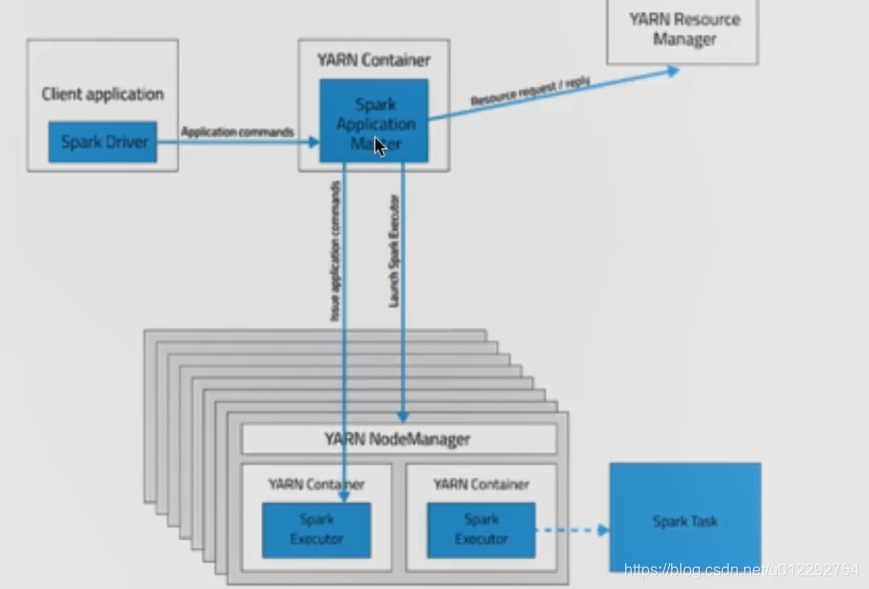
1.2.1 client 模式
- Driver 运行在 client 端(提交 Spark 作业的机器)
- Client 会和请求到的 Container 进行通信来完成作业的调度和执行,Client 不能退出;
- 日志在控制台输出,便于测试
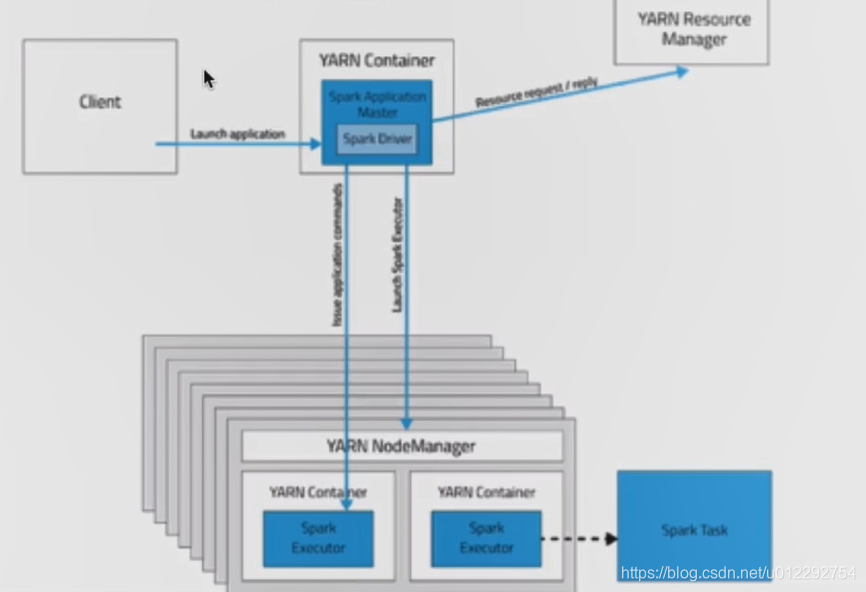
1.2.2 cluster 模式
- Driver 运行在 Application Master;
- Client 只要提交完作业之后就可以关掉,因为作业已经在 YARN 上运行
- 日志是在终端看不到的,因为日志在Driver上,只能通过
yarn logs -applicationId <app ID>
1.3 设置 HADOOP_CONF_DIR 或者 YARN_CONF_DIR
配置方法有以下几种:
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/etc/hadoop- spark-env.sh
1.4 测试
1.4.1 启动YARN
[hadoop@node1 ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
18/11/16 20:36:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [node1]
node1: starting namenode, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-namenode-node1.out
node2: starting datanode, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-node2.out
node3: starting datanode, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-node3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-secondarynamenode-node1.out
18/11/16 20:36:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-node1.out
node2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-node2.out
node3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-node3.out
[hadoop@node1 ~]$
http://node1:8088/cluster
1.4.2 提交
- client 模式
[hadoop@node1 spark-2.1.3-bin-2.6.0-cdh5.7.0]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --executor-memory 1G \
> --num-executors 1 \
> ./examples/jars/spark-examples_2.11-2.1.3.jar \
> 5
18/11/16 20:49:35 INFO spark.SparkContext: Running Spark version 2.1.3
18/11/16 20:49:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/11/16 20:49:36 INFO spark.SecurityManager: Changing view acls to: hadoop
18/11/16 20:49:36 INFO spark.SecurityManager: Changing modify acls to: hadoop
18/11/16 20:49:36 INFO spark.SecurityManager: Changing view acls groups to:
18/11/16 20:49:36 INFO spark.SecurityManager: Changing modify acls groups to:
- cluster 模式
[hadoop@node1 spark-2.1.3-bin-2.6.0-cdh5.7.0]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn-cluster \
> --executor-memory 1G \
> --num-executors 1 \
> ./examples/jars/spark-examples_2.11-2.1.3.jar \
> 5
Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
18/11/16 20:53:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/11/16 20:53:19 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.30.131:8032
18/11/16 20:53:19 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers
............................
18/11/16 20:53:38 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:39 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:40 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:41 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:42 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:43 INFO yarn.Client: Application report for application_1542371790854_0006 (state: RUNNING)
18/11/16 20:53:44 INFO yarn.Client: Application report for application_1542371790854_0006 (state: FINISHED)
18/11/16 20:53:44 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.30.133
ApplicationMaster RPC port: 0
queue: root.hadoop
start time: 1542372803673
final status: SUCCEEDED
tracking URL: http://node1:8088/proxy/application_1542371790854_0006/A
user: hadoop
18/11/16 20:53:44 INFO util.ShutdownHookManager: Shutdown hook called
18/11/16 20:53:44 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-619e92b6-4fb4-47ac-ab8f-4836ccf9d086
https://spark.apache.org/docs/2.1.3/running-on-yarn.html
[hadoop@node1 ~]$ yarn logs -applicationId application_1542371790854_0006
18/11/16 20:58:55 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.30.131:8032
18/11/16 20:58:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
/tmp/logs/hadoop/logs/application_1542371790854_0006does not exist.
Log aggregation has not completed or is not enabled.
[hadoop@node1 ~]$