Background Introduction
This article provides an introduction to the training of the model for Chinese word vector. Compared to the reference tutorial about Word2Vec in the PaddlePaddle official document, this article makes following modification and improvement:
- This article re-implements the reader function. To deal with the new text data, you just need to modify the file path. But the official tutorial uses the encapsulated PTB dataset thereby unable to process the new data directly.
- This article provides a method to preprocess the Chinese text, enabling Chinese word segmentation, which is not necessary in the training of the model for English language.
It will facilitate your understanding of the Chinese language model if you read the following information before the model training section.
The difference between word vector training model and general neural network training model:
The training process for the general neural network model comes down to the solving of neural network parameters. However, for the word vector model, the training process not only solves the network parameters but also solves the word vector. In the iteration process, word vectors are initialized randomly and updated during iterative training. From this angle, word vectors also can be considered as part of the network parameters.
The difference between the training model for Chinese word vector and that for English word vector:
The former is different form the later. It requires preprocessing the text in the initial phase, in which the Chinese text needs to be segmented, and the performance of word segmentation will have a great influence on the training of word vector. There are many open source Chinese word segmentation libraries in Python. This article uses the jieba word segmentation library.
Model Overview
In this section, the N-gram model is employed to train the Chinese word vector. When training language models with n-grams, the first (N-1) words of an n- gram are used to predict the Nth word.
N-gram model principle:
The N-gram model is an important method in statistical language modeling. It assumes that the probability of the N-th word in a sentence depends on all N−1 words before it. The probability of the whole sentence is the product of the probability of occurrence of each word. These probabilities are obtained by counting the number of simultaneous occurrences of N words from the corpus.
N-gram model diagram:
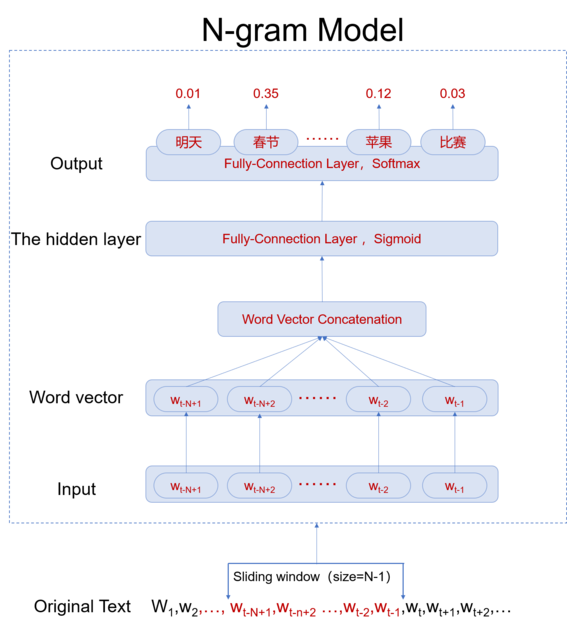
The figure shows the N-gram model is a shallow network model. From the top to the bottom, the model has the following levels:
Output Layer: The number of neurons in the output layer should be consistent with the number of words in the dictionary.
Hidden Layer: It is a fully-connection layer which is used for feature extraction. The dimensions can be freely defined.
Word Vector Concatenation: All the word vectors concatenate into a single vector.
Word Vector: The text data needs to be converted into a word vector before the processing by the computer.
Input layer: Each training sample is composed of N-1 words, and the corresponding Lable is the Nth word.
Original Text: The original text is processed with a sliding window (N-1) of a fixed size to obtain a training sample, ie, the first N-1 words are used to predict the Nth word.
1. Import packages.
import paddle.v2 as paddle import math
2. Implement Chinese word segmentation
Chinese word segmentation is a unique step in constructing a Chinese word vector. In order to ensure the reusability of subsequent code, it is coded as an independent jupyter notebook.
def chinese_word_segmentation(input_file,output_file,punctuations):
# This function is used to read a paragraph of Chinese text, and save the word split result in the specified file
# input_file:Text that needs to be processed, string
# output_file:The result file, string
# punctuations:Punctuation to be deleted during word segmentation
import sys
import jieba
import re
import codecs
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
f=codecs.open(input_file,'r',encoding="utf8")
target = codecs.open(output_file, 'w',encoding="utf8")
line_num=1
line = f.readline()
while line:
print('---- processing ', line_num, ' article----------------')
line=re.sub(r'[A-Za-z0-9]|/d+','',line)
line_seg = " ".join(jieba.cut(line))
testline=line_seg.split(' ')
te2=[]
for i in testline:
te2.append(i)
if i in punctuations:
te2.remove(i)
line_seg2 = " ".join(jieba.cut(''.join(te2)))
target.writelines(line_seg2)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
return
# Chinese word segmentation
from string import punctuation
raw_train_file='./word2vec/zhuxian_raw_train.txt'
raw_test_file='./word2vec/zhuxian_raw_test.txt'
train_file_name='./word2vec/train_zx.txt'
test_file_name='./word2vec/test_zx.txt'
add_punc=',。、【 】 “”:;()《》‘’{}?!⑦()、%^>℃:.”“^-——=&#@¥'
all_punc=punctuation+add_punc
chinese_word_segmentation(raw_train_file,train_file_name,all_punc)
chinese_word_segmentation(raw_test_file,test_file_name,all_punc)
3. Preprocess data.
To generate word vectors based on a Chinese text training, you need to preprocess the text before the model training. This section gives the definition of relevant processing functions. To handle the new text, you just need to do a little adaptation work.
3.1 Calculate word frequency
3.2 Build a dictionary
3.3 Implement the reader function
def word_count(file_name):
# This function reads in an English text or Chinese text that has been segmented and finally outputs the word frequency of each participle in the text in the form of a dictionary.
# file_name:Text that needs to be processed, string
# Output:dict
import collections
word_freq = collections.defaultdict(int)
with open(file_name) as f:
for l in f:
for w in l.strip().split():
word_freq[w] += 1
return word_freq
def build_dict(file_name, min_word_freq=50):
# This function reads in an English text or Chinese text that has been segmented, and finally returns a dictionary made up of word segments in the text.
# file_name:Text that needs to be processed, string
# min_word_freq:The minimum acceptable word frequency, int , the default is 50.
# Output:dict
word_freq = word_count(file_name)
word_freq = filter(lambda x: x[1] > min_word_freq, word_freq.items())
word_freq_sorted = sorted(word_freq, key=lambda x: (-x[1], x[0]))
words, _ = list(zip(*word_freq_sorted))
word_idx = dict(zip(words, xrange(len(words))))
word_idx['<unk>'] = len(words) #unk means unknown word
return word_idx
def reader_creator(file_name, word_idx, n):
# This function implements reader in PaddlePaddle.
# filename:Text that needs to be processed, string
# word_idx:dict
# n: The size of the sliding window
# Output:The reader in PaddlePaddle which is used to define the output data.
def reader():
with open(file_name) as f:
for l in f:
l = ['<s>'] + l.strip().split() + ['<e>']
if len(l) >=n:
l = [word_idx.get(w, UNK) for w in l]
for i in range(n, len(l) + 1):
yield tuple(l[i - n:i])
return reader
4. Configure parameter.
In the phase, it mainly includes the definition of each variable in the text preprocessing, the definition of the model hyperparameter, and the definition of the reader function.
# Define the the hyper-parameter embsize = 32 hiddensize = 256 N = 5
# Specify training and test text train_file_name='./train_zx.txt' test_file_name='./test_zx.txt'
# Build a dictionary
word_dict_train = build_dict(train_file_name, 20)
word_dict_test = build_dict(test_file_name, 10)
#word_dict=word_dict_train.items()+word_dict_test.items()
word_dict={}
word_dict.update(word_dict_train)
word_dict.update(word_dict_test)
UNK = word_dict['<unk>']
# Instantiate training and test reader train_reader = reader_creator(train_file_name, word_dict, N) test_reader = reader_creator(test_file_name, word_dict, N)
5.1 Define the functions used to save and load word dict and embedding table
def save_dict_and_embedding(word_dict, embeddings):
with open("word_dict", "w") as f:
for key in word_dict:
f.write(key + " " + str(word_dict[key]) + "\n")
with open("embedding_table", "w") as f:
numpy.savetxt(f, embeddings, delimiter=',', newline='\n')
def load_dict_and_embedding():
word_dict = dict()
with open("word_dict", "r") as f:
for line in f:
key, value = line.strip().split(" ")
word_dict[key] = int(value)
embeddings = numpy.loadtxt("embedding_table", delimiter=",")
return word_dict, embeddings
5.2 Define the network structure
Map the n−1n−1 words wt−n+1,...wt−1wt−n+1,...wt−1 before wtwt to a D-dimensional vector though matrix of dimention |V|×D|V|×D (D=32 in this example).
def wordemb(inlayer):
wordemb = paddle.layer.table_projection(
input=inlayer,
size=embsize,
param_attr=paddle.attr.Param(
name="_proj",
initial_std=0.001,
learning_rate=1,
l2_rate=0,
sparse_update=True))
return wordemb
5.3 Define name and type for input to data layer.
paddle.init(use_gpu=False, trainer_count=3)
dict_size = len(word_dict)
firstword = paddle.layer.data(
name="firstw", type=paddle.data_type.integer_value(dict_size))
secondword = paddle.layer.data(
name="secondw", type=paddle.data_type.integer_value(dict_size))
thirdword = paddle.layer.data(
name="thirdw", type=paddle.data_type.integer_value(dict_size))
fourthword = paddle.layer.data(
name="fourthw", type=paddle.data_type.integer_value(dict_size))
nextword = paddle.layer.data(
name="fifthw", type=paddle.data_type.integer_value(dict_size))
Efirst = wordemb(firstword)
Esecond = wordemb(secondword)
Ethird = wordemb(thirdword)
Efourth = wordemb(fourthword)
5.4 Concatenate n-1 word embedding vectors into a single feature vector.
contextemb = paddle.layer.concat(input=[Efirst, Esecond, Ethird, Efourth])
5.5 Make the feature vector go through a fully connected layer to output a hidden feature vector.
hidden1 = paddle.layer.fc(input=contextemb,
size=hiddensize,
act=paddle.activation.Sigmoid(),
layer_attr=paddle.attr.Extra(drop_rate=0.5),
bias_attr=paddle.attr.Param(learning_rate=2),
param_attr=paddle.attr.Param(
initial_std=1. / math.sqrt(embsize * 8),
learning_rate=1))
5.6 Make the Hidden feature vector go through another fully conected layer to turn into a
|V|
|V| dimensional vector. At the same time softmax will be applied to get the probability of each word being generated.
predictword = paddle.layer.fc(input=hidden1,
size=dict_size,
bias_attr=paddle.attr.Param(learning_rate=2),
act=paddle.activation.Softmax())
5.7 Define the cost function.
cost = paddle.layer.classification_cost(input=predictword, label=nextword)
5.8 Create parameter, optimizer and trainer.
parameters = paddle.parameters.create(cost)
adagrad = paddle.optimizer.AdaGrad(
learning_rate=3e-3,
regularization=paddle.optimizer.L2Regularization(8e-4))
trainer = paddle.trainer.SGD(cost, parameters, adagrad)
5.9 Define event handler.
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "Pass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
if isinstance(event, paddle.event.EndPass):
result = trainer.test(
paddle.batch(
test_reader, 32))
print "Pass %d, Testing metrics %s" % (event.pass_id, result.metrics)
with open("model_c_%d.tar"%event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
6. Start the training.
trainer.train(
paddle.batch(train_reader, 32),
num_passes=100,
event_handler=event_handler)
7. Save word dict and embedding table.¶
After training, we can save the word dict and embedding table for the future usage.
# save word dict and embedding table
import numpy
embeddings = parameters.get("_proj").reshape(len(word_dict), embsize)
save_dict_and_embedding(word_dict, embeddings)
8. Model Application.¶
After the model is trained, we can load the saved model parameters and use it for other models. We can also use the parameters in various applications.
8.1 Modifying Word Vector.
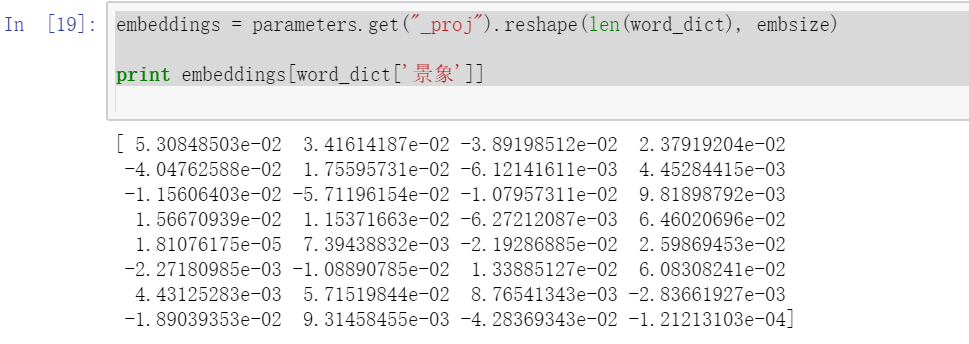
Word vectors (embeddings) that we get is a numpy array. We can modify this array and set it back to parameters.
embeddings = parameters.get("_proj").reshape(len(word_dict), embsize)
print embeddings[word_dict['景象']]
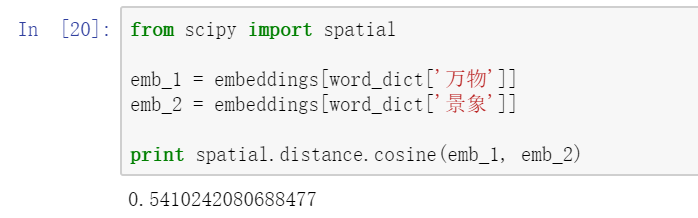
8.2 Calculating Cosine Similarity.
Cosine similarity is one way of quantifying the similarity between two vectors. The range of result is [−1,1][−1,1] . The bigger the value, the similar two vectors are:
from scipy import spatial emb_1 = embeddings[word_dict['万物']] emb_2 = embeddings[word_dict['景象']] print spatial.distance.cosine(emb_1, emb_2)