Softmax 函数定义
Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量
“压缩”到另一个K维实向量中,使得每一个元素的范围都在之间,并且所有元素的和为1。
该函数的形式通常按下面的式子给出:
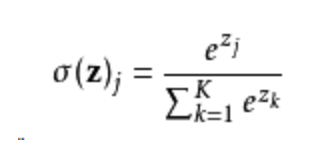
其中, j = 1, …, K
softmax 的python3实现(一维)
- array.sum(axis = 0),对array的每一列进行相加
- array.sum(axis =1),对array的每一行进行相加
- array.sum(),对array的全部元素进行相加
import numpy as np
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
#test example
scores = [3.0, 1.0, 0.2]
print(softmax(scores))
[ 0.8360188 0.11314284 0.05083836]- 为什么要减去max
为什么要对每一个x减去一个max值呢?从需求上来说,如果x的值没有限制的情况下,当x线性增长,e指数函数下的x就呈现指数增长,一个较大的x(比如1000)就会导致程序的数值溢出,导致程序error。所以需求上来说,如果能够将所有的x数值控制在0及0以下,则不会出现这样的情况,这也是为什么不用min而采用max的原因。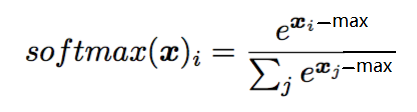
主要是数值稳定性方面的考虑 ,防止上溢出。
- 一维和二维矩阵的softmax
import numpy as np
def softmax(x):
orig_shape = x.shape
print("orig_shape",orig_shape)
if len(x.shape)>1:
# 矩阵
tmp = np.max(x,axis=1)
x -= tmp.reshape((x.shape[0],1))
x = np.exp(x)
tmp = np.sum(x,axis=1)
x /= tmp.reshape((x.shape[0],1))
print("matrix")
else:
# 向量
tmp = np.max(x)
x -= tmp
x = np.exp(x)
tmp = np.sum(x)
x /= tmp
print("vector")
return x
x = np.array([[1,2,3,4],[1,2,3,4]])
x1 = np.array([1,2,3,4])
print(x)
print(x1)
#
orig_shape (2, 4)
orig_shape (4,)
#
print(np.max(x,axis=1))
print(np.sum(x,axis=1))
#
[4 4]
[10 10]
#
print(softmax(x))
print(softmax(x1))
#
[[0.0320586 0.08714432 0.23688282 0.64391426]
[0.0320586 0.08714432 0.23688282 0.64391426]]
[0.0320586 0.08714432 0.23688282 0.64391426]
#https://blog.csdn.net/qq_30468133/article/details/84954050
https://blog.csdn.net/lrs1353281004/article/details/88532613
Softmax函数正确性证明
证明softmax不受输入的常数偏移影响,即
softmax(x)=softmax(x+c)
也就是证明加了偏移c之后,对整个softmax层的作用不起影响。如下:
参考:
今天学的一点,随便放进去了
- 为什么逻辑回归不能用平方误差做损失函数,而要用交叉熵函数?

- 为什么生成式要比判别式的准确率低?
以为生成式要自学,它在样本少的时候将明显是class1的样本误分到class2中。

- 多分类任务softmax如何计算分类结果?

- 逻辑回归的局限(由于boundary只是一条直线)

- 做了transformation之后就可以区分开了,但是难点在于往哪个方向做transformation,这一点要让机器自己学到,所以引入了由多个逻辑回归堆叠而成的“神经网络”!!!

